SAC算法网络框架




于 2022-11-21 11:53:40 首次发布
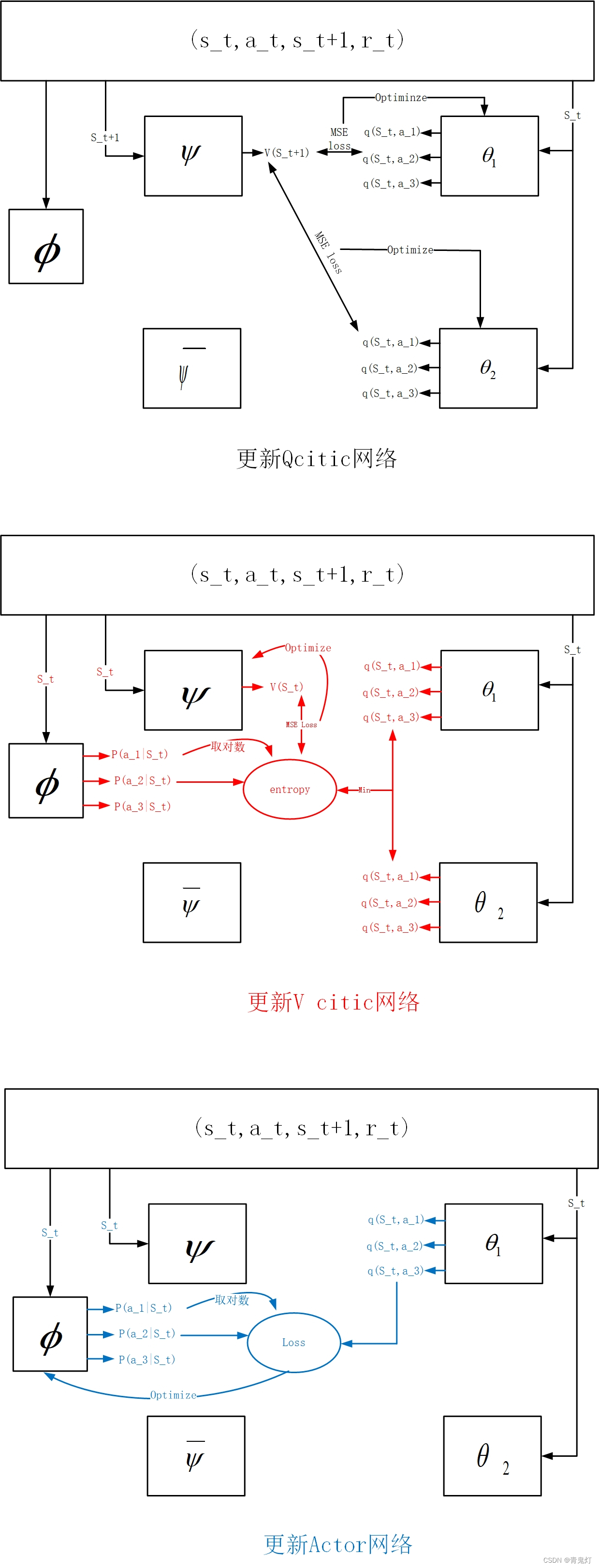
 博客主要提及SAC算法网络框架,还给出了知乎大佬文章及相关资料作为详细参考。
博客主要提及SAC算法网络框架,还给出了知乎大佬文章及相关资料作为详细参考。
博客主要提及SAC算法网络框架,还给出了知乎大佬文章及相关资料作为详细参考。
博客主要提及SAC算法网络框架,还给出了知乎大佬文章及相关资料作为详细参考。
 3496
3592
4069
3496
3592
4069


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言