






前期准备:
三个文件,file1.txt,file2.txt,file3.txt
内容如下
file1.txt
Mapreduce is easy。file2.txt
Mapreduce is powerful easy。
file3.txt
Hello Mapreduce is easy,and bye。接下来介绍一下倒排索引的内容:
倒排索引就是根据关键字反过来排查文章,类似于百度搜索关键字然后搜索出来的,都是包含关键字的文章。
带有倒排索引的文件被称为倒排索引文件。
倒排索引案例的实现:
首先是Map阶段的实现:
大概思路是,先生成一个对象用于储存单词还有文档的名称,然后重写map方法,将单词和文件名以键值对的方法进行输出,方便下一阶段Combine的实现。
package cn.itcast.invertedlndex;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class InvertedlndexMapper extends Mapper<LongWritable, Text, Text, Text> {
private static Text keyInfo = new Text();
private static final Text valueInfo = new Text("1");
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
String line = value.toString();
String[] fields = StringUtils.split(line," ");
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
for (String field : fields){
keyInfo.set(field + ":" + fileName);
context.write(keyInfo, valueInfo);
}
}
}
Combine阶段的实现,对每个单词进行词频统计,大致思路是,创建一个四有对象,来基本上确定键值对的格式,然后重写reduce放大没见过键值对的格式设置为单词,将键值对的格式改为:文档名称:单词次数。
package cn.itcast.invertedlndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedlndexCombiner extends Reducer<
Text, Text, Text, Text> {
private static Text info = new Text();
@Override
protected void reduce (Text key, Iterable<Text>values, Context context)
throws IOException, InterruptedException{
int sum = 0;
for (Text value : values){
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
key.set(key.toString().substring(0,splitIndex));
context.write(key,info);
}
}
reduce阶段的实现
创建一个私有对象,便于存储文档列表,重写reduce方法输出,单词作为键,多个文档名称和词频作为值进行输出。
package cn.itcast.invertedlndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedlndexReducer extends Reducer<Text, Text, Text, Text> {
