



奇技指南
HDFS作为运行在通用硬件上的分布式文件系统,和现有的分布式文件系统既有很多的共同点,也存在很多的差异。本文从HDFS是什么开始介绍,包括了HDFS架构、HDFS的读写、各个组件的作用、具体操作以及优缺点。给出了HDFS在分布式存储上的具体方案,可以使读者快速、清晰的理解HDFS系统。。
本文转载自360云计算公众号。作者:于桐
主要内容
HDFS是什么?是干什么用的?
HDFS的架构是怎么样的?
HDFS的怎样进行读写?副本怎样放置?
HDFS各个组件的作用?
HDFS的文件操作命令有哪些?
HDFS的优缺点是什么?
引言
有这样一个需求:
由于公司某业务mysql服务器过保,为防止数据丢失,需要备份mysql数据库,这些库目前已经只读,每个库约1.5T,大概有130个库,共需要200T左右的空间,并且希望数据不易丢失,恢复数据速度快。
部分解决方案:
1)单机存储

有如下问题:
磁盘损坏或机器down机则无法下载;
单块磁盘的读写io会很高;
单块磁盘不能完整存储3个完整的库(存储大文件),只能存储2个,空间部分浪费
平时如果不用做数据恢复,机器cpu、内存等利用率低
2)分布式存储
可选用分布式存储,如HDFS、CEPH、S3等等。
HDFS是什么?是干什么用的?
HDFS(Hadoop Distributed File System)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
首先来看看Hadoop架构,HDFS为Hadoop其他组件提供存储支持。

直观对比Linux文件系统和HDFS文件系统(执行ls命令)。
Linux:
#ls -l
-rw-r--r-- 1 root root 20 Jul 29 14:31 ms-server-download-zzzc_88888.idx
-rw-r--r-- 1 root root 8 Jul 29 14:31 ms-server-download-zzzc_88888.datHDFS:
#hadoop fs -ls /tmp/
-rw-r--r-- 2 xitong supergroup 181335139 2019-07-17 23:00 /tmp/java.tar.gz
-rw-r--r-- 2 xitong supergroup 181335139 2019-07-17 23:00 /tmp/jdk.tar.gz可以看出HDFS和Linux文件系统很类似,都是有权限、文件所属用户、用户所在的组、文件名称等,但是也有不同:HDFS中的第2列表示副本数
HDFS的架构是怎么样的?
HDFS架构如下:

Client:客户端。
NameNode:master,它是一个主管、管理者,存储元数据,存储元数据格式会在后面介绍。
DataNode:slave,NameNode 下达命令,DataNode 执行操作并存储实际数据。
SecondaryNameNode:和NameNode不是主备关系。当NameNode挂掉的时候,它并不能马上替换NameNode提供服务。主要作用会在后面介绍。
HDFS怎样进行读写
写文件
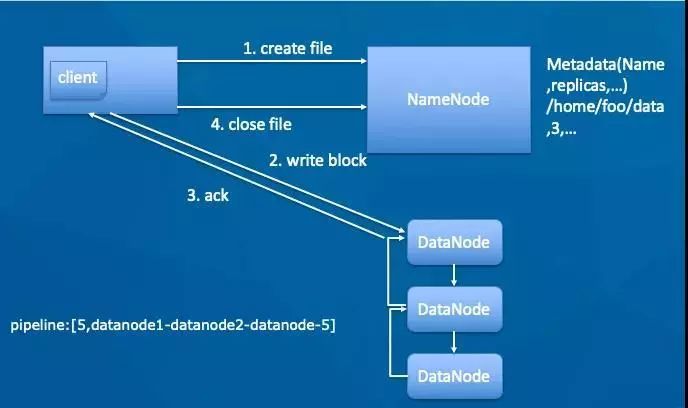
客户端调用create方法,创建一个新的文件;NameNode会做各种校验,比如文件是否已经存在,客户端是否有权限等。
如果校验通过,客户端开始写数据到DN(DataNode),文件会按照block大小进行切块,默认128M(可配置),DataNode构成pipeline管道,client端向输出流对象中写数据,传输的时候是以比block更小的packet为单位进行传输,packet又可拆分为多个chunk,每个chunk都携带校验信息。
每个DataNode写完一个块后,才会返回确认信息,并不是每个packet写成功就返回一次确认。
写完数据,关闭文件
读文件

