






es的搭建:
本机使用vmware创建的centos7虚拟机搭建,刚开始设置虚拟机内存为2G,es启动后启动kibana时es服务挂了,所以将虚拟机内存调整为4G,es比较占内存,推荐4G及以上;
后面的百度网盘链接有详细步骤,我这里简单介绍一下安装步骤:
1、下载es、kibana、分词器等,需要下载对应版本,我这里有一套7.6.1版本的
链接:https://pan.baidu.com/s/17yQQQdeYzdEAx_0qgdsarg?pwd=djyg
2、解压es到指定目录:
tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/
3、解压分词器到el的配置文件目录下:
unzip elasticsearch-analysis-ik-7.6.1.zip -C /usr/local/es/elasticsearch-7.6.1/plugins/ik
4、解压kibana到指定目录
tar -zvxf kibana-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/
5、解压es和kibana后修改配置文件如下,192.168.60.162是虚拟机的ip,修改elasticsearch.yml和kibana.yml的配置文件如下:
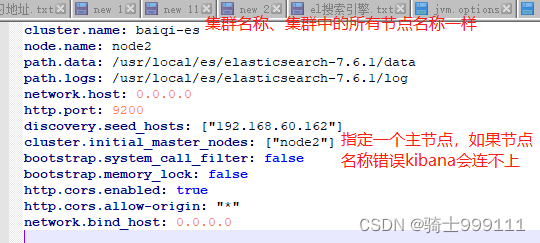
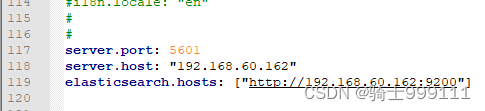
es不能使用root用户启动,为es单独创建一个用户,启动es和kibana:
启动es: nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
启动kibana:/usr/local/es/kibana-7.6.1-linux-x86_64/bin/kibana
kibana启动成功后打开 http://192.168.60.162:5601/app/kibana#/dev_tools/console 进行练习
安装及使用步骤见附件:
链接:https://pan.baidu.com/s/1-LVG55WiPeoJQCnOXH6-ag?pwd=nlcm
关闭es服务:
ps -ef|grep elasticsearch 获得es的端口号
kill -9 端口
es的分词器:
对于英文分词器就是按空格划分,这样每个单词就是一个索引,中文使用ES的默认分词是standard,这个在中文分词时会单字拆分,比如“清华大学”,这时候会按“清”,“华”,“大”,“学”去分词,然后搜出来的都是些“清水”,“中华”,“地大物博”之类的莫名其妙的结果,这里我们就想把这个分词方式修改一下,有两种ik_smart和ik_max_word。ik_smart会将“清华大学”整个分为一个词,而ik_max_word会将“清华大学”分为“清华大学”,“清华”和“大学”,按需选其中之一就可以了。
ik_max_word是因为在分词字典中维护了常用的词,所以可以按照我们日常看着比较习惯的方式分词,这些分词字典是在分词器里面的,解压在es的plugins/ik/config目录下
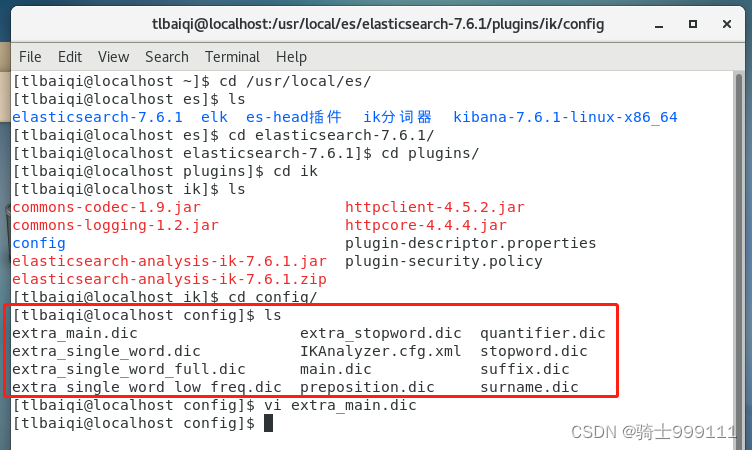
除了这些分词我们也可以自定义分词,参考:elasticsearch学习(六):IK分词器_炎升的博客-优快云博客
es的索引结构:
倒排索引 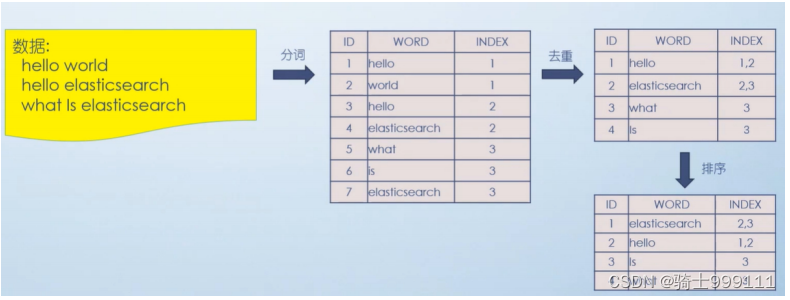
