



 本周深入学习了attention机制,了解了其本质思想、计算过程和self attention模型,强调self attention在捕捉句子长距离依赖和提高计算并行性上的优势。此外,阅读了一篇关于Transformer模型的论文,该模型仅依赖注意力机制,实现翻译任务的高效并行训练,性能优于传统递归和卷积架构。
本周深入学习了attention机制,了解了其本质思想、计算过程和self attention模型,强调self attention在捕捉句子长距离依赖和提高计算并行性上的优势。此外,阅读了一篇关于Transformer模型的论文,该模型仅依赖注意力机制,实现翻译任务的高效并行训练,性能优于传统递归和卷积架构。
目录
摘要
This week, I learned the essential idea of the attention mechanism, the computational process, the concept of the self attention model and its advantages. The self attention model makes it easier to capture long-distance interdependent features in sentences and increases computational parallelism; in addition, I read a paper on the attention mechanism of natural language processing, and the Transformer model proposed in the paper makes the training speed significantly faster.
本周,我学习了attention机制的本质思想、计算过程以及self attention模型的概念及其优点,self attention模型使得捕获句子中长距离的相互依赖的特征更加容易,也增加了计算的并行性;另外,我阅读了一篇有关自然语言处理注意力机制的论文,文章提出的Transformer模型使得训练速度明显提升。
深度学习
1、attention机制的本质思想

2、attention机制的具体计算过程
(1)根据Query和Key计算两者的相关性
可以引入不同函数和计算机制,根据Query和Key,计算两者的相似性或者相关性,常见方法:

(2)对1的原始分值进行softmax归一化处理


3、self attention模型
self attention 可以捕获同一个句子中单词之间的一些句法特征(如下图展示的有一定距离的短语结构)或语义特征(如下图展示的its的指代对象Law):