客户端调用open方法,打开一个文件
获取block的location,即block所在的DN,NN(NameNode)会根据拓扑结构返回距离客户端最近的DN。
客户端直接访问DN读取block数据并计算校验和,整个数据流不经过NN。
读取完一个block会读取下一个block。
所有block读取完成,关闭文件
副本放置

以经典的3副本为例(黄色方框表示客户端,绿色表示要写的block),Hadoop早期版本采用左边的放置策略,后期版本采用右边的放置策略放置副本。
图左:
副本1:同机架的不同节点。
副本2:同机架的另一个节点。
副本3:不同机架的另一个节点。
如果还有其他副本:随机。
图右:
副本1:同Client的节点。
副本2:不同机架的节点。
副本3:同第2副本相同机架的不同节点。
如果还有其他副本:随机。
两种策略的故障域都为机架,新版相对于旧版本,当本客户端再次读取新写的数据时,直接从本地读取,这样延迟最小,读取速度最快。
HDFS各个组件的作用?
先大致看下启动流程:
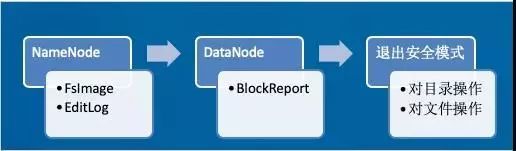
启动NameNode,读取FsImage元数据镜像文件,加载到内存中;读取EditLog日志文件,加载到内存中,使当前内存中元数据信息与上次关闭系统时保持一致
启动DataNode,向NameNode注册,并向NameNode发送BlockReport。
退出安全模式后,Client可以对HDFS进行目录创建、文件上传等操作,改动的目录结构会记录在EditLog中,NameNode的内存中的目录结构也会改变。
NameNode
管理 HDFS 的命名空间。
管理数据块(Block)映射信息。
配置副本策略。
处理客户端读写请求。
Fsimage是一个二进制文件,格式如下:

FsImage文件第1行为image head,里面包含image的版本、文件和目录的个数等;第2行为一个目录格式(如果是目录,就是这种格式),包含了目录的路径、副本数、权限等,目录的blocksize都为0;第3行为一个文件格式(如果是文件,则在FsImage存储的格式),文件和目录格式包含的字段差不多,多了block信息;通过加载此文件和EditLog日志文件来构建整个文件系统的目录结构。
通过观察FsImage文件,里面并没有block和DN的对应关系,它是如何查到块所对应的DN的呢?
block和DN的对应关系并没有实际持久化,而是通过DN向NN(NameNode)汇报,此过程为BlockReport。通过blockReport构建BlocksMap的结构如下:

在blockInfo中保存了block所在的DN信息
SecondaryNameNode
和NameNode并非主备关系,而是辅助NN进行合并FsImage和EditLog并起到备份作用。

HDFS文件操作命令有哪些?
和Linux操作文件类似,只列出常见几个,和Linux命令的功能也是类似的,如:cp即拷贝,rm即删除等等
#hadoop fs [cat|chgrp|chmod|chown|count|cp|df|get|ls|put|mv|rm|mkdir|tail]
在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态、获取文件的block块信息和位置信息等。
#hdfs fsck [move|delete|files|blocks|locations|racks|blockId]
HDFS的优缺点是什么?
最后根据以上内容总结HDFS优缺点如下:
优点:
支持海量数据的存储。
检测和快速应对硬件故障。
流式数据访问。
简化的一致性模型。
高容错性。
商用硬件。
缺点:
不能做到低延迟数据访问。
不适合大量的小文件存储。
不支持修改文件(HDFS2.x开始支持给文件追加内容)。
不支持用户的并行写。
hadoop2.x新特性 引入了NameNode Federation,解决了横向内存扩展;引入了Namenode HA,解决了namenode单点故障。
相关文章
http://hadoop.apache.org/docs/r1.2.1/hdfs_design.html
最新活动
随着运维工作从规模和复杂度多方面的爆炸式增长,传统的运维手段已经无法满足如今业务系统运维管理的需求。AI 技术日趋成熟,智能运维(AIOps)应运而生,给运维行业带来了很多的变革和机会,并逐渐成为一种新的发展趋势。
精彩内容都在360互联网技术训练营第18期——AIOps落地实践探索
识别下方二维码或点击阅读原文,立即报名

界世的你当不
只做你的肩膀
无

360官方技术公众号
技术干货|一手资讯|精彩活动
空·

更多精彩内容“阅读原文”
点击“在看”了嘛

















 3086
3086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









