



 文章介绍了数据监控在工业物联网中的重要性,以工厂设备故障预防为例,阐述了IoTDB的User Defined Function (UDF) Sample算法如何在数据可视化中解决传统抽样算法的问题。IoTDB的Sample算法基于最大三角原理,能更好地保留异常数据点,适用于故障诊断场景,确保关键信息在数据抽样中不丢失。
文章介绍了数据监控在工业物联网中的重要性,以工厂设备故障预防为例,阐述了IoTDB的User Defined Function (UDF) Sample算法如何在数据可视化中解决传统抽样算法的问题。IoTDB的Sample算法基于最大三角原理,能更好地保留异常数据点,适用于故障诊断场景,确保关键信息在数据抽样中不丢失。
数据监控的概念

设备的数据监控是最广泛的工业物联网应用之一,通过对工厂的机械设备的状态进行监控,可以及早发现工厂设备的潜在故障,实现预防性维护与可预测性维护,有效提高工厂设备的总体使用效率( OEE ),为工厂带来切实的降本增效。
数据监控的具体案例
曾经有工厂 A 的一个关键超大型加工中心( CNC )发生突发故障。由于这台加工中心是一个高价值设备,整个工厂这样的设备只有一台,设备故障后整个工厂停产,设备维修课的 6 位维修工程师只能三班倒进行设备拆机抢修,在连续抢修 48 小时后,才勉强使得加工中心( CNC )恢复工作,但设备生产精度下降,不合格产品增加。再等待了一周时间,从设备原厂订购到关键部件并进行替换后,整个生产才完全恢复正常。事后,工厂设备总工复盘故障问题,发现如果给设备加装监控传感器是有机会提前发现一些潜在故障。这样如果发现潜在故障并提前订购配件,不仅可以以更低的价格购买相关配件,并且也可以合理安排维修进度,且不必进行连续抢修。最重要的,通过合理安排维修进度,可以有效避免工厂整体停工带来的经济损失。
对于工厂设备的监控,基于人工智能的自动化故障诊断是未来的发展方向,但是在现阶段,基于维修工人以及维修专家的诊断与判断仍然是非常重要的关键步骤,人工智能只能起到辅助作用。那么既然需要人来进行最终判断,那么监控数据的展示就变得十分重要,将数据的关键信息展示给专家是专家能够做出正确判断的第一步。所以对于物联网,对于 IoTDB 来说,数据可视化展示的相关功能也是其非常重要的组成部分。
这里以利用物联网监控加工中心切削液喷射压力数据为例,介绍 IoTDB 的 Sample UDF 实践应用。图 1 是机床切削液压力数据,分为 12 小时的数据图和 7 天的数据图,物联网传感器每一秒采集一次加工中心切削液的压力:
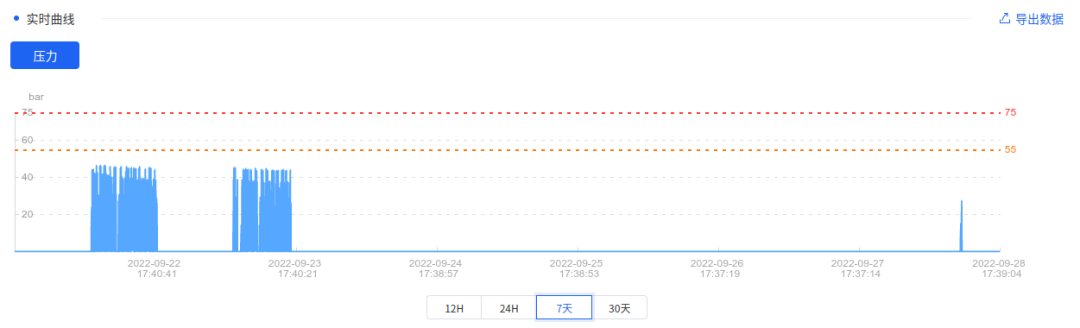
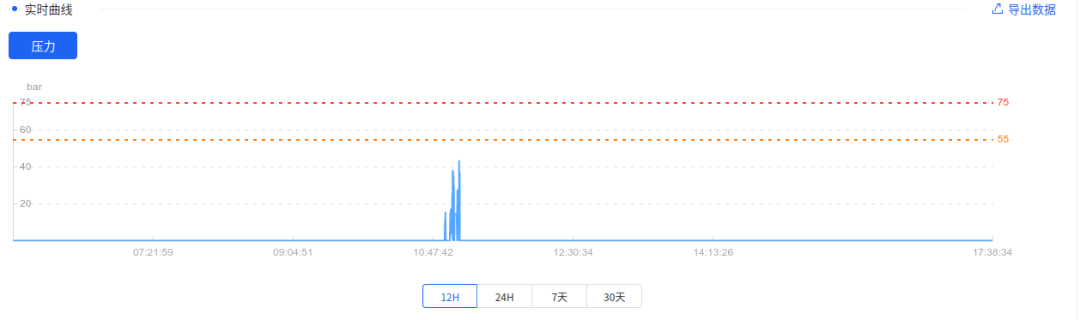
图1 切削液压力监控数据
可以看到数据存在快速的压力变化,这时应为加工中心在加工过程中会频繁得进行换刀操作,每次加工一个不同的工艺都需要换一把不同的切削刀具,在这个过程中从刀具上喷射的切削液压力会存在快速的变化。在上图中可以看到过去 12 小时中,压力有一个变化的脉冲。那么当维修班组的人看到这个数据时,第一个问题就是要问这个数据是否正常,那么想到的最简单的方法就是把这个数据和过去的数据做比较,在图 1 中,我们将数据显示周期切换到 7 天的数据,把数据和过去的数据对比就可以比较清晰得看出这个数据和过去比是有异常的。维修专家通过和现场操作工进行沟通,了解到这是由于切削刀断裂引起的紧急停机事件。
