







COMFYUI能做到的,远不止于图像和视频~
数字人,现在也是comfyUI可以做到的~
相关项目:
ComfyUI-live-portrait (动态表情对齐)
LivePortrait是快手推出的开源人像动画生成框架,专注于高效、可控地将驱动视频的表情和姿态迁移至静态或动态人像,创造出富有表现力的视频。
ComfyUI-mimic-motion (动作迁移)
MimicMotion 是由腾讯公司推出的一款AI人像动态视频生成框架。该框架利用先进的技术,能够根据用户提供的单个参考图像和一系列要模仿的姿势,生成高质量、姿势引导的人类动作视频。MimicMotion 的核心在于其置信度感知的姿态引导技术,确保视频帧的高质量和时间上的平滑过渡。
ComfyUI-echo-mimic (数字人语音唇形对齐)
EchoMimic是阿里蚂蚁集团推出的A!数字人开源项目,赋予静态图像以生动语音和表情。通过深度学习模型结合音频和面部标志点,创造出高度逼真的动态肖像视频。
目前,以上三个项目都能通过COMFYUI整合起来。
这是三个最近比较好的关于数字人的项目,效果在同类领域都是目前表现最好的。完全取代了之前的animate anyone/ musepose,musetalk等。
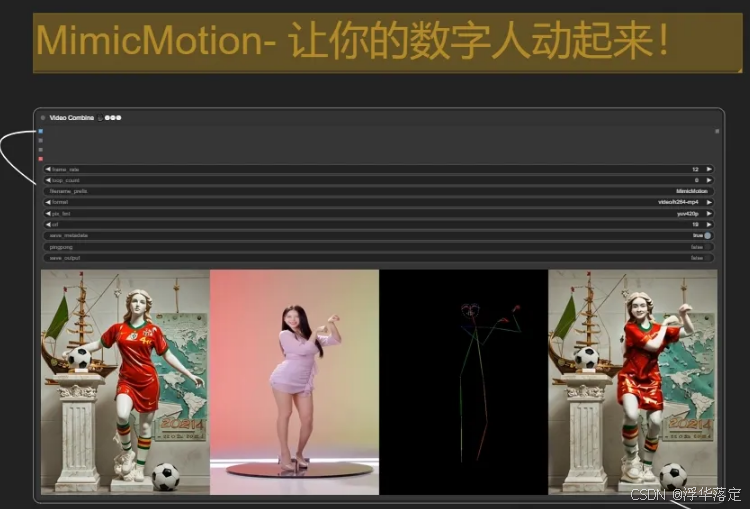
1. MimicMotion简介
MimicMotion 是由腾讯公司推出的一款人工智能人像动态视频生成框架。该框架利用先进的技术,能够根据用户提供的单个参考图像和一系列要模仿的姿势,生成高质量、姿势引导的人类动作视频。MimicMotion 的核心在于其置信度感知的姿态引导技术,确保视频帧的高质量和时间上的平滑过渡。
全民舞王windows+comfyui
链接:https://pan.quark.cn/s/990b8532c358
2. 功能特色
MimicMotion 的功能特色包括:
- 生成多样化视频:能够根据用户提供的姿态指导生成各种动作的视频内容,如舞蹈、运动或日常活动。
- 控制视频长度:用户可以指定视频的持续时间,从几秒的短片段到几分钟甚至更长的完整视频。
- 姿态引导控制:使用参考姿态作为条件,确保视频内容在动作上与指定姿态保持一致,实现高度定制化的视频生成。
- 细节质量保证:特别关注视频中的细节,尤其是手部等容易失真的区域,通过置信度感知的策略提供更清晰的视觉效果。
- 时间平滑性:确保视频帧之间的过渡平滑,避免卡顿或不连贯的现象,使视频看起来更加流畅自然。
- 减少图像失真:通过置信度感知的姿态引导,减少由于姿态估计不准确导致的图像失真。
- 长视频生成:采用渐进式潜在融合技术,生成长视频时保持高时间连贯性。
- 资源消耗控制:优化算法以确保资源消耗保持在合理范围内,即使在生成较长视频时也能有效地管理计算资源。
3. 官网入口
MimicMotion 的官网提供了项目的详细信息,包括技术原理、使用教程和下载链接。用户可以通过官网进一步了解框架的功能和如何使用它。具体的官网入口可以通过搜索 “MimicMotion 官网” 找到,或者访问腾讯相关的技术平台页面。
https://tencent.github.io/MimicMotion/
https://github.com/kijai/ComfyUI-MimicMotionWrapper

下载模型
- 技术原理
MimicMotion 的技术原理涉及多个方面:
姿态引导的视频生成:利用用户提供的姿态序列作为输入条件,引导视频内容的生成。
置信度感知的姿态指导:通过分析姿态估计模型提供的置信度分数,对姿态序列中的每个关键点进行加权,以减少不准确姿态估计对生成结果的影响。
区域损失放大:针对手部等容易失真的区域,在损失函数中增加权重,提高生成视频的手部细节质量。
潜在扩散模型:使用潜在扩散模型提高生成效率和质量,减少计算成本。
渐进式潜在融合:生成长视频时,通过逐步融合重叠帧的潜在特征,实现视频段之间的平滑过渡。
预训练模型的利用:基于预训练的视频生成模型(如Stable Video Diffusion, SVD),减少训练所需的数据量和计算资源。
U-Net和PoseNet的结构:模型结构包括用于空间时间交互的U-Net和提取姿态序列特征的PoseNet,共同实现高质量的视频生成。
- 如何体验MimicMotion?
要体验 MimicMotion,用户需要准备输入参考图像和姿势序列。然后,可以使用 MimicMotion 模型进行视频生成,并根据需要调整置信度感知姿态引导的参数。此外,应用区域损失放大策略可以优化特定区域的图像质量。利用渐进式潜在融合策略,用户可以生成长视频,并通过重叠扩散技术生成任意长度的视频。进行用户研究和消融研究可以帮助评估和改进视频生成效果。
https://tencent.github.io/MimicMotion/





















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











