







 本文介绍了RocksDB在优化深层查询性能时,通过为不同层级的SST文件建立索引来提高查询效率。在LevelDB的基础上,RocksDB针对读写路径和Compaction进行了优化,尤其是引入了SST文件的分层索引,减少了查找次数,降低了复杂度。通过在compaction时构建SST文件间的索引结构,实现了常数级别的查找比较次数,有效应对大数据量场景下的高频Get操作。
本文介绍了RocksDB在优化深层查询性能时,通过为不同层级的SST文件建立索引来提高查询效率。在LevelDB的基础上,RocksDB针对读写路径和Compaction进行了优化,尤其是引入了SST文件的分层索引,减少了查找次数,降低了复杂度。通过在compaction时构建SST文件间的索引结构,实现了常数级别的查找比较次数,有效应对大数据量场景下的高频Get操作。
Google LevelDB 是一个 LSM-Tree 的实现典范。但在开源出来后,为了保持轻量、简洁的风格,除了修修 Bug 之外,一直没有做太大的更新迭代。为了让其能够满足工业环境中多样性的负载, Facebook(Meta) 在 Fork 了 LevelDB 之后,做了多方面的优化。硬件方面,可以更有效地利用现代硬件,如闪存和快速磁盘、多核 CPU等;软件方面,针对读写路径、Compaction 也做了大量优化,如 SST 索引、索引分片、前缀 Bloom Filter、列族等。
本系列文章,依据 RocksDB 系列博客,结合源码和一些使用经验,分享一些有趣的优化点,希望能对大家有所启发。水平所限,不当之处,欢迎留言讨论。
本篇是 RocksDB 优化系列第一篇,为了优化深层查询性能,将不同层级的 SST 通过一定方式索引起来。
作者:木鸟杂记,转载请注明出处:https://zhuanlan.zhihu.com/p/556113577
背景
首先,上个之前文章中画的 LevelDB 架构图。
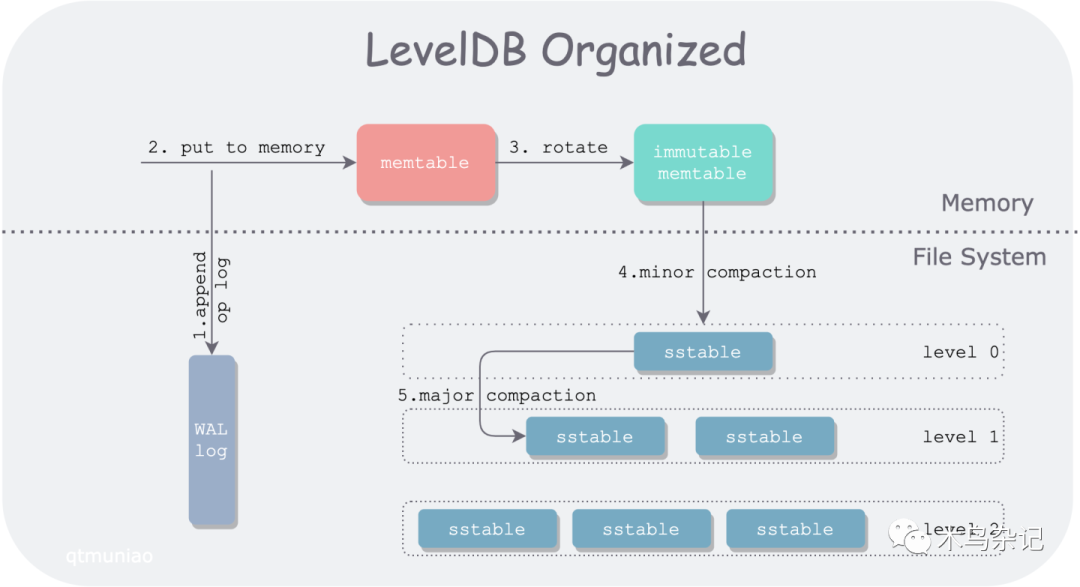
LevelDB 架构图
其中,LevelDB 中一个 Get() 的请求路径,会先后经过:
-
一个可变的 memtable
-
一系列不可变的 memtable
-
层级组织的一系列 SST 文件
其中,0 层中的 SST 文件是由不可变的 memtable 直接刷盘而来的,其键范围(key range,由FileMetaData.smallest and FileMetaData.largest 界定)大部分都互相交叠。因此,在 0 层中要对所有 SST 文件逐个查找。
