







参考:
https://www.jianshu.com/p/139c2429c5d3
https://blog.youkuaiyun.com/weixin_44279178/article/details/108469778
知乎-详解哈希表
哈希表
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
(哈希表的底层是数组)
实现哈希表的两种方法:
1、数组+链表
2、数组+红黑二叉树
优点:
哈希表是一种非常优秀数据结构,它提供了快速的插入操作和查找操作。对哈希表进行数据的插入,查找(有时也包括删除)的时间复杂度都是O(1)。(在没有哈希冲突的情况下)
从这个时间复杂度,我们就可以知道哈希表是基于数组实现的,因为只有数组才可以直接通过下标获取对应的元素。
哈希函数
建立起数据元素的存放位置与数据元素的关键字之间的对应关系的函数。即使用哈希函数可将被查找的键转换为数组的索引。
理想情况下它应该运算简单并且保证任何两个不同的关键字映射到不同的单元(索引值)。但是,这是不可能的,很多时候我们都需要处理多个键被哈希到同一个索引值的情况,即哈希碰撞冲突
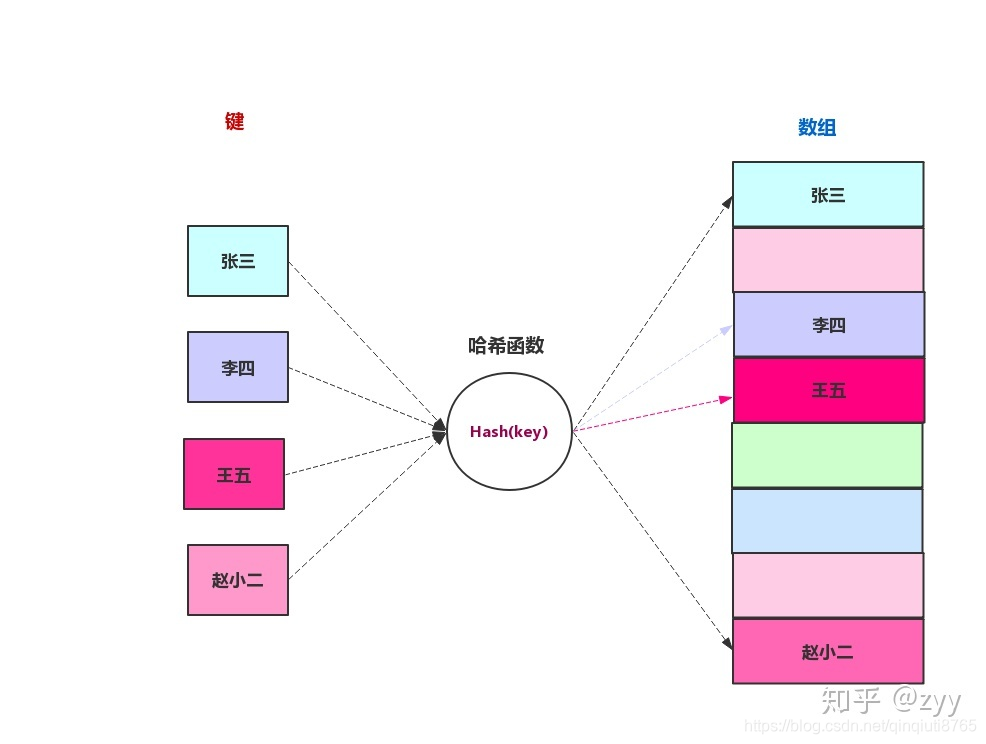
哈希函数有很多构造方法。所谓一个好的哈希函数指的就是,当用这个hash函数作用在不同的key时,所得到的value能够均匀的分布在hash表中,即能尽可能少的减少hash冲突。比较常见的hash函数的构造方法有:
直接定址法
数字分析法
平方取中法
折叠法
除留余数法
随机数法
哈希函数不管怎么实现,都应该满足下面三个基本条件:
- 散列函数计算得到的散列值是一个非负整数
- 如果 key1 = key2,那 hash(key1) == hash(key2)
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
第一点:因为数组的下标是从0开始,所以哈希函数生成的哈希值也应该是非负数
第二点:同一个key生成的哈希值应该是一样的,因为我们需要通过key查找哈希表中的数据
