




ComfyUI 是一个基于 Stable Diffusion 的AI绘画创作工具,最近发展势头特别迅猛,但是 ComfyUI 的上手门槛有点高,用户需要对 Stable Diffusion 以及各种数字技术的原理有一定的了解才行。这个系列将会介绍 ComfyUI 的一些基础概念和使用方法,让大家更快的掌握 ComfyUI 的使用技巧,创作出自己独特的艺术作品。
本文继续分享 ComfyUI 的使用方法:图生视频,也就是根据图片生成视频,使用的模型是SVD。
我之前的很多萌宠图片就是用它生成的,阅读量还不错:


SVD介绍 (图片到视频)
SVD是由 Stable Diffusion 的创作者 Stability AI 公司开源发布的。
SVD的全称是 Stable Video Diffusion,也就是稳定视频扩散的意思,目前最新版本是1.1。这个模型以静止图像作为条件帧,并从中生成视频,目前还不支持使用提示词引导。默认参数下生成的结果是分辨率为1024x576的25帧视频,不过ComfyUI中实测也可以生成多种分辨率和更长时长的视频。
SVD既可用于非商业用途,也可用于商业用途。你可以在许可下使用此模型进行非商业或研究用途,不过大家也要注意遵守相关法律和规定,并确保不侵犯他人的知识产权,具体使用许可协议可以看这里:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
SVD官方主页 : Huggingface | | Stability.ai || 论文地址
huggingface在线运行demo : https://huggingface.co/spaces/multimodalart/stable-video-diffusion
SVD开源代码:Github(含其他项目) || Huggingface
在Comfyui使用: ComfyUI国内下载 | SVD模型下载 | | 官网下载(Github)
安装ComfyUI
参考本人comfyui专栏安装手册
使用SVD
下载SVD模型
官方模型下载地址:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
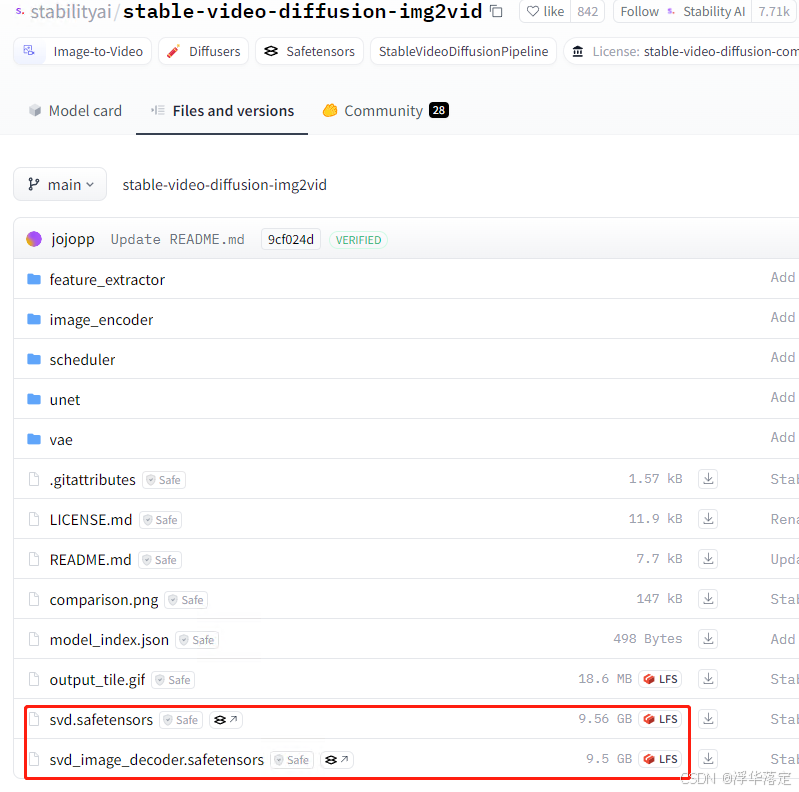
目前huggingface无法下载stable-video-diffusion-img2vid-xt-1-1/, 使用https://www.modelscope.cn/models/cjc1887415157/stable-video-diffusion-img2vid-xt-1-1/files
需要下载的文件名称:svd.safetensors/svd_image_decoder.safetensors
其他可下载
svd_xt.safetensors 用此模型生产失败, 改用下面这个可以
svd_xt_image_decoder.safetensors
下载后放到这个目录下:ComfyUI/models/checkpoints
使用SVD工作流
SVD的工作流比较简单,大家只要在“加载”中加载这个工作流就行了,不需要特别安装插件,工作流领取方式见文末。
我这里再做一个简单的标注,让大家了解其中的原理,并配置记得参数。
1、加载SVD模型,下载上一步介绍的模型到指定的位置,就可以在这里选择到。部署模型后请注意刷新页面,让节点尽快发现到模型。
2、上传图片,这里没什么限制,上传自己喜欢的就行了。SVD对风景或者移动物体图片的视频生成效果比较好,人物图片生成视频时需要控制动作幅度,否则容易崩溃。
3、设置帧数,这个参数影响视频的时长,默认值是25。因为默认的帧率是6,2秒就是12,4秒24。
4、设置帧率,帧率就是每秒的画面数,帧率越高视频越连贯,建议先从默认的6开始,逐步上调,看效果能否满意。
5、动态bucketID,这个参数控制视频中主体的动作幅度,值越小动作变化越小,以人或动物为主体时一定要设置为较小的值,否则容易崩溃。
参数说明
cfg: 从最小到最大,以适应视频不断变化的画面
高了, 会更稳定;低了,会更自由。自己琢磨
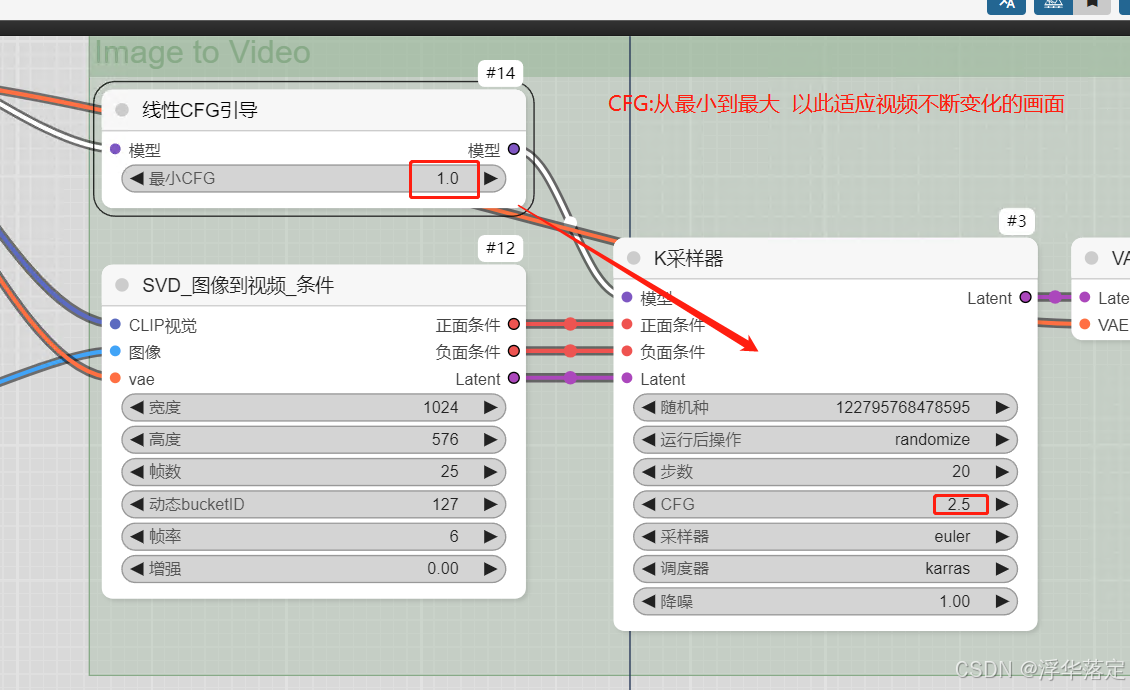
- 增强 越高视频与初始值的差异越大