private static Text result = new Text();
@Override
protected void reduce(Text key, Iterable<Text>values, Context context)
throws IOException, InterruptedException{
String fileList = new String();
for (Text value : values){
fileList += value.toString() + ";";
}
result.set(fileList);
context.write(key,result);
}
}
接下来是驱动类的实现,讲述输入输出写到文件。
package cn.itcast.invertedlndex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class InvertedlndexDriver {
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name","yarn");
Job job = Job.getInstance(conf);
job.setJarByClass(InvertedlndexDriver.class);
job.setMapperClass(InvertedlndexMapper.class);
job.setCombinerClass(InvertedlndexCombiner.class);
job.setReducerClass(InvertedlndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
接下来就是在idea中 对项目进行封装。
在idea的最右侧,有一个m的标志,点一下之后展开项目,之后,点击 Lifecycle也就是生命周期。之后双击下面的package选项,对项目进行封装。
封装完成后
在运行底部就会出现封装信息。
一般是在自己根目录的地方封装成jar包,大家可以自行去项目的根目录查看。
当然在下面的控制台也会输出相应的路径信息,大家可以自行查看。
接下来在hadoop01中的export/data路径下,上传我们封装好的jar包。
首先切换到data目录。
cd /export/data然后输入rz
进行jar包的上传。
封装好的jar包的位置在你项目目录的target文件下。
上传成功之后就可以进行下一步。
之后就是在hadoop01的虚拟机下,创建Invertedlndex目录,并且在Invertedlndex下创建input目录。
那么接下来介绍两个思路:
第一个,在终端的地方使用命令进行创建:
(请确保一下自己是管理员权限)
sudo mkdir -p /Invertedlndex/input创建完成后,切换到这个目录
cd /Invertedlndex/input然后!输入rz
进行文件的上传。
第二个:
打开自己的9870端口,然后手动创建一个,创建文件的图标是create绿色按钮旁边的那个小文件夹图标。多打了个i,已改正。
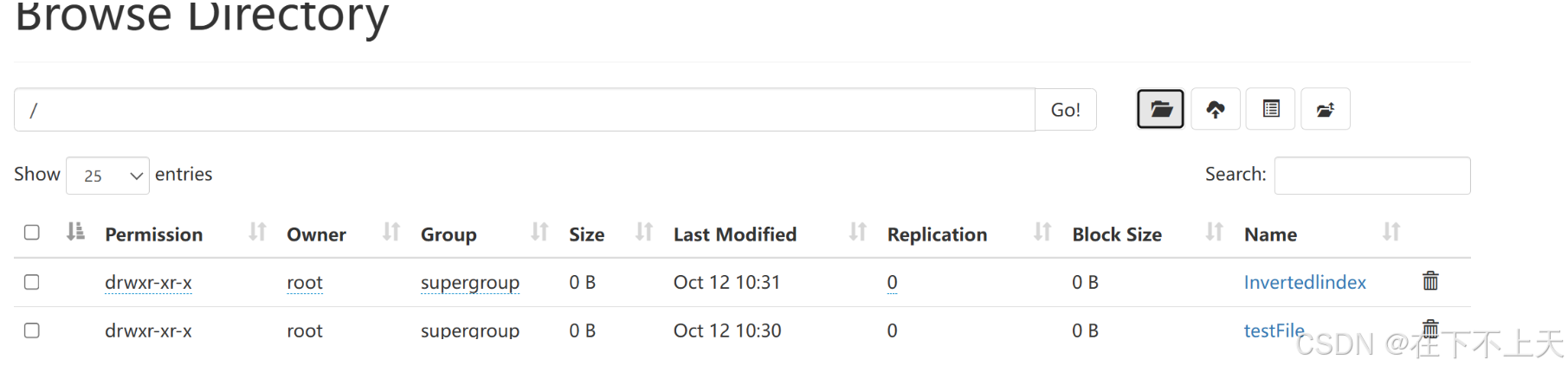
就创建好了,如果过程顺利请进行下一步,
如果不顺利,出现了类似于下面这种信息的报错,可能是大家之前的虚拟机出现了问题,大家进行了一个恢复快照的操作。
这会导致图形化界面和自己虚拟机的日志信息不一致,会弹出风险提示,
