






 文章探讨了主流的大模型微调方法,如Freeze、P-Tuning和LoRA,尤其关注LoRA在减少参数量的同时保持良好性能。LoRA通过增加低秩矩阵进行训练,适用于资源有限的情况。实验结果显示,LoRA在效果和速度上优于Freeze和部分P-Tuning策略。
文章探讨了主流的大模型微调方法,如Freeze、P-Tuning和LoRA,尤其关注LoRA在减少参数量的同时保持良好性能。LoRA通过增加低秩矩阵进行训练,适用于资源有限的情况。实验结果显示,LoRA在效果和速度上优于Freeze和部分P-Tuning策略。
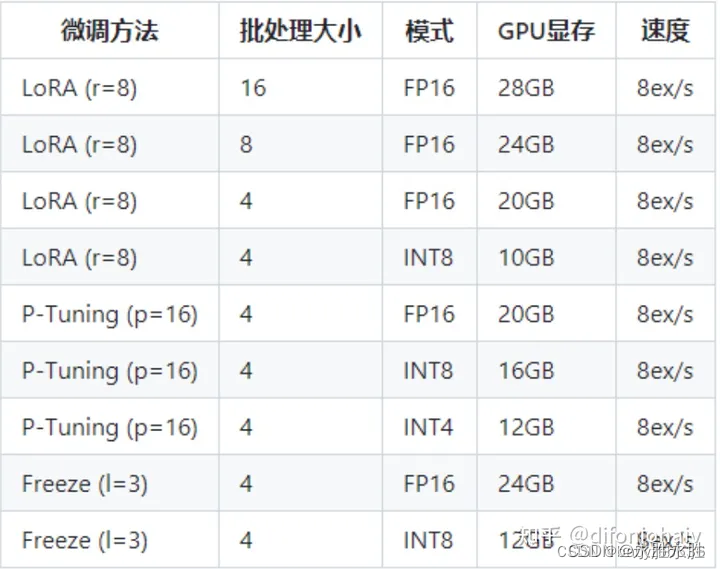
目前主流对大模型进行微调方法有三种:Freeze方法、P-Tuning方法和Lora方法
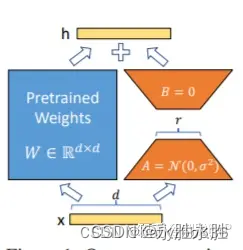
LoRA: 在大型语言模型上对指定参数(权重矩阵)并行增加额外的低秩矩阵,并在模型训练过程中,仅训练额外增加的并行低秩矩阵的参数,冻结其他参数。 当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量也就很小。在下游任务tuning时,仅须训练很小的参数,但能获取较好的表现结果。
LoRA: 在大型语言模型上对指定参数(权重矩阵)并行增加额外的低秩矩阵,并在模型训练过程中,仅训练额外增加的并行低秩矩阵的参数,冻结其他参数。 当“秩值”远小于原始参数维度时,新增的低秩矩阵参数量也就很小。在下游任务tuning时,仅须训练很小的参数,但能获取较好的表现结果。
下载代码
git clone https://github.com/liucongg/ChatGLM-Finetuning
环境配置
cpm_kernels==1.0.11
deepspeed==0.9.0
numpy==1.24.2
peft==0.3.0
sentencepiece==0.1.96
tensorboard==2.11.0
tensorflow==2.13.0
torch==1.13.1+cu116
tqdm==4.64.1
transformers==4.27.1
(1)、ChatGLM单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
(2)、ChatGLM四卡训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm
(3)、ChatGLM2单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
(4)、ChatGLM2四卡训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type lora \
--lora_dim 16 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_module_name "query_key_value,dense_h_to_4h,dense_4h_to_h,dense" \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--output_dir ./output-glm2
(5)、耗费显存资源占用对比—LoRA方法:对比ChaGLM和ChaGLM2
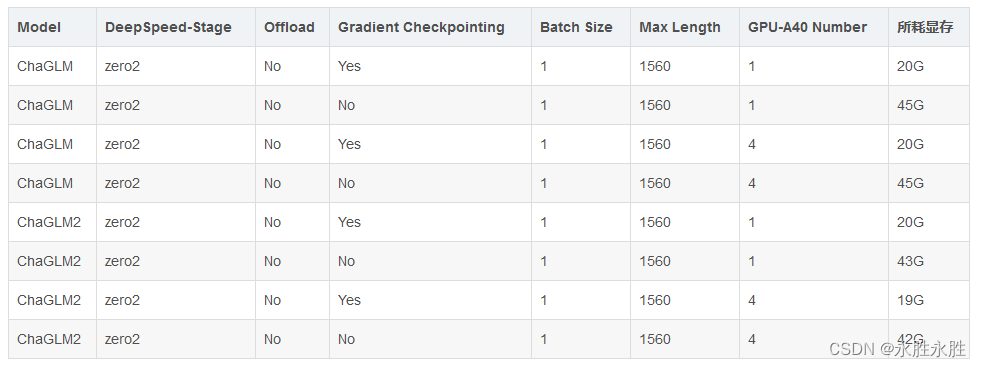 注意:Lora方法在模型保存时仅保存了Lora训练参数,因此在模型预测时需要将模型参数进行合并,具体参考merge_lora.py。
注意:Lora方法在模型保存时仅保存了Lora训练参数,因此在模型预测时需要将模型参数进行合并,具体参考merge_lora.py。
四种微调资源耗费比较

结果分析:
- 效果为PT>Freeze>Lora>PT-Only-Embedding;
- 速度为PT-Only-Embedding>Lora>Freeze>PT;
- PT-Only-Embedding效果很不理想,发现在训练时,最后的loss仅能收敛到2.几,而其他机制可以收敛到0.几。分析原因为,输出内容形式与原有语言模型任务相差很大,仅增加额外Embedding参数,不足以改变复杂的下游任务;
- 由于大模型微调都采用大量instruction进行模型训练,仅采用单一的指令进行微调时,对原来其他的指令影响不大,因此并没导致原来模型的能力丧失;


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









