




 Apache IoTDB在0.13.0版本中引入了对齐时间序列的支持,以适应不同采集场景。时序数据库通常处理设备上的多个传感器数据,这些数据可能通过同时采集或独立采集的方式产生。非对齐存储适用于独立采集,对齐存储则适合同时采集。IoTDB通过设备层面的对齐存储,实现了同时支持两种存储方式,使得系统更加灵活,以满足原生时序数据库和关系型数据库在管理时序数据时的不同需求。
Apache IoTDB在0.13.0版本中引入了对齐时间序列的支持,以适应不同采集场景。时序数据库通常处理设备上的多个传感器数据,这些数据可能通过同时采集或独立采集的方式产生。非对齐存储适用于独立采集,对齐存储则适合同时采集。IoTDB通过设备层面的对齐存储,实现了同时支持两种存储方式,使得系统更加灵活,以满足原生时序数据库和关系型数据库在管理时序数据时的不同需求。
前言
Apache IoTDB 社区在 2022 年 3 月发布的 0.13.0 版本中有这样一条:支持 aligned timeseries(对齐时间序列),今天介绍一下这个功能的来龙去脉。
设备与传感器
时序数据库,直观感受,应该管理的是一条一条的时间序列,每条时间序列是个基本的单位。比如某个风速传感器随着时间采集的数据,就构成了一条时间序列。
一个传感器不会凭空存在,通常都是要对一个事物的环境进行监测的,这个事物我们就叫做设备。比如风速传感器按在风力发电机这个设备上,采集一台风机所在位置的风速。
此外,一个设备也不会只安装一个传感器,通常会安装多个,随着设备的大小和精密程度的变化,可以安装数个到上万个传感器。
比如风力发电机不止有风速传感器,还有温度、湿度等上百个传感器。
一个设备上有多个传感器,就是一个基本的数据模型,也是我们看待时序数据的方式。