Cannot create directory /Invertedlindex. Name node is in safe mode. The reported blocks 5 needs additional 1 blocks to reach the threshold 0.9990 of total blocks 7. The minimum number of live datanodes is not required. Name node detected blocks with generation stamps in future. This means that Name node metadata is inconsistent. This can happen if Name node metadata files have been manually replaced. Exiting safe mode will cause loss of 2190376 byte(s). Please restart name node with right metadata or use "hdfs dfsadmin -safemode forceExit" if you are certain that the NameNode was started with the correct FsImage and edit logs. If you encountered this during a rollback, it is safe to exit with -safemode forceExit. NamenodeHostName:hadoop01那么解决的方法是,大家回到hadoop01的终端,输入
hdfs dfsadmin -safemode forceExit可以强行退出hadoop的安全模式,就可以继续对文件夹进行操作了。
回归正题,
在创建完文件夹之后,再创建input文件夹,选择文件上传到刚刚创建的文件夹。
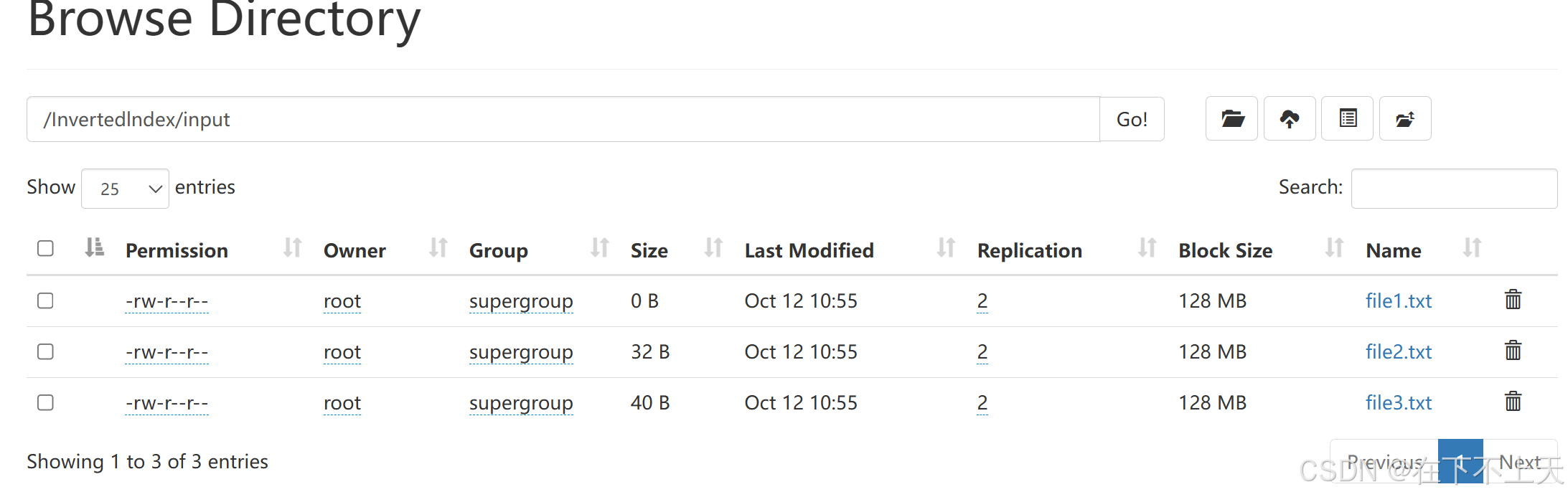
创建完成之后
大家请cd到data文件夹、
cd /export/data之后输入下面的命令:
hadoop jar HadoopDemo-1.0-SNAPSHOT.jar \cn.itcast.invertedlndex.InvertedlndexDriver /Invertedlndex/input /Invertedlndex/output接下来给大家详细的介绍一下这个命令的组成。
//
首先,开头的hadoop jar不必理会,是固定格式,
后面的 HadoopDemo-1.0-SNAPSHOT.jar,这个是大家打包的名字,可以根据实际情况来进行替换。
再下面的\cn.itcast.invertedlndex.InvertedlndexDriver ,是我们上传项目的InvertedlndexDriver 类的包里的路径,也可以根据自己的实际情况进行修改。
/Invertedlndex/input是我们自己新建的文件夹,确保文件输入的路径。
/Invertedlndex/output不用自己创建,由系统自己输出的路径,可以在这个地方查看结果。
以上就是这个命令的全部组成,大家可以根据自己的情况进行修改和调整。
///
如果出现报错,不要慌张,也许是你的jar包没有上传成功,也许是你的名称拼写或者包名什么的有错误,也或许是你的文件名错误,路径错误,谢姐决定成败。
大家可以倒回去仔细检查一下这些问题。
如果上传成功了还没有成功还嗷嗷的报错的话。
重启你的虚拟机,然后
hdfs dfsadmin -safemode forceExit这个命令是使hadoop退出安全模式,可以解决自己回复快照问题,前面解释过,这里不再进行赘述。
之后,虔诚的回到桌面刷新一下,虔诚一些,默念我一定会成功的,拜托了!