生成视频
最后点击“添加提示词队列”,静待视频生成就好了,生成需要的时间取决于你的机器性能、视频的分辨率和帧数。
2023年11月21日 由 Stability AI 开源2个图片到视频模型(“Stable Video Diffusion”(稳定视频扩散模型)
它将静止图像(still image)作为条件帧(conditioning frame),并从中生成视频分辨率(1024x576)。
上传已有1张图片,生成相关的视频片段、生成视频长度2-5秒,帧率 3-30帧每秒,
串联一个Stable-XL模型,生成图片后,再生成视频 (文字到图片再到视频)

模型的缺点(不能干的事情)?
生成的视频相当短(<=4秒),并且该模型没有实现完美的真实感。
该模型可能生成没有运动的视频,或者生成非常慢的相机平移(没变化)。
不能直接文本控制模型 (需要串联其他模型)。
该模型无法呈现清晰的文本(legible text)(让艺术字动起来)。
一般来说,人脸和人物可能无法正确生成。
模型的自动编码部分是有损的(lossy)。
工作流
Stable-XL生成图片再生成视频(Text2Img2Video)
工作流文件: 链接:https://pan.baidu.com/s/1CvyGmUibreM8SM7AFjt1uA?pwd=0125
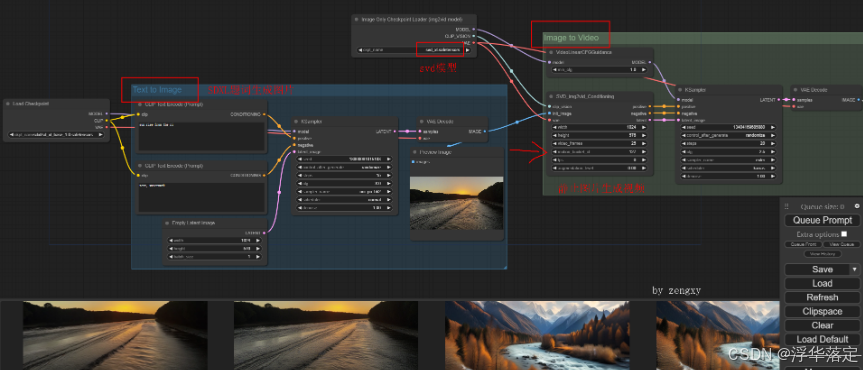
第一次初始化+运行示例,在3090Ti上花费 209.35秒
拍摄美丽的风景自然山脉阿尔卑斯河急流雪天积云
photograph beautiful scenery nature mountains alps river rapids snow sky cumulus clouds

官方工作流跑图

第二次 花费 生成图片(6秒)+视频 (花费70秒)
题词来源于论文图17
一艘悠闲地沿着塞纳河航行的船,背景是文森特·梵高的埃菲尔铁塔
题词
A boat sailing leisurely along the Seine River with the Eiffel Tower in background by Vincent van Gogh

一只独角兽在一个神奇的小树林里,非常详细
A unicorn in a magical grove, extremely detailed

使用上传的图片生成视频?




















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











