



“调参侠”必看!手把手教你用代码调教CNN模型,附“炼丹”避坑指南⚗️✨
🔍 一、CNN参数体系全景图
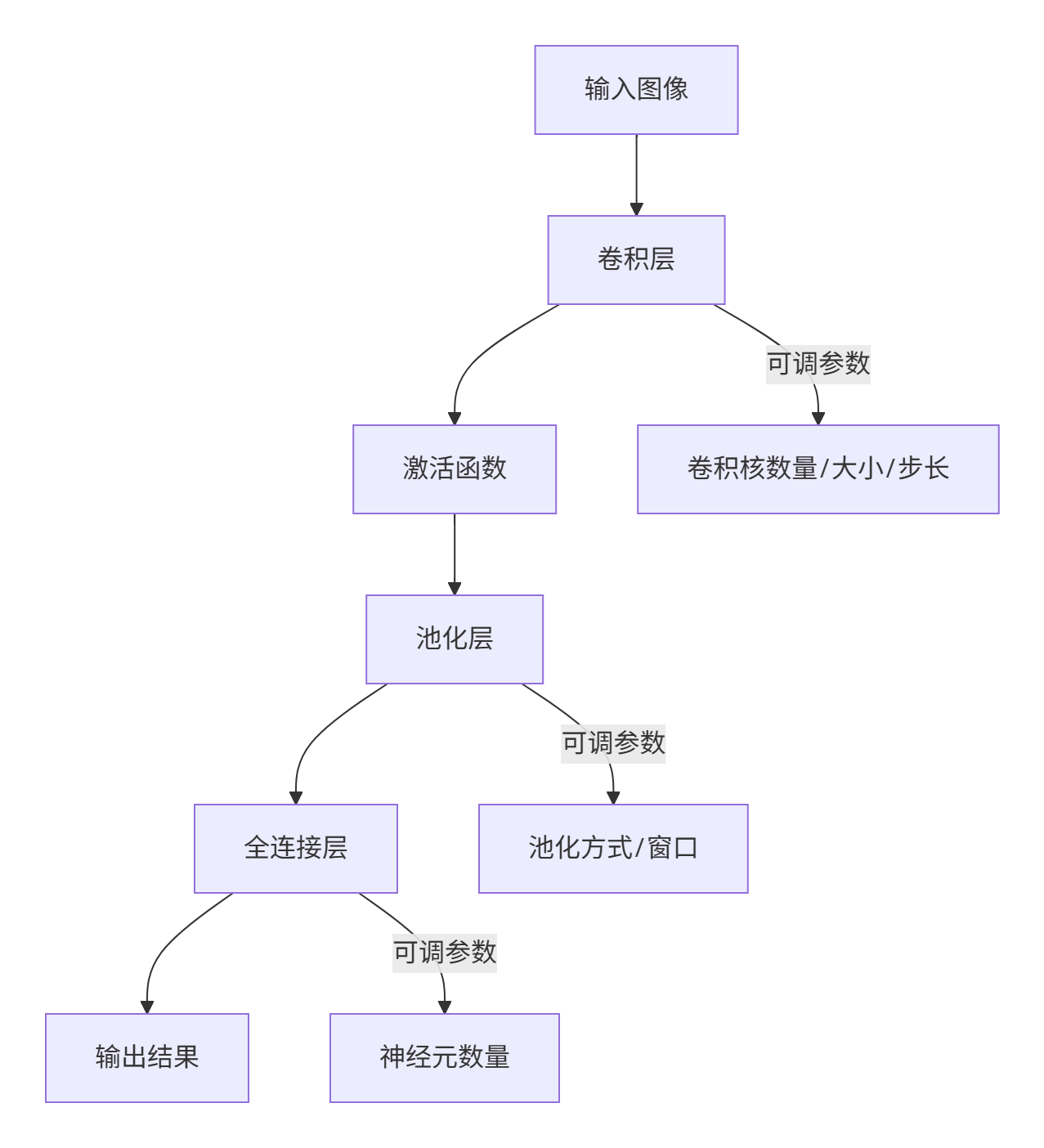
一句话秒懂CNN:
CNN = 特征提取器(卷积+激活+池化) + 分类器(全连接) + 结构设计(深度/宽度)
⚙️ 二、核心参数详解与实战设置
1. 卷积层:核心特征提取器
(1) 卷积核数量(Filters)
- 作用:决定输出特征图的通道数,数量越多模型“视力”越好👀
- 设置原则:
- 浅层少(如16/32),深层多(如128/256),像金字塔递增⬆️
- 典型配置:
Conv1:32 → Conv2:64 → Conv3:128 - 代码示例:
# PyTorch设置:输入通道3,输出通道64(即64个卷积核) nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3)
(2) 卷积核大小(Kernel Size)
- 黄金法则:3×3是业界标配!小核更高效,大核易过拟合
尺寸 优势 适用场景 1×1 跨通道信息融合,减少计算量 瓶颈层 3×3 平衡感受野和计算效率✅ 绝大多数卷积层 5×5+ 捕捉大范围特征 浅层或特定任务
💡 小提示:为什么3×3是黄金尺寸?
两个3×3卷积堆叠 ≈ 一个5×5卷积的感受野,但参数少44%!
