



人工智能学习76-Yolo模型构建—快手视频
人工智能学习77-Yolo模型构建—快手视频
Yolo网络模型
Yolo网络设计两个网络模型,一个模型是用于预测的,另一个模型是用于训练的,两个模型都使用相同的网络结构,不同的地方是用于训练的模型中最后添加自定义的损失函数层,用于评价网络预测输出是否拟合真实值。
yolo_model.py
from keras.layers import Concatenate, Input, Lambda, UpSampling2D
from keras.models import Model
from utils import compose
from darknet import DarknetConv2D, DarknetConv2D_BN_Leaky, darknet_body
from yolo_training import yolo_loss
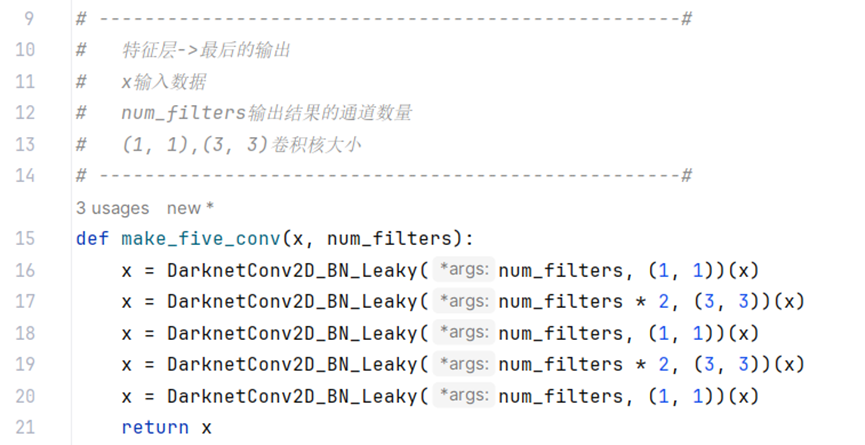
# ---------------------------------------------------#
# 特征层->最后的输出
# x输入数据
# num_filters输出结果的通道数量
# (1, 1),(3, 3)卷积核大小
# ---------------------------------------------------#
def make_five_conv(x, num_filters):
x = DarknetConv2D_BN_Leaky(num_filters, (1, 1))(x)
x = DarknetConv2D_BN_Leaky(num_filters * 2, (3, 3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1, 1))(x)
x = DarknetConv2D_BN_Leaky(num_filters * 2, (3, 3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1, 1))(x)
return x
# ---------------------------------------------------#
# 特征层->最后的输出
# x输入数据
# num_filters,out_filters输出结果的通道数量
# (1, 1),(3, 3)卷积核大小
# ---------------------------------------------------#
def make_yolo_head(x, num_filters, out_filters):
y = DarknetConv2D_BN_Leaky(num_filters * 2, (3, 3))(x)
y = DarknetConv2D(out_filters, (1, 1))(y)
return y