第三点:看起来非常合理,但是两个不一样的值通过哈希函数之后可能才生相同的值,因为我们把巨大的空间转出成较小的数组空间时,不能保证每个数字都映射到数组空白处。所以这里就会才生冲突,在哈希表中我们称之为哈希冲突
解决碰撞冲突
1、开放地址法
开放地址法:通过系统的方法找到系统的空位(三种:线性探测、二次探测、再哈希法),并将待插入的元素填入,而不再使用用hash函数得到数字作为数组的下标。
- 线性探测:假若当前要插入的位置已经被占用了之后,沿数组下标递增方向查找,直到找到空位为止
- 二次探测:二次探测和线性探测的区别在于二次探测的步长是,若计算的原始下标是x则二次探测的过程是x+12,x+22,x+32,x+42,x+52随着探测次数的增加,探测的步长是探测次数的二次方(因此名为二次探测)。二次探测会产生二次聚集:即当插入的几个数经过hash后的下标相同的话,那么这一串数字插入的探测步长会增加很快
- 再hash法:为了消除原始聚集和二次聚集,把关键字用不同的hash函数再做一遍hash化,用过这个结果作为探测的步长,这样对于特定的关键字在整个探测中步长不变,但是不同的关键字会使用不同的步长。stepSize = constant - (key % constant) 这个hash函数求步长比较实用,constant是小于数组容量的质数。(注意:第二个hash函数必须和第一个hash函数不同,步长hash函数输出的结果值不能为0)
2、链地址法
链地址法 :创建一个存放单词链表的数组,数组内不直接存放元素,而是存储元素的链表。发生冲突的时候,数据项直接接到这个数组下标所指的链表中即可。
优势:填入过程允许重复,所有关键值相同的项放在同一链表中,找到所有项就需要查找整个是链表,稍微有点影响性能。删除只需要找到正确的链表,从链表中删除对应的数据即可。表容量是质数的要求不像在二次探测和再hash法中那么重要,由于没有探测的操作,所以无需担心容量被步长整除,从而陷入无限循环中。
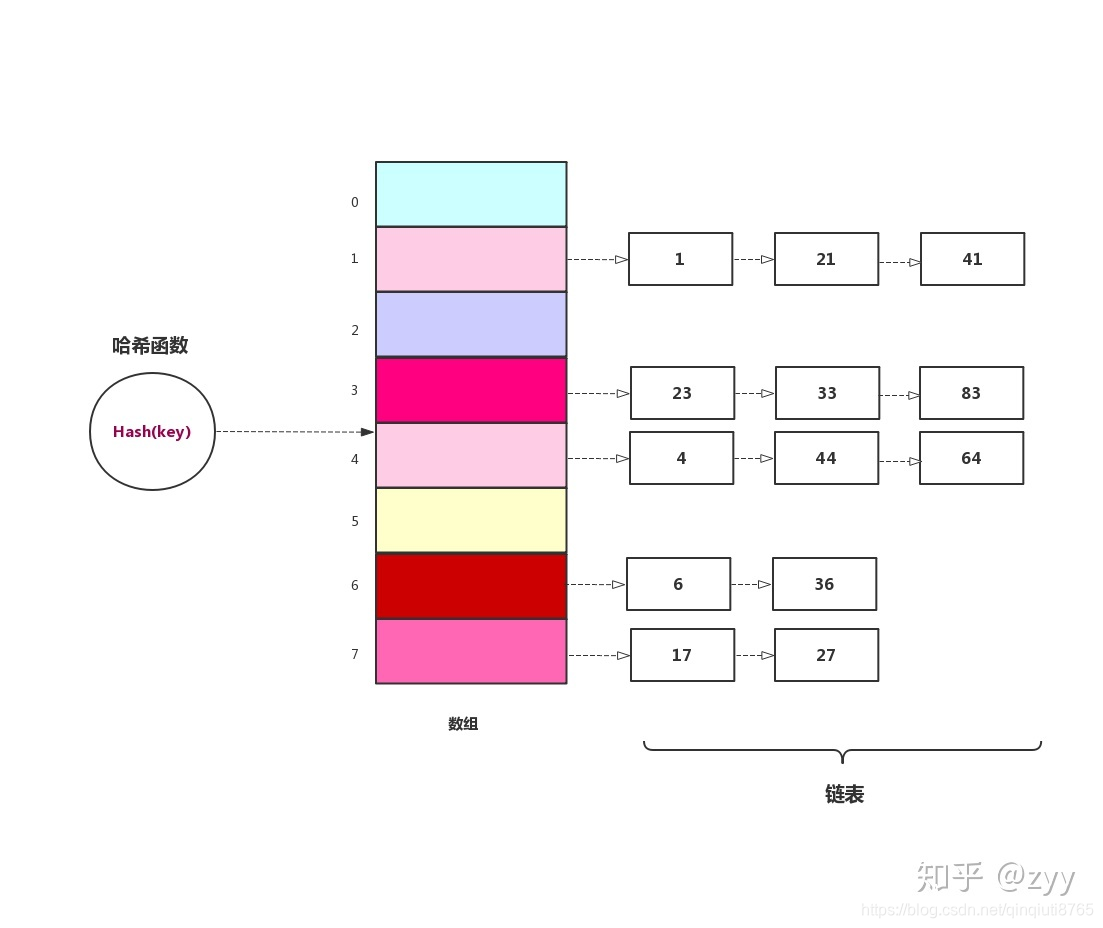
如果冲突的很多,那这个增加的链表岂不是很长?