query:句中的每个单词(例如making)
key/value:整句话中的每个单词
权重系数含义:句中哪个词跟我这个词关联大
优点:
1、引入self attention后会更容易捕获句子中长距离的相互依赖的特征:
因为如果是RNN或者LSTM,【需要按照次序序列计算】,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效信息被稀释,有效捕获的可能性越小;Self Attention不需要依赖次序序列计算Self Attention在计算过程中会直接将句子中【任意两个单词的联系通过一个计算步骤直接联系起来】,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。
2、self attention对于增加计算的并行性也有直接帮助作用。
文献阅读
1、题目
2、摘要
占主导地位的序列转导模型是基于复杂的递归或卷积神经网络,包括一个编码器和一个解码器。性能最好的模型还通过注意机制将编码器和解码器连接起来。作者提出了一个新的简单的网络结构–Transformer,它只基于注意力机制,完全不需要递归和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更胜一筹,同时更容易并行化,所需的训练时间也大大减少。作者的模型在WMT 2014英德翻译任务中达到了28.4 BLEU,比现有的最佳结果(包括合集)提高了2 BLEU以上。
3、介绍
3.1 背景
递归神经网络,特别是长短时记忆和门控递归神经网络,已经被牢固地确立为序列建模和转换问题的最先进方法,如语言建模和机器翻译。
3.2 存在问题
1、虽然通过因式分解技巧和条件计算在计算效率方面取得了重大改进,同时在后者的情况下也提高了模型性能,但是,顺序计算的基本约束仍然存在。
2、注意机制已经成为各种任务中引人注目的序列建模和转换模型的一个组成部分,允许对依赖关系进行建模,而不考虑它们在输入或输出序列中的距离,但是,除了少数情况外,这种注意机制是与递归网络结合使用的。
3.3 解决方案
作者提出了Transformer,这是一个避免递归的模型结构,而完全依靠注意力机制来得出输入和输出之间的全局依赖关系。Transformer允许更多的并行化,并且在8个P100 GPU上经过短短12小时的训练,就能达到翻译质量的新水平。
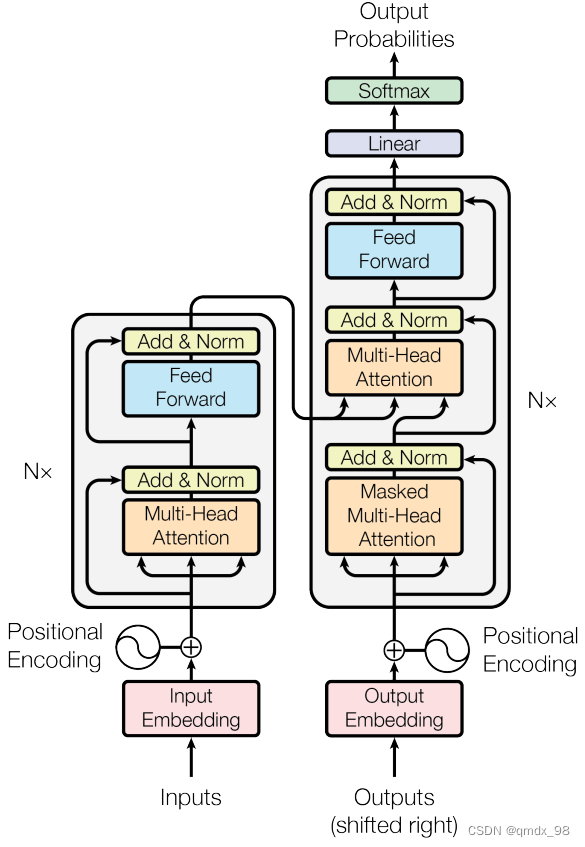
4、模型介绍
4.1模型结构
Transformer模型有一个编码器-解码器结构,编码器将输入的符号表征序列(x1, …, xn)映射为连续表征序列z=(z1, …, zn)。给定z后,解码器每次生成一个元素的符号输出序列(y1, …, ym)。在每一步,该模型都是自动回归的,在生成下一步时,消耗先前生成的符号作为额外输入。
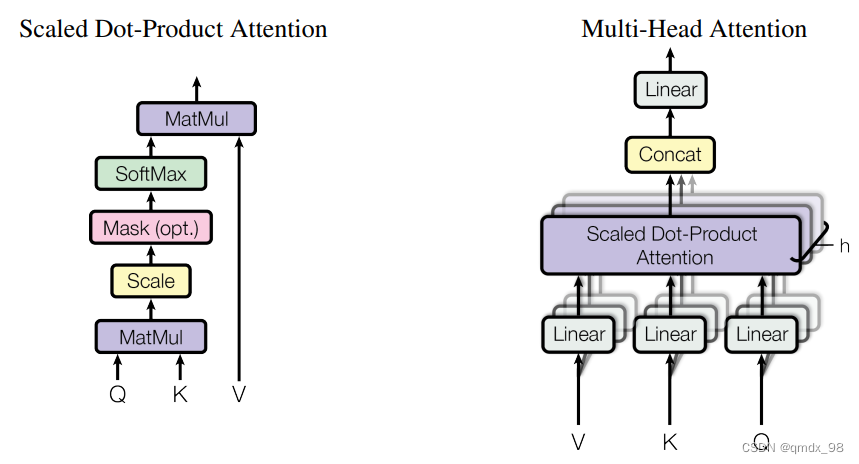
(left) Scaled Dot-Product Attention. (right) Multi-Head Attention.
4.2 位置编码
由于Transformer模型不包含递归和卷积,为了使模型能够利用序列的顺序,必须注入一些关于序列中标记的相对或绝对位置的信息。为此,在编码器和解码器堆栈的底部为输入嵌入添加 “位置编码”。位置编码与嵌入具有相同的维度dmodel,因此这两者可以相加。有很多位置编码的选择,有学习的,也有固定的。这项工作中用不同频率的正弦和余弦函数:
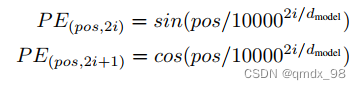
4.3 不同层类型组成的网络比较
由不同层类型组成的网络中任何两个输入和输出位置之间的最大路径长度比较:

不同层类型的最大路径长度、每层复杂度和最小序列操作数。n是序列长度,d是表示维度,k是卷积的内核大小,r是限制性自我关注中的邻域大小。
5、实验
5.1 数据集
模型在标准的WMT 2014英德数据集上进行训练,该数据集包括大约450万个句子对。句子使用字节对编码,它有一个共享的源-目标词汇,大约有37000个标点。对于英语-法语,作者使用了明显更大的WMT 2014英语-法语数据集,包括3600万个句子,并将代币分成32000个词件词汇。句子对按照大致的序列长度被分到一起。每个训练批包含一组句子对,大约有25000个源标记和25000个目标标记。
5.2 实验结果
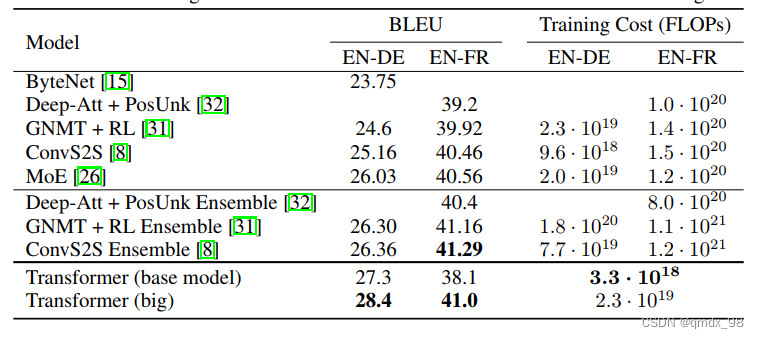
在英译德和英译法的newstest2014测试中,Transformer取得了比以前最先进的模型更好的BLEU分数,而培训成本却只有一小部分。
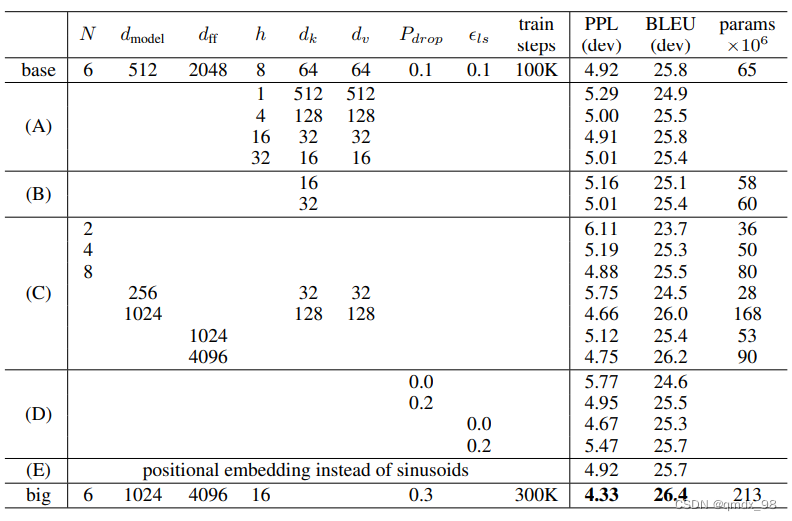
为了评估Transformer不同组件的重要性,作者以不同的方式改变基础模型,在开发集newstest2013上测量英德翻译的性能变化。使用了波束搜索,但没有使用检查点平均法。如下表,在表3行(A)中,我们改变了注意力头的数量以及注意力键和值的维度,保持计算量不变。虽然单头关注比最佳设置差0.9 BLEU,但质量也随着头数的增加而下降。
6、本文贡献及展望
6.1 贡献
提出了Transformer,这是第一个完全基于注意力的序列转换模型,用多头的自我注意力取代了编码器-解码器架构中最常用的递归层。对于翻译任务,Transformer的训练速度明显快于基于递归或卷积层的架构。
6.2 展望
计划将Transformer扩展到涉及文本以外的输入和输出模式的问题,并研究局部的、有限的注意力机制,以有效地处理大型输入和输出,如图像、音频和视频,使生成的顺序性降低。
总结
本周学习了attention机制以及self attention模型,self attention模型的引入使得捕获句子中长距离的相互依赖的特征更加容易,也增加了计算的并行性,下周将继续学习self attention以及SVM。

















 5516
5516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