# ---------------------------------------------------#
# FPN网络的构建,并且获得预测结果
# input_shape输入数据尺寸
# anchors_mask掩码
# num_classes分类数量
# ---------------------------------------------------#
def get_yolo_model(input_shape, anchors_mask, num_classes):
inputs = Input(input_shape)
# inputs=: Tensor("input_1:0", shape=(?, ?, ?, 3), dtype=float32)
# ---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# C3 为 52,52,256
# C4 为 26,26,512
# C5 为 13,13,1024
# ---------------------------------------------------#
C3, C4, C5 = darknet_body(inputs)
# C3 = Tensor("add_11/add:0", shape=(?, ?, ?, 256), dtype=float32) 尺寸(52,52,256)
# C4 = Tensor("add_19/add:0", shape=(?, ?, ?, 512), dtype=float32) 尺寸(26,26,512)
# C5 = Tensor("add_23/add:0", shape=(?, ?, ?, 1024), dtype=float32) 尺寸(13,13,1024)
# ---------------------------------------------------#
# make_five_conv做了5次卷积操作
# 第一个特征层
# y1=(batch_size,13,13,3,85)
# ---------------------------------------------------#
# 通道数首先从1024->512,再从512->1024,再从1024->512,再从512->1024,最后从1024->512
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
x = make_five_conv(C5, 512) #尺寸(13,13,512)
# x = Tensor("leaky_re_lu_57/LeakyRelu:0", shape=(?, ?, ?, 512), dtype=float32)
P5 = make_yolo_head(x, 512, len(anchors_mask[0]) * (num_classes + 5))
# P5 = Tensor("conv2d_59/BiasAdd:0", shape=(?, ?, ?, 255), dtype=float32) P5尺寸(13,13,255) num_classes=80
# DarknetConv2D_BN_Leaky做了1次卷积
# 首先从512->256,再执行UpSampling2D(2)从13,13,256 -> 26,26,256,
# 返回级联函数形式,UpSampling2D(2)((DarknetConv2D(256, (1, 1))))
x = compose(DarknetConv2D_BN_Leaky(256, (1, 1)), UpSampling2D(2))(x) # 合并两个方法