其他层的 SST 则由上层 SST 不断压实( Compaction) 而来,由此将数据从上层到下层不断沉降。Compaction 过程会将多个 SST 合并在一块,挤出“水分”(重复的 key),然后分裂成多个 SST 文件,因此在 1 层之下,所有的 SST 文件键范围各不相交,且有序。这种组织方式,可以让我们在层内查找时,进行二分查找(O(log(N)) 复杂度),而非线性查找(O(N) 复杂度)。
具体查找方法为,以待查找值 x 为目标,以每个文件的 FileMetaData.largest 组成的数组作为二分对象,不断缩小查找范围,确定目标 SST 文件。如果没有找到包含 x 的 key range 对应的 SST 文件或者对应 SST 文件中没有 x,则向下层继续搜索。
但在大数据量情况下,下层的文件数仍然非常多,对于高频的 Get 操作,即使是二分查找,每层的比较次数,也会线性增长。比如对于 10 的扇出因子(fan-out ration),即下层 SST 文件数量是紧邻上层的十倍,则第 3 层会有将近 1000 的文件数量,最坏情况下需要进行 10 次左右的比较。乍看起来不多,但在百万级别的 QPS 下,这是相当可观的开销。
优化
分析
可以观察到,在 LevelDB 的版本机制下,每个版本(VersionSet,由 Manifest 文件保存)内的 SST 文件数量是定死的、位置也是定死的,则不同层 SST 文件的相对位置也是确定的。
则,我们在每一层进行查找时,其实不用从头开始二分,上层已经二分出的一些位置信息可以进行复用。因此,可以再增加一些类似查找树(如 B+ 树)的层级间的索引结构,以减小底层的二分范围。这种思想称为 Fractional cascading。
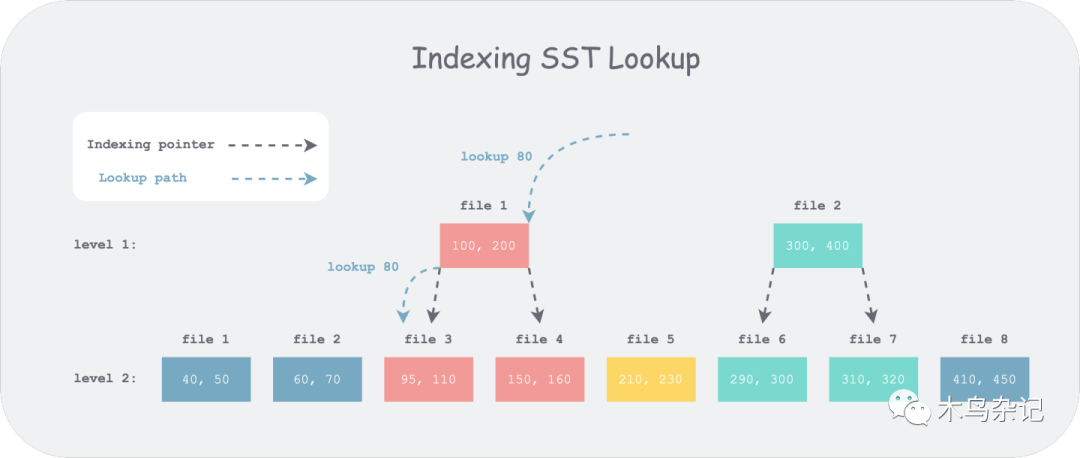
Untitled SST Indexing 后查找示意图
举个例子,如上图,1 层有 2 个 SST 文件,2 层有 8 个 SST 文件。假设现在我们想要查找 80,首先在第一层中所有文件的 FileMetaData.largest 中搜索,可以得到候选文件 file 1,但通过与其上下界比较发现小于其下界。于是继续向 2 层搜索,如果 SST 上没有索引,我们需要对所有八个候选文件进行二分,但如果有索引,如上图,我们只需要对前三个文件进行二分。由此,每层搜索的比较次数可以做到常数级别 N(扇出因子,即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