倒排索引使用前缀树进行存储,参考: 底层实现数据结构:字典树(前缀树)_es中的字典树是什么-优快云博客
前缀树的演示效果:http://examples.mikemccandless.com/fst.py
通过字符串从前缀树中搜索,就能唯一确定一个叶子节点,叶子节点中存储的是这个索引的文档id集合,参考前缀树的实现:208. 实现 Trie (前缀树) - 力扣(LeetCode)
es的查询是使用dsl语法
详细的使用见附件:链接:https://pan.baidu.com/s/1fJgXR2-K3-uimPOBC50t_Q?pwd=iijn
es 的Java client的demo
见以下链接,包括创建索引库、对索引库数据的增删改查等操作
链接:https://pan.baidu.com/s/17okUyuIyOljWR4B3dkqY8A?pwd=wuyn
es 官方客户端:
elasticsearch-rest-high-level-client,使用参考:
elasticsearch学习(七):es客户端RestHighLevelClient-优快云博客
es的结构和概念:
集群:多台安装了es的节点组成的集群;
节点:安装了es的服务器,分为主节点、数据节点、协调节点等,一个服务器节点可以同时是主节点、数据节点或其他节点;
主节点负责创建或删除索引、分配分片、维护集群状态、协调集群中的节点;
数据节点:存储数据,执行搜索、写入等操作,是存储和计算的核心,数据节点越多集群性能越强;
协调节点:接受客户端的请求并转发给相关的数据节点,将计算结果返回给客户端,不存储数据也不参与集群管理,所有节点默认都有协调功能;
索引:用于存储数据的结构,类似数据库中的表;
文档和字段:文档指一条数据,字段就是文档中的某个值;
分片:保存到es中的数据分片存储,每个索引默认5个主分片(可调整),每个主分片有一个默认副本,建议每个分片的大小在10-50G之间;
Lucene 索引:包含倒排索引和正排索引(保存的数据),一个分片就是一个Lucene 索引,是一个开源的全文搜索引擎库,es基于Lucene实现;
Segment 段:一个Lucene 索引包含多个段,写入的数据先进入内存缓冲区中,定期刷新(默认间隔1S)后加入段中,进入段中后数据才能被查询到。删除数据时更新段中数据的状态为删除,触发一些条件(可配置)就会触发段的合并,将多个段合并成一个段并将删除的数据进行物理删除,每个分片中段的数量根据数据大小、段合并策略等相关;
数据库中的数据同步到es:
1、通过canal读binlog将数据写入到es,实时性高、不影响数据库性能;
使用数据库的id作为es中的文档id,来避免数据重复写入
2、使用es 的jdbc driver,配置数据源和同步的数据(sql)、指定轮询时间,定时将数据写入到es中。实时性受轮询间隔影响;
3、使用logstash读取数据库数据写入到es中,逻辑和2一样;
4、定时任务同步、数据库中创建触发器、写数据库时写入es,这几种方式要么实时性差,要么影响数据库性能,不推荐使用;
同步多张表到es:
数据同步到es时很多时候不是单表,需要同步多个表关联查询的结果,有以下几种实现:
1、将要同步的数据建立视图,cannal也可以同步视图数据;
2、cannal同步表数据时根据关联查询其他表数据;
3、es 的jdbc driver 和 logstash都是通过sql指定要同步的数据,sql可以关联查询多张表

















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