# 合并两层数据x为26,26,256,C4为26,26,512,通道数相加为768
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, C4]) # 合并两层数据 尺寸(26,26,768)
# ---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,26,26,3,85)
# ---------------------------------------------------#
# make_five_conv做了5次卷积操作
# 通道数首先从768->256,再从256->512,再从512->256,再从256->512,最后从512->256
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
x = make_five_conv(x, 256) #尺寸(26,26,256)
P4 = make_yolo_head(x, 256, len(anchors_mask[1]) * (num_classes + 5))
# P4 = Tensor("conv2d_67/BiasAdd:0", shape=(?, ?, ?, 255), dtype=float32) P4尺寸(26,26,255) num_classes=80
# DarknetConv2D_BN_Leaky做了1次卷积
# 首先从256->128,再执行UpSampling2D(2)从26,26,128 -> 52,52,128,
x = compose(DarknetConv2D_BN_Leaky(128, (1, 1)), UpSampling2D(2))(x)
# 合并两层数据x为52,52,128,C3为52,52,256,通道数相加为384
# 52,52,128 + 52,52,256 -> 52,52,384
x = Concatenate()([x, C3]) # 合并两层数据 尺寸(52,52,384)
# ---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,52,52,3,85)
# ---------------------------------------------------#
# make_five_conv做了5次卷积操作
# 通道数首先从384->128,再从128->256,再从256->128,再从128->256,最后从256->128
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
x = make_five_conv(x, 128) #尺寸(52,52,128)
P3 = make_yolo_head(x, 128, len(anchors_mask[2]) * (num_classes + 5))