如果冲突过多的话,这个key对应的链表会变得比较长,怎么处理呢?这里举个例子吧,拿java集合类中的HashMap来说吧,如果这里的链表长度大于等于8的话,链表就会转换成红黑树结构,当然如果长度小于等于6的话,就会还原链表。以此来解决链表过长导致的性能问题。这样设计是因为中间有个7作为一个差值,来避免频繁的进行树和链表的转换,因为转换频繁也是影响性能的啊。
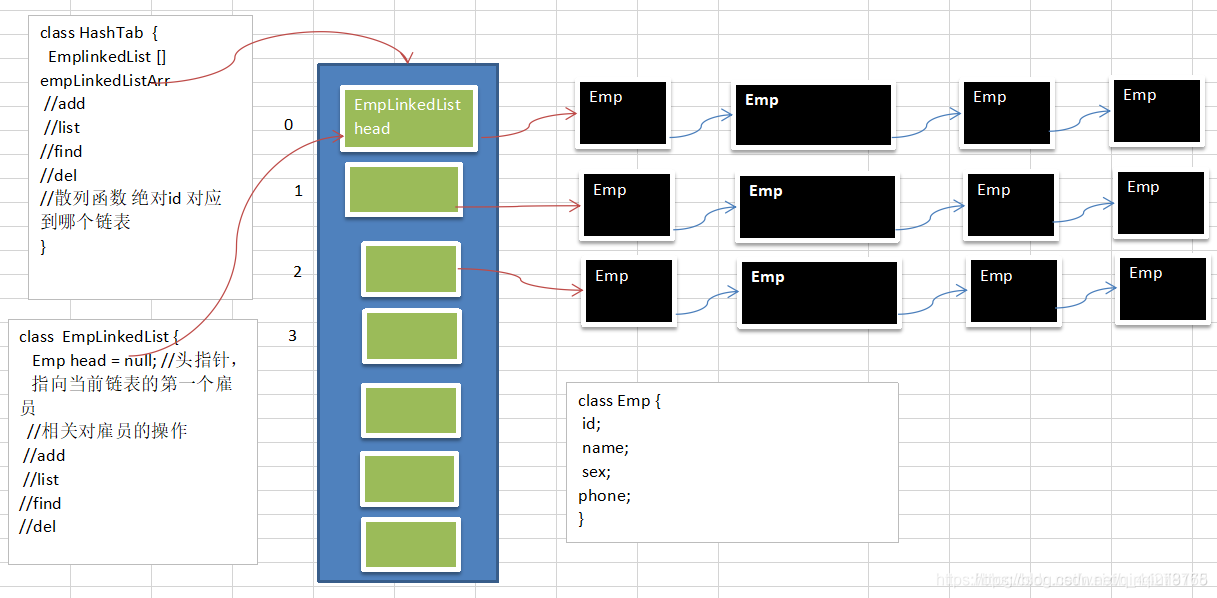
应用:使用哈希表管理雇员信息
题目:有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id、姓名,性别,电话),当输入该员工的id时,要求查找到该员工的所有信息.
要求:
- 不使用数据库,速度越快越好
- 添加时,保证按照id从低到高插入
- 使用链表来实现哈希表, 该链表不带表头
思路:
添加雇员信息
- 创建一个节点类存储雇员的信息(id,name,sex,phone)
- 创建一个定长数组为哈希表,哈希表的每个数组元素储存一条链表头节
- 根据散列函数将要添加的雇员id进行散列(比如:散列函数构造采用简单的取模法:H(k)=id % size 假如id=1001 数组长度为7则取余后的key为0 对应的数组下标为0)
- 根据id散列后的key值将对应id的雇员节点链接到对应的数组下标下的链表后面
查找对应id的雇员信息:
- 根据id散列得到key值
- 到key值对应的数组下标的链表中进行查询
————————————————
版权声明:本文为优快云博主「jQueryZK」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/weixin_44279178/article/details/108469778

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









