



 本文介绍了多个基于多模态人工智能的创新方法。如Make - it - Real利用MLLMs为3D物体赋予真实材质;ConsistentID解决人像生成的身份一致性问题;还包括自动图像上色、图像风格定制、视频转音频生成及多GPU扩展NeRFs等方法,展示了多模态技术在不同领域的应用。
本文介绍了多个基于多模态人工智能的创新方法。如Make - it - Real利用MLLMs为3D物体赋予真实材质;ConsistentID解决人像生成的身份一致性问题;还包括自动图像上色、图像风格定制、视频转音频生成及多GPU扩展NeRFs等方法,展示了多模态技术在不同领域的应用。
本文首发于公众号:机器感知
Make-it-Real、ConsistentID、Automatic Colorization、Video-to-Audio

Make-it-Real: Unleashing Large Multimodal Model's Ability for Painting 3D Objects with Realistic Materials

Physically realistic materials are pivotal in augmenting the realism of 3D assets across various applications and lighting conditions. However, existing 3D assets and generative models often lack authentic material properties. Manual assignment of materials using graphic software is a tedious and time-consuming task. In this paper, we exploit advancements in Multimodal Large Language Models (MLLMs), particularly GPT-4V, to present a novel approach, Make-it-Real: 1) We demonstrate that GPT-4V can effectively recognize and describe materials, allowing the construction of a detailed material library. 2) Utilizing a combination of visual cues and hierarchical text prompts, GPT-4V precisely identifies and aligns materials with the corresponding components of 3D objects. 3) The correctly matched materials are then meticulously applied as reference for the new SVBRDF material generation according to the original diffuse map, significantly enhancing their visual authenticity. Make-it......
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving

Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consis......
Multimodal Semantic-Aware Automatic Colorization with Diffusion Prior

Colorizing grayscale images offers an engaging visual experience. Existing automatic colorization methods often fail to generate satisfactory results due to incorrect semantic colors and unsaturated colors. In this work, we propose an automatic colorization pipeline to overcome these challenges. We leverage the extraordinary generative ability of the diffusion prior to synthesize color with plausible semantics. To overcome the artifacts introduced by the diffusion prior, we apply the luminance conditional guidance. Moreover, we adopt multimodal high-level semantic priors to help the model understand the image content and deliver saturated colors. Besides, a luminance-aware decoder is designed to restore details and enhance overall visual quality. The proposed pipeline synthesizes saturated colors while maintaining plausible semantics. Experiments indicate that our proposed method considers both diversity and fidelity, surpassing previous methods in terms of perceptual realism......
MuseumMaker: Continual Style Customization without Catastrophic Forgetting

Pre-trained large text-to-image (T2I) models with an appropriate text prompt has attracted growing interests in customized images generation field. However, catastrophic forgetting issue make it hard to continually synthesize new user-provided styles while retaining the satisfying results amongst learned styles. In this paper, we propose MuseumMaker, a method that enables the synthesis of images by following a set of customized styles in a never-end manner, and gradually accumulate these creative artistic works as a Museum. When facing with a new customization style, we develop a style distillation loss module to transfer the style of the whole dataset into generation of images. It can minimize the learning biases caused by content of images, and address the catastrophic overfitting issue induced by few-shot images. To deal with catastrophic forgetting amongst past learned styles, we devise a dual regularization for shared-LoRA module to optimize the direction of model update......
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
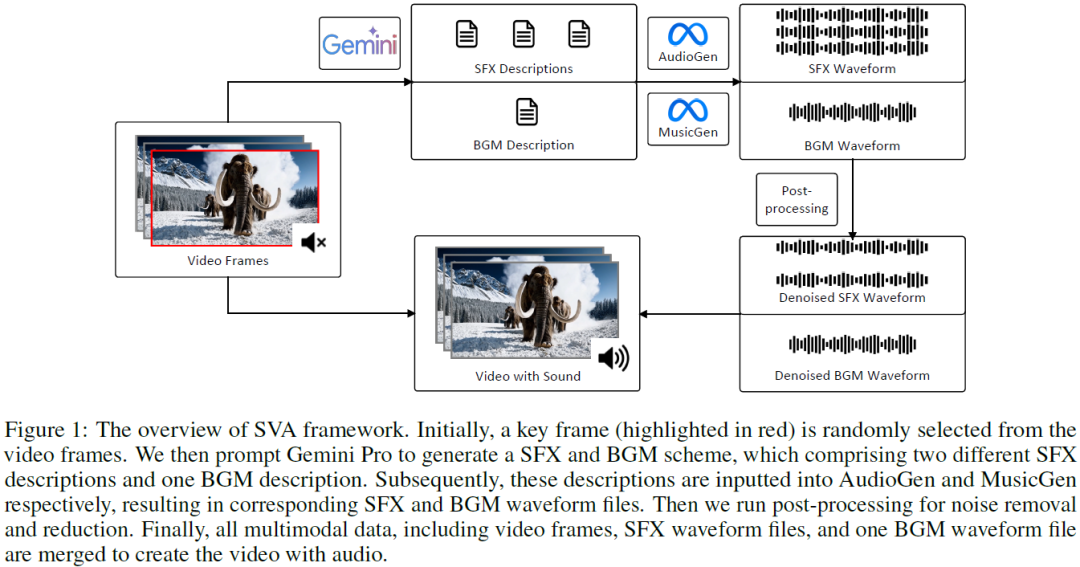
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/. ......
NeRF-XL: Scaling NeRFs with Multiple GPUs

We present NeRF-XL, a principled method for distributing Neural Radiance Fields (NeRFs) across multiple GPUs, thus enabling the training and rendering of NeRFs with an arbitrarily large capacity. We begin by revisiting existing multi-GPU approaches, which decompose large scenes into multiple independently trained NeRFs, and identify several fundamental issues with these methods that hinder improvements in reconstruction quality as additional computational resources (GPUs) are used in training. NeRF-XL remedies these issues and enables the training and rendering of NeRFs with an arbitrary number of parameters by simply using more hardware. At the core of our method lies a novel distributed training and rendering formulation, which is mathematically equivalent to the classic single-GPU case and minimizes communication between GPUs. By unlocking NeRFs with arbitrarily large parameter counts, our approach is the first to reveal multi-GPU scaling laws for NeRFs, showing improvemen......


















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