# P3 = Tensor("conv2d_75/BiasAdd:0", shape=(?, ?, ?, 255), dtype=float32) P3尺寸(52,52,255) num_classes=80
# P5 为 【batch,13,13,255】,P4为 【batch,26,26,255】,P3为 【batch,52,52,255】
# 定义模型输入为inputs,输出为[P5, P4, P3]张量
model = Model(inputs, [P5, P4, P3])
return model
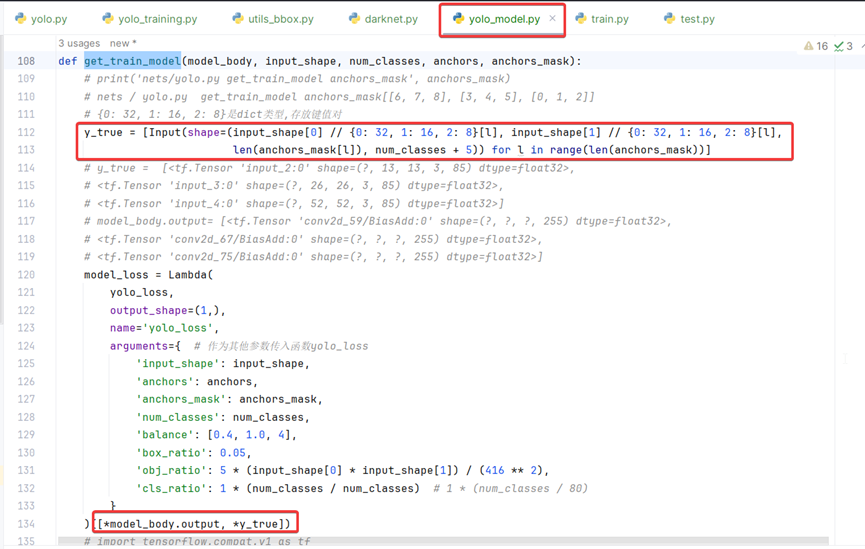
def get_train_model(model_body, input_shape, num_classes, anchors, anchors_mask):
# print('nets/yolo.py get_train_model anchors_mask', anchors_mask)
# nets / yolo.py get_train_model anchors_mask[[6, 7, 8], [3, 4, 5], [0, 1, 2]]
# {0: 32, 1: 16, 2: 8}是dict类型,存放键值对
y_true = [Input(shape=(input_shape[0] // {0: 32, 1: 16, 2: 8}[l], input_shape[1] // {0: 32, 1: 16, 2: 8}[l],
len(anchors_mask[l]), num_classes + 5)) for l in range(len(anchors_mask))]
# y_true = [<tf.Tensor 'input_2:0' shape=(?, 13, 13, 3, 85) dtype=float32>,
# <tf.Tensor 'input_3:0' shape=(?, 26, 26, 3, 85) dtype=float32>,
# <tf.Tensor 'input_4:0' shape=(?, 52, 52, 3, 85) dtype=float32>]
# model_body.output= [<tf.Tensor 'conv2d_59/BiasAdd:0' shape=(?, ?, ?, 255) dtype=float32>,
# <tf.Tensor 'conv2d_67/BiasAdd:0' shape=(?, ?, ?, 255) dtype=float32>,
# <tf.Tensor 'conv2d_75/BiasAdd:0' shape=(?, ?, ?, 255) dtype=float32>]
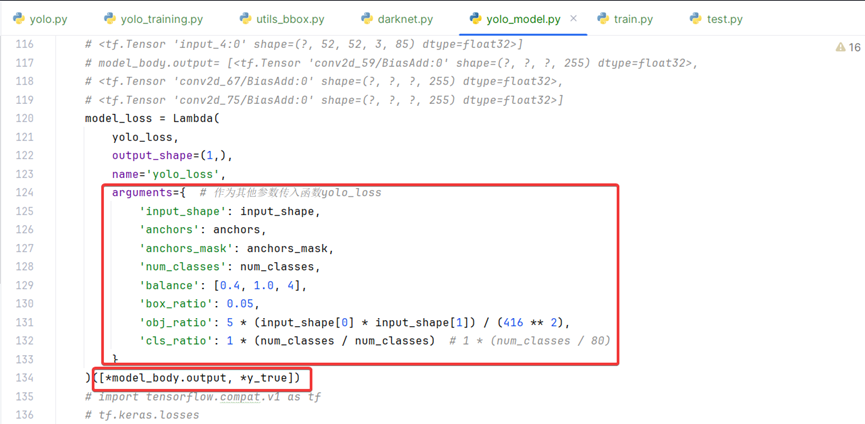
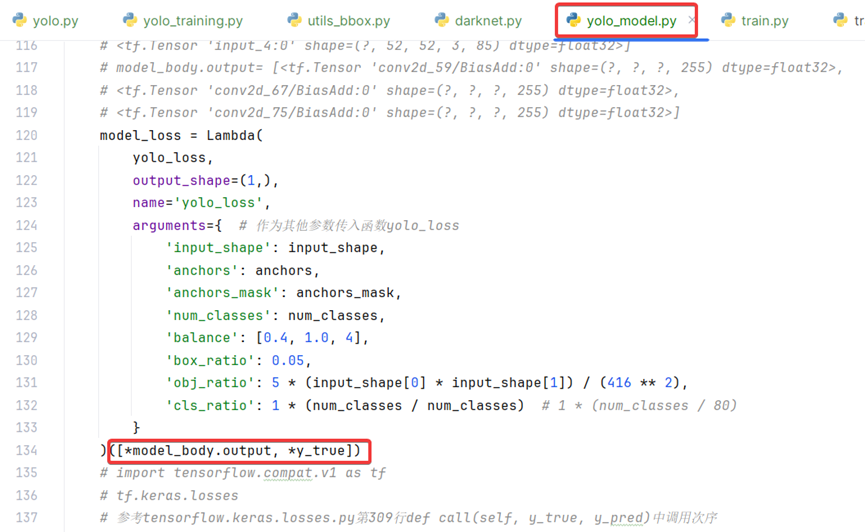
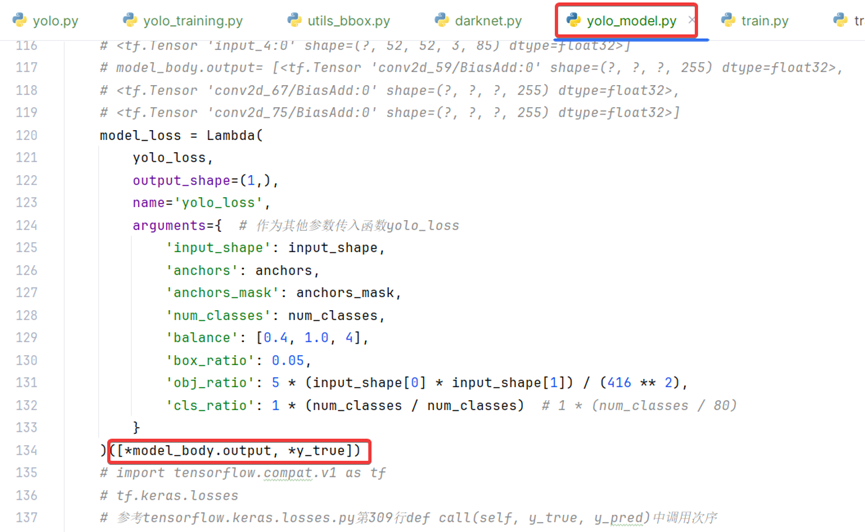
model_loss = Lambda(
yolo_loss,
output_shape=(1,),
name='yolo_loss',