再次输入,之后就可以等待好消息了。
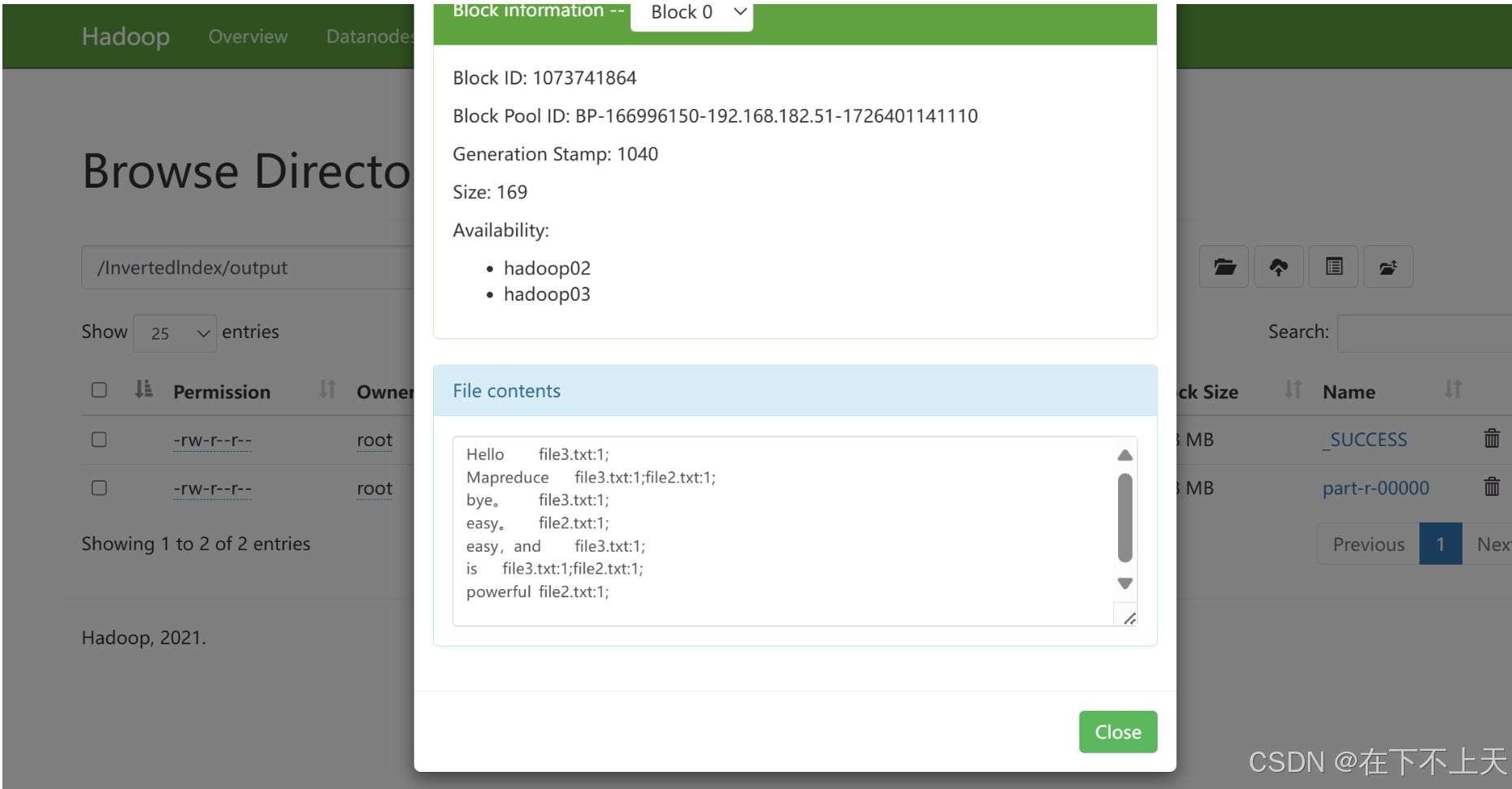
下面依旧是对输出结果进行展示~
有问题可以在评论区留言,看到的话会回复,喜欢的话,给个点赞支持一下~谢谢各位

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