参数计算:5x5=25 vs 3x3+3x3=18 → 性价比之王
(3) 步长(Stride):特征图的“压缩倍率”
- 计算公式:
输出尺寸 = (输入尺寸 + 2×Padding - 卷积核尺寸) / Stride + 1
- 实战策略:
- 常规特征提取:Stride=1(保留细节)
- 快速降维:Stride=2(替代池化)
# 步长为2的快速下采样卷积 nn.Conv2d(64, 128, kernel_size=3, stride=2) # 输出尺寸减半!
(4) Padding:图像边缘的“安全气囊”
- 两种模式:
Valid:不填充 → 输出尺寸变小Same:填充使输入输出尺寸一致✨
- 设置技巧:
# 3x3核填1,5x5核填2 padding = (kernel_size - 1) // 2
⚡ 2. 激活函数:神经网络的“开关电路”
| 函数 | 公式 | 优点 | 缺点 | 代码调用 |
|---|---|---|---|---|
| ReLU | max(0, x) | 计算快、缓解梯度消失✅ | 神经元“死亡” | nn.ReLU() |
| LeakyReLU | max(0.01x, x) | 解决死亡问题 | 参数略多 | nn.LeakyReLU(0.01) |
| Sigmoid | 1/(1+e^{-x}) | 输出(0,1)适合概率 | 梯度消失⚠️ | nn.Sigmoid() |
90%场景用ReLU就对了!
ReLU:深度学习的“万金油”💊,Sigmoid:输出层的“概率转换器”🎯
nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU() # 紧贴卷积层后
)📉 3. 池化层:信息浓缩的“蒸馏器”
(1) 池化方式二选一:
| 类型 | 操作 | 特点 | 代码 |
|---|---|---|---|
| MaxPool | 取窗口最大值 | 保留纹理特征 ✅ | nn.MaxPool2d(2) |
| AvgPool | 取窗口平均值 | 平滑背景,抗噪性强 | nn.AvgPool2d(2) |
(2) 关键参数设定:
nn.MaxPool2d(kernel_size=2, stride=2) # 最常用:2x2窗口,步长2| 参数 | 推荐值 | 作用 |
|---|---|---|
| kernel_size | 2或3 | 降维比例(通常减半) |
| stride | =kernel_size | 避免重叠,加速计算 |
⚠️ 注意:池化后通道数不变,只缩小宽高! 例如:输入14x14x64→ MaxPool(2x2) → 输出7x7x64
🧩 4. 全连接层:特征“分类决策室”
- 参数巨兽:一层的参数量可达百万级!
- 减少技巧:
# 全局平均池化替代全连接(减少90%参数!) nn.Sequential( nn.AdaptiveAvgPool2d((1,1)), # 输出[B, C, 1, 1] nn.Flatten() # 直接得到C维向量 ) - 经典结构:
nn.Sequential( nn.Flatten(), nn.Linear(256 * 7 * 7, 1024), # 输入=展平后的特征 nn.ReLU(), nn.Dropout(0.5), # 防过拟合 nn.Linear(1024, 10) # 输出10分类 )💥 全连接层参数量计算:
输入256 * 7 * 7=12544→ 输出1024
参数量 =12544 * 1024 + 1024 ≈ 1280万!
🏗️ 5. 网络深度与宽度:模型的“骨架设计”
| 网络类型 | 深度示例 | 宽度策略 | 适用设备 |
|---|---|---|---|
| 轻量化模型 | MobileNet (28层) | 通道倍增系数<1.0 | 手机/嵌入式 |
| 平衡模型 | ResNet34 (34层) | 每阶段通道数递增 | 通用GPU |
| 大型模型 | ResNet152 (152层) | 瓶颈结构(Bottleneck) | 服务器集群 |
设计原则:
深度↑:增强抽象能力 → 需更多数据防止过拟合📊
宽度↑:提升特征丰富度 → 计算量平方级增长💥
平衡点:ImageNet任务建议16-50层,通道数16-512
🚀 三、实战代码:MNIST分类CNN配置
关键参数解析:
- 卷积核:全程3x3,padding=1保尺寸
- 通道数:32 → 64 渐进增加
- 降维:池化层stride=2实现尺寸减半
- 全连接:输入
64 * 7 * 7=3136→ 输出10维
📜 调参口诀表:一键保存备用
| 参数 | 口诀 | 示例场景 |
|---|---|---|
| 卷积核数量 | “浅少深多,翻倍递增” | ResNet: 64→128→256 |
| 卷积核大小 | “3x3走天下,省参高效首选它” | VGG全系3x3 |
| 步长 | “1保细节,2做压缩” | Stride=2替代池化 |
| 激活函数 | “隐藏层ReLU,输出层Softmax” | 分类任务最后一层 |
| 池化窗口 | “2x2最常用,纹理选Max,抗噪用Avg” | 图像分类:MaxPool |
| 全连接层 | “参数爆炸需警惕,全局池化来救命” | MobileNet用GAP |
避坑指南:
- 小数据集 → 减少卷积核数量防过拟合
- 深层网络 → 用ReLU防梯度消失
- 高分辨率图 → 增大步长或池化降计算量
拓展阅读:
1、深度学习笔记:超萌玩转卷积神经网络(CNN)(炼丹续篇)
3、深度学习“炼丹”实战:用LeNet驯服MNIST“神兽”


















 2466
2466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