arguments={ # 作为其他参数传入函数yolo_loss
'input_shape': input_shape,
'anchors': anchors,
'anchors_mask': anchors_mask,
'num_classes': num_classes,
'balance': [0.4, 1.0, 4],
'box_ratio': 0.05,
'obj_ratio': 5 * (input_shape[0] * input_shape[1]) / (416 ** 2),
'cls_ratio': 1 * (num_classes / num_classes) # 1 * (num_classes / 80)
}
)([*model_body.output, *y_true])
# import tensorflow.compat.v1 as tf
# tf.keras.losses
# 参考tensorflow.keras.losses.py第309行def call(self, y_true, y_pred)中调用次序
# 参数[*model_body.output, *y_true]作为Lamba封装函数yolo_loss的调用参数,*代表合并可迭代对象,将model_body.output和y_true打包成新的列表
# model_loss使用Lambda封装yolo_loss损失函数作为网络最后一层
# inputs=[model_body.input, *y_true]作为输入数据,将input与y_true连接作为输入 outputs=model_loss作为最后输出一层
# 参考keras.engine.training.py 第1951行 fit_generator --> 第2228行 self.train_on_batch -->第1883行self.train_function(ins) 将x,y连接
print('1...[*model_body.output, *y_true]=', ([*model_body.output, *y_true]))
# 参考keras.engine.topology.py 第1521行 合并model.input与y_true
model = Model(inputs=[model_body.input, *y_true], outputs=model_loss)
# model.summary()
# 参数[model_body.input, *y_true]代表将model_body.input和y_true打包成列表
# model.type=<class 'keras.engine.training.Model'> 参数[model_body.input, *y_true]是合并model_body.input和*y_true作为Model Input
# model_loss = Tensor("yolo_loss/add_29:0", shape=(), dtype=float32) 返回一个浮点标量,作为Model Output
return model
代码解释部分
方法make_five_conv第15行