三种场景,两种序列
这些传感器上的数据都是通过程序采集的,程序都是人写的,于是就有不同的采集方式了。
(1)第一种场景:设备上的一个程序定时获取每个传感器的值,都拿到之后,打上一个时间戳。这种方式拿到的多个时间序列能共用一个时间戳。我们可以叫这种序列为同时采集。
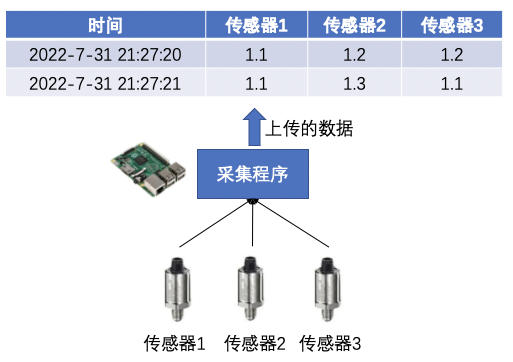
(2)第二种场景:每个传感器都对应一个采集程序,上传数据的时候打上时间戳,这种方式很可能不同序列采集的初始时间或者采集频率不同,导致多个序列的时间戳不能共用。我们可以叫这种序列为独立采集。
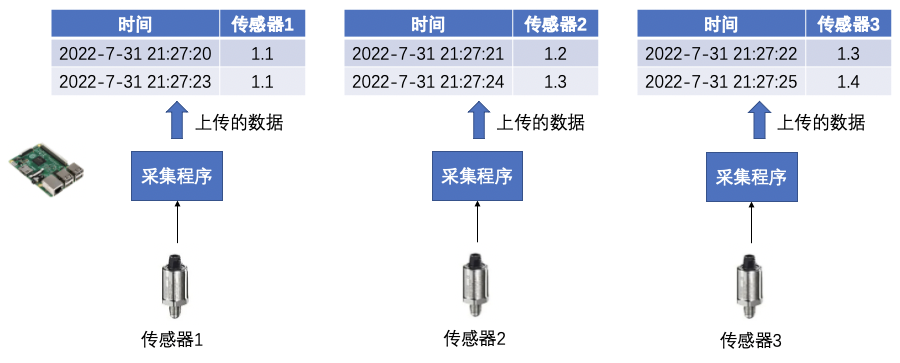
(3)第三种场景:为了减少上传的重复数据,节省存储空间,只有传感器的数值发生变化才上传。很可能每个传感器的变化时间不同,也对应独立采集。
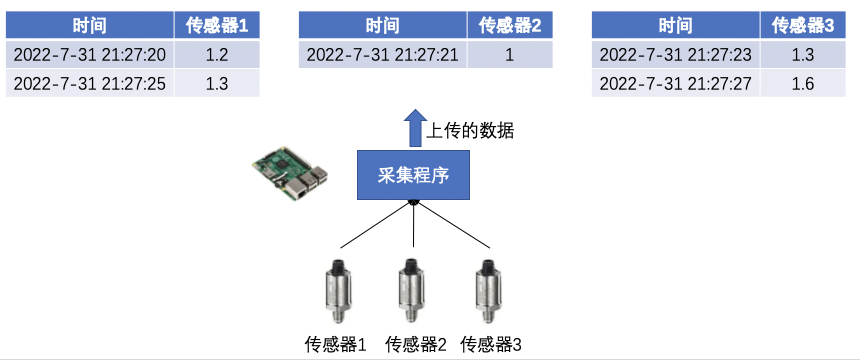
至此,我们可以看到,由于采集方式的不同,收集上来的序列分为两类:同时采集和独立采集。而且,有 2/3 的场景都是独立采集。
如何储存
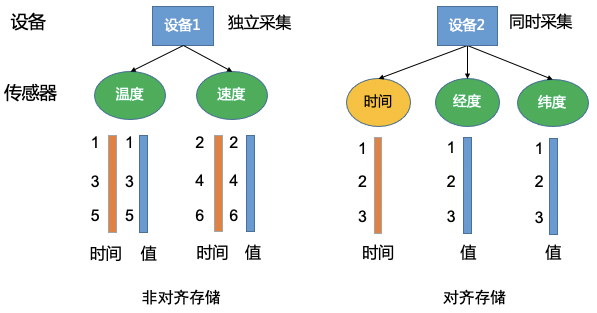
一种方式是,每个时间序列存储一列时间(非对齐存储),每个序列都是独立的,互不干扰,查询一个序列也不需要分别读时间和值,可以同时从磁盘读取出来。这种方案的优势就是存储非对齐的序列时,非常节省空间,没有任何额外存储开销。
不足之处是存储同时采集的序列时,每个序列的时间列都一样,有一些冗余。但是,时间列通常是能够压缩的很好的,因此每个序列存储一列时间也是可以接受的。
另一种方式是,每个设备存储一列时间(对齐存储),这个设备的所有传感器的都共用这一列。优点是存储同时采集的序列时,很整齐。缺点是存储独立采集的序列时,需要处理和存储很多空值,影响存储空间和读写效率。
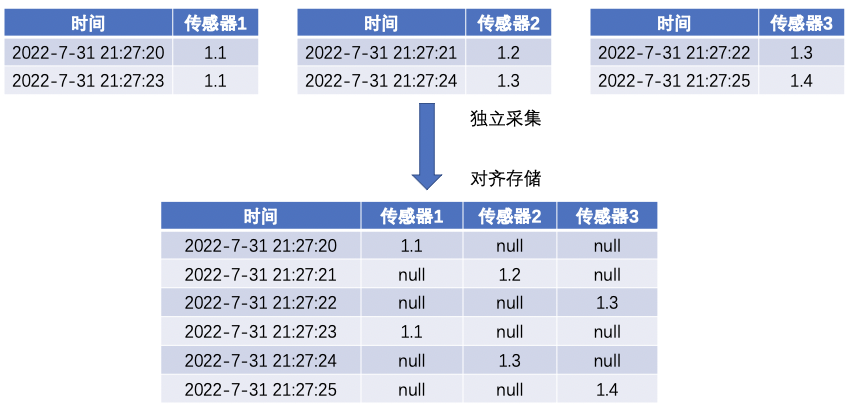
总结来看,非对齐存储和对齐存储,均可以管理两类采集的序列。但是效果不同,各有优劣。如果总的来看,非对齐存储在管理时序数据上适用面会更广一些。
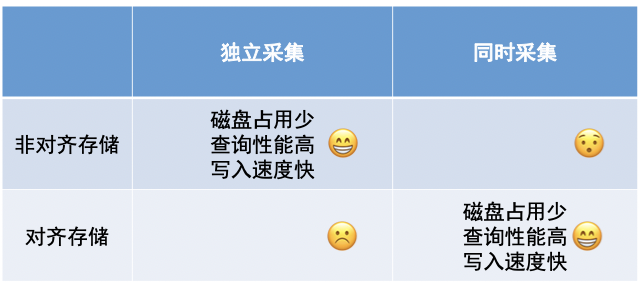
通常,在使用关系数据库管理时序数据时,为了防止表的爆炸,我们只能给每类具有相同传感器的设备建一张表。因此也只能采用对齐存储。
而原生的时序数据库,如 Influxdb,则使用非对齐序列的存储方式,为每个序列存储一列时间。这是国外流行的时序数据库相比关系数据库做出的一个很大的改动,也因此在很多场景中有明显的性能优势。
至此,时序数据的存储上,就分成了两个阵营,一方是原生时序数据库(如 Influxdb),使用非对齐存储,一方是使用关系模型的数据库(如 TimescaleDB、OpenTSDB),使用对齐存储。
两方阵营,能不能扩展自己的存储模型呢?
如果想在原生时序数据库中支持对齐存储,首先需要定义好功能,怎么支持,在哪一层支持,然后才能继续探索。
如果想在关系数据库中支持非对齐存储,有一个方式比较容易实现,就是一个序列一张表,但是会表爆炸。
能不能更进一步
那么,IoTDB 也作为原生时序数据库,能不能同时支持两种存储方式,适配不同的采集方式呢?
答案是可以的。
首先介绍一下 IoTDB 的数据模型,元数据树(类似关系数据库中的表结构,属于Schema)的每个叶子节点对应一个传感器,也就对应一个时间序列,倒数第二层是设备。
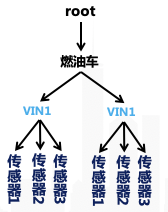
非对齐存储很简单,每个叶子节点对应的时间序列都独立管理,存储一列时间。Apache IoTDB 最开始就支持了非对齐存储,以适配大多数时序场景。
那么,对齐存储怎么支持呢?
想支持对齐存储,就要有一个包含多个传感器的概念,而 IoTDB 的数据模型里的设备,刚好满足这一前提。
因此,我们很自然地将这个概念放在了设备上,让用户可以指定每个设备采用对齐存储还是非对齐存储,系统内部的实现改造也比较优雅。
这也是为什么 IoTDB 的数据模型叫原生物联网数据模型。
IoTDB 数据模型可以总结为下图:不同的设备可以指定不同的存储模型。
至此,Apache IoTDB 社区完成了一次新的探索!

















 2936
2936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