IoTDB 的UDF Sample算法与传统抽样算法的区别
由于物联网采集的数据是连续不间断的,因此假设系统需要 0.1 秒来获取与展示 12 小时的切削液压力数据,那么同样情况下要向展示 7 天的数据,获取与展示的数据量就是原来 12 小时的 14 倍,整个系统完成数据展示就可能需要 2 秒左右的时间,这在人机交互过程中已经是不可接受的,因此,当展示 7 天甚至 30 天数据时,需要提前对数据进行抽样以降低需要展示的数据量。
在传统抽样算法中,主要是基于时间进行数据抽要,并不关心数据点的值,一般进行依照时间间隔进行等间距的下采样或者随机下采样。但是当在上面的故障诊断与监控场景中,这样的下采样就遇到了很大的问题,由于如图 1 中 7 天数据所示,由于异常数据通常持续时间比较短暂,在对数据进行下抽样过程中很容易将数据抽样掉而仅抽样到连续的 0 数据。因此为更好得应对异常值检测这类故障诊断场景,有必要设计新的抽样算法。
在 IoTDB 的 UDF Sample 算法中,我们提供了新的基于最大三角原理的抽样算法,这一采样算法很好得保留了快速变化的数据中的关键点,获得良好的数据可视化效果,在图1中我们就采用了这一算法,12 小时中的一小段异常数据能够在 7 天的抽样数据中得到几乎完整的保留。
以下是有关最大三角采样算法的一个概述:
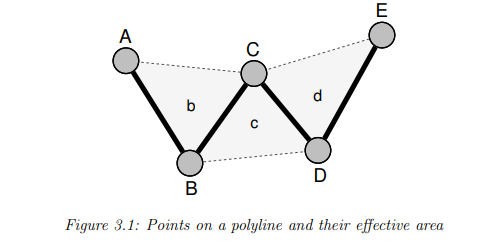
图2 数据点间的有效三角区域
关于最大三角采样算法的问答
问题:传统时间采样算法不考虑数据的变化,而是基于时间进行,对于突变数据容易在采样过程中丢失。
解决方案:
在采样过程中考虑数值部分变化,计算每个数据点和周围相邻数据点组成的三角形面积。抽样时,保留三角形面积最大的点。
算法行为:
最大三角采样法首先将所有数据会按采样率分桶,每个桶内会计算数据点间三角形面积,并保留面积最大的点,该算法通常用于数据的可视化展示中,采用过程可以保证一些关键的突变点在采用中得到保留,更多抽样算法细节可以阅读论文
http://skemman.is/stream/get/1946/15343/37285/3/SS_MSthesis.pdf
本文作者:李知周
曾在国际知名投资银行从事基于大数据与机器学习的网络安全和交易监管的开发及数据分析工作,4 年思科软件研发工程师经历。
中国科学院微系统与信息技术研究所博士,发表过多篇机器学习相关EI SCI学术论文,拥有多项国际国内专利,物联网早期创业者与创客。
擅长物联网网络设备软硬件研发,大数据分析与机器学习研发,熟练掌握多种开发语言(包括C、JavaScript、Java、Scala、Verilog),掌握端到端的网络系统架构与设计。开源物联网硬件项目 OpenFPGAduino 的发起者和维护者。


















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