from yolo_model import make_five_conv
nd = np.random.random(10*13*13*1024) #第一维数值10为数量维度
C5 = tf.convert_to_tensor(nd.reshape(-1, 13, 13, 1024))
x = make_five_conv(C5, 512) #尺寸(13,13,512)
print(x.shape)
(10, 13, 13, 512)
方法get_yolo_model第67行
P5 = make_yolo_head(x, 512, len(anchors_mask[0]) * (num_classes + 5))
其中512是输入张量最后一维,可以认为是输入数据的通道数量,len(anchors_mask[0]) * (num_classes + 5)是输出维度的通道数,anchors_mask[0]代表第0个特征图的3个先验框,num_classes是物种数量,数字5代表预测框x,y,w,h,confidence五个预测数量。
当num_classes=80时,P5的尺寸为(n,13,13,255),其中255=3*(80+5)。
方法get_yolo_model第72行

方法UpSampling2D是 TensorFlow 中的一个层,用于图像数据上采样,增加图像的高度和宽度。
x = compose(DarknetConv2D_BN_Leaky(256, (1, 1)), UpSampling2D(2))(x)
将张量x首先转化为(13,13,256)再经过UpSampling2D转化为(26,26,512)。
第75行中x = Concatenate()([x, C4]),是将上层卷积残差数据与特征图C4合并,避免特征数据丢失。
例程:
from yolo_model import make_five_conv
from utils import compose
from darknet import DarknetConv2D, DarknetConv2D_BN_Leaky, darknet_body
from keras.layers import Concatenate, Input, Lambda, UpSampling2D
nd = np.random.random(10*13*13*1024)
C5 = tf.convert_to_tensor(nd.reshape(-1, 13, 13, 1024))
x = make_five_conv(C5, 512) #尺寸(13,13,512)
x = compose(DarknetConv2D_BN_Leaky(256, (1, 1)), UpSampling2D(2))(x) # 合并两个方法
print('x1===', x.shape)
nd = np.random.random(10*26*26*512)
C4 = tf.convert_to_tensor(nd.reshape(-1, 26, 26, 512), dtype=tf.float32)
# 合并两层数据x为26,26,256,C4为26,26,512,通道数相加为768
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, C4]) # 合并两层数据 尺寸(26,26,768)
