






开始之前,一定要!启动集群!!!!
启动集群!启动集群!不会启动的去我之前的文章里找!!!
简介
TopN分析法是咋研究对象时候按照某个指标进行正序或者倒序排序,取其中最大的N个数据并且对这N个数据
进行正序或者倒序输出分析的方法。
接下来需要大家做一下准备工作。
需要的工具:
hadoop集群
idea
maven
还有一个配置文件,
配置文件:hqk8
这个文件大家自己想配置的话,在下面也有内容,不喜欢的话,大家可以直接进行下载。
这三个不会配置的可以去作者之前的帖子进行查看。
首先大家需要在D盘新建一个文件夹,文件夹的名称为topN,然后在topN里创建input文件夹,在input文件夹里创建num.txt文件。
num.txt文件内容
10 3 8 7 6 5 1 2 9 4
11 12 17 14 15 20
19 18 13 16当然,自己随便写也行。
也可以自定义,如果是自定义,在后面代码的目录部分需要自行修改。
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
注意!!!这里给新建项目需要配置文件的同学看的,如果是在原来的项目新建ok了,依赖等等都破诶之完毕,可以忽略下面的信息,直接跳转到3.1
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
那么下来需要进行pom文件的配置。
操作之前记得打开集群,不然会报错。
在下面的代码里,记得在<version>那里修改一下自己版本,作者的是3.3.1版本,如果是别的版本要记得修改。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" >
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>HadoopDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>在配置完pom.xml文件之后,需要打开idea,首先新建一个txt,编辑完内容之后再重命名,就可以,不配置log4j文件,运行的时候可能会报错。
文件名:
log4j.properties
log4j.rootLogger=debug, stdout, R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
# Pattern to output the caller's file name and line number.
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=example.log
log4j.appender.R.MaxFileSize=100KB
# Keep one backup file
log4j.appender.R.MaxBackupIndex=5
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
在配置完文件之后,需要把配置文件拖到src/main/resources这个目录下面,
之后开始进行案例实现。
可以在上一个文章的基础上,在原本的项目基础上新建一个包。
3.1
直接给大家贴上代码。
1、在Map实现阶段
在这个阶段会读取数据并且进行大小的比对,第二个方法是对数据进行输出。
package cn.itcast.TopN;
import java.io.IOException;
import java.util.TreeMap;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TopNMapper extends Mapper<LongWritable, Text, NullWritable, IntWritable>{
private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, IntWritable>.Context context)throws IOException, InterruptedException {
String line = value.toString();
String[] nums = line.split(" ");
for (String num :nums) {
repToRecordMap.put(Integer.parseInt(num),"");
if(repToRecordMap.size()>5) {
repToRecordMap.remove(repToRecordMap.firstKey());
}
}
}
protected void cleanup (Mapper<LongWritable, Text, NullWritable, IntWritable>.Context context) {
for(Integer i : repToRecordMap.keySet()) {
try {
context.write(NullWritable.get(), new IntWritable(i));
}catch(Exception e) {
e.printStackTrace();
}
}
}
}2、Reduce阶段
在包线新建TopNReducer类。
对算法内容进行简单定,在reduce方法中,判断treemap存放的数据,并且判断最大数据,遍历输出最大的5个数据。
package cn.itcast.TopN;
import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class TopNReducer extends Reducer<NullWritable, IntWritable, NullWritable, IntWritable> {
private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>(new Comparator<Integer>() {
public int compare(Integer a, Integer b) {
return b-a;
}
});
@Override
public void reduce(NullWritable key, Iterable<IntWritable> values, Reducer<NullWritable, IntWritable, NullWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for(IntWritable value :values) {
repToRecordMap.put(value.get(),"");
if(repToRecordMap.size()>5) {
repToRecordMap.remove(repToRecordMap.firstKey());
}
}
for(Integer i:repToRecordMap.keySet()) {
context.write(NullWritable.get(), new IntWritable(i));
}
}
}3、驱动类的实现
数据的输出结果和路径,注意,不要自己创建output目录!!!只创建input就好!!!
package cn.itcast.TopN;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
public class TopNDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TopNDriver.class);
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
//设置输出类型
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path("D:\\topN\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\topN\\output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
之后,既可以开心的进行运行了。
结果展示
结果展示:
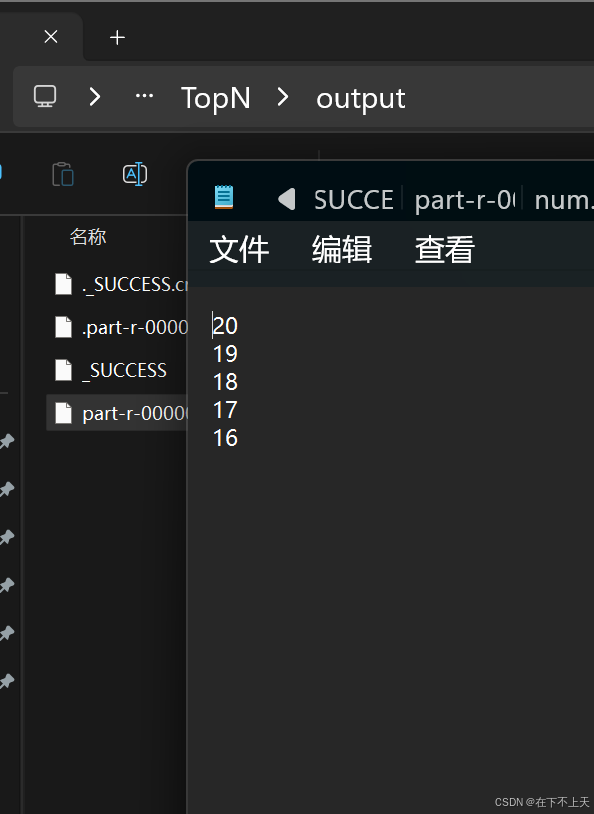
展示完毕,有问题可以在评论区里进行提问,看到会给大家解释~

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