print('x2===', x.shape)
x1=== (10, 26, 26, 256)
x2=== (10, 26, 26, 768)
方法get_yolo_model第104行

根据构建张量P5、P4、P3作为模型输出,inputs作为模型输入,构造网络预测模型,模型三个特征层输出张量分别为(batch,13,13,255),(batch,26,26,255),(batch,52,52,255)。
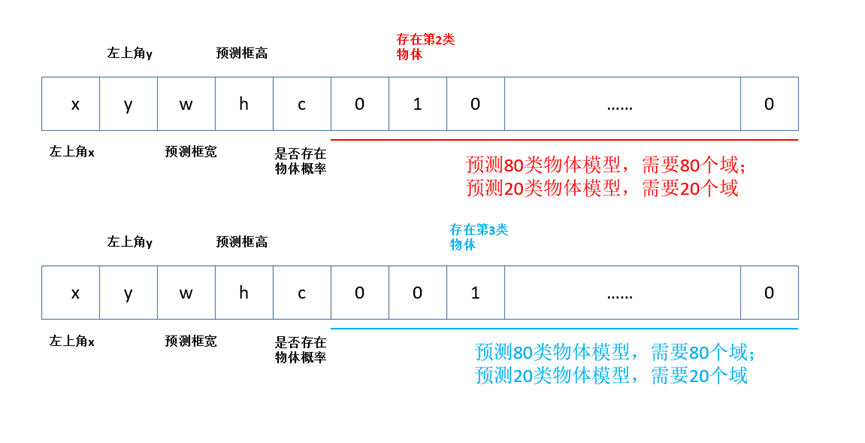
也就是每个特征图的每个方格都包含255/3=85个数值,分别代表预测框x,y,w,h,confidence,0,0,1……0,最后80个数值为物种分类的one-hot编码。
方法get_train_model第108行
获取YoloV3网络训练模型,YoloV3损失函数是多目标评价的,不像图片分类只评价一个目标即可(图片上的物体是哪种物体),YoloV3损失函数需要评价预测框坐标是否准确、预测框宽与高是否准确、预测框中是否存在物体、存在物体的种类,一共需要评价4个目标。
YoloV3将损失函数封装为Lambda层作为网络最后一层,最后一层传入参数为model.output和y_true,损失函数需要根据model.output和y_true(真实标签数据)计算网络拟合损失,使用梯度下降法调整网络权重和偏置。
损失函数定义输入参数:
在网络模型编译时,指定损失参数为yolo_loss,在train.py文件中定义。
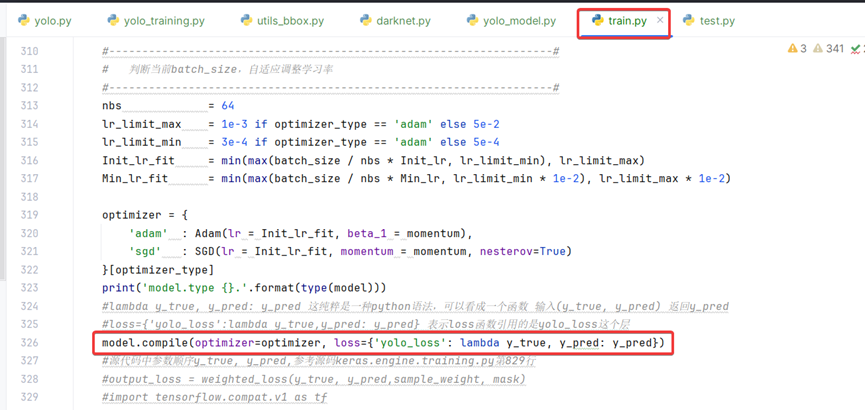
如何传递真实标签数据y_true
在方法get_train_model第112行定义了y_true张量,在134行作为输入参数传递到Lambda层。
YoloV3网络训练通过train.py中model.fit_generator()方法,如图:
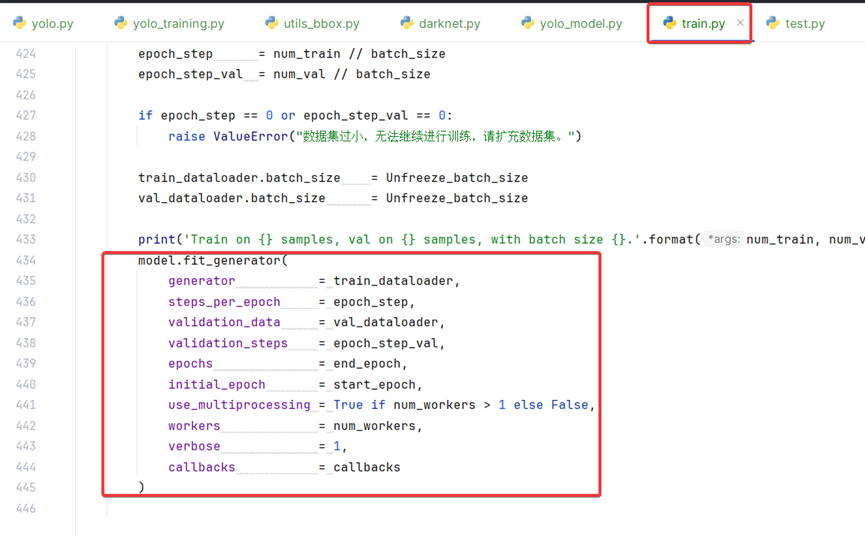
其中train_dataloader包括训练图片数据和y_true真实标签数据,y_true标签数据如何传递到Lambda的输入参数y_true中的。
答案是通过隐藏在Keras底层类库完成的参数传递。
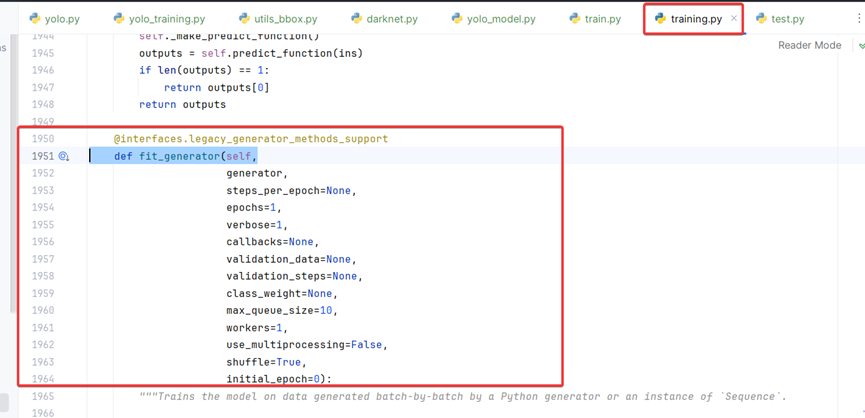
1、keras.engine.training.py 第1951行
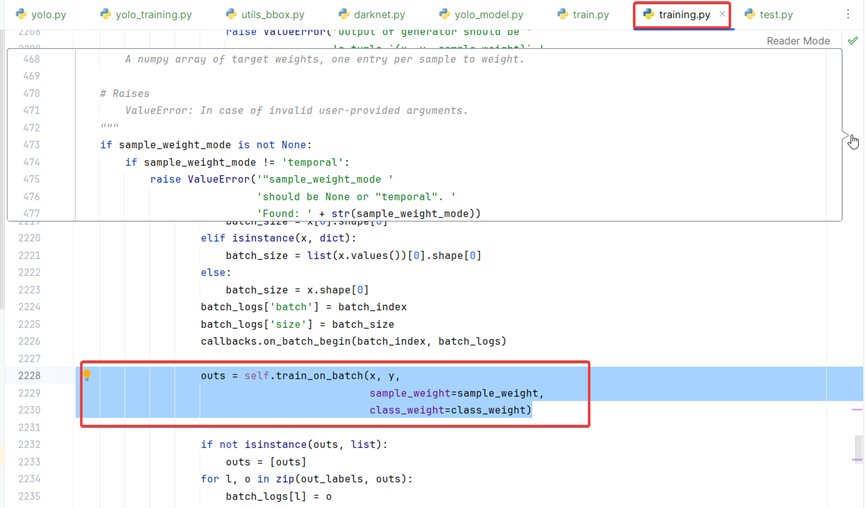
2、keras.engine.training.py 第2228行
3、keras.engine.training.py 第1878行
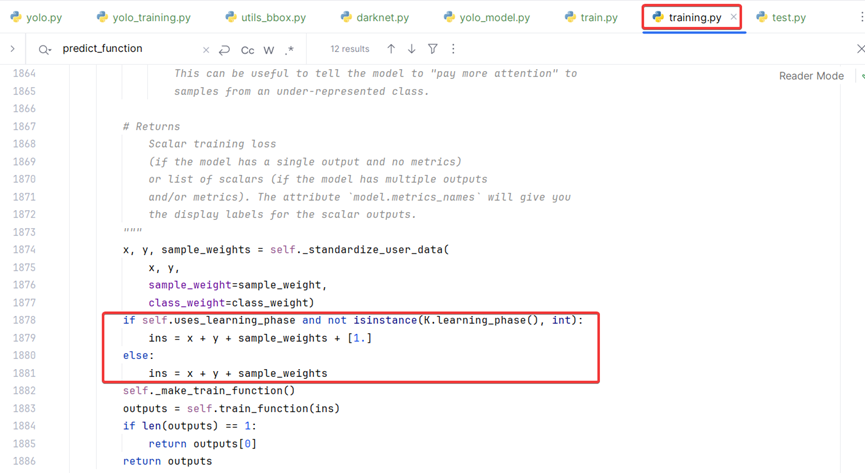
将x与y作为List连接在一起,与模型输入参数([*model_body.output, *y_true])一致。
**
**



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









