



 本文介绍了几种创新的AI技术,包括利用多大语言模型的协作竞争代理(CCA)进行图像编辑,以及ContractiveDiffusionProbabilisticModels在生成模型中的应用。SpeechGPT-Gen通过改进的信息处理方法提升了语音生成效率,尤其是在文本到语音和语音对话方面表现出色。
本文介绍了几种创新的AI技术,包括利用多大语言模型的协作竞争代理(CCA)进行图像编辑,以及ContractiveDiffusionProbabilisticModels在生成模型中的应用。SpeechGPT-Gen通过改进的信息处理方法提升了语音生成效率,尤其是在文本到语音和语音对话方面表现出色。
本文首发于公众号:机器感知
SpeechGPT-Gen;使用Agents编辑图像;多模态扩散模型图像生成;
CCA: Collaborative Competitive Agents for Image Editing
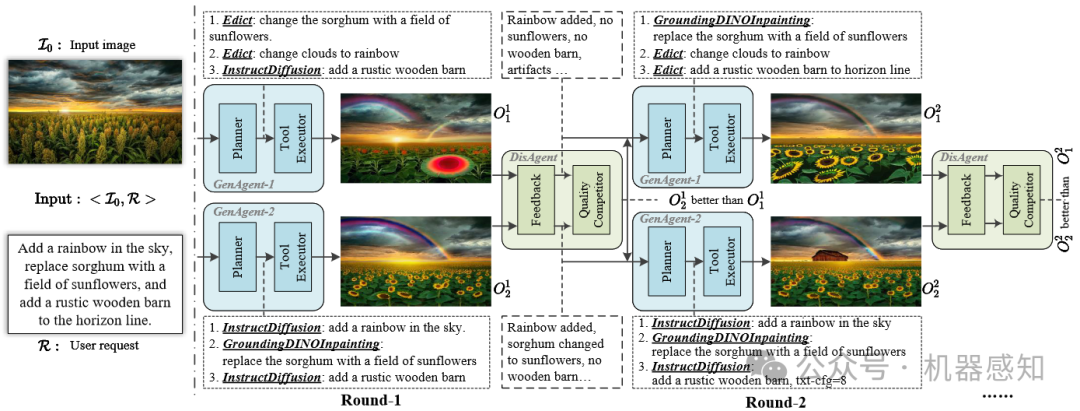
This paper presents a novel generative model, Collaborative Competitive Agents (CCA), which leverages the capabilities of multiple Large Language Models (LLMs) based agents to execute complex tasks. Drawing inspiration from Generative Adversarial Networks (GANs), the CCA system employs two equal-status generator agents and a discriminator agent. The generators independently process user instructions and generate results, while the discriminator evaluates the outputs, and provides feedback for the generator agents to further reflect and improve the generation results. Unlike the previous generative model, our system can obtain the intermediate steps of generation. This allows each generator agent to learn from other successful executions due to its transparency, enabling a collaborative competition that enhances the quality and robustness of the system's results.
Contractive Diffusion Probabilistic Models
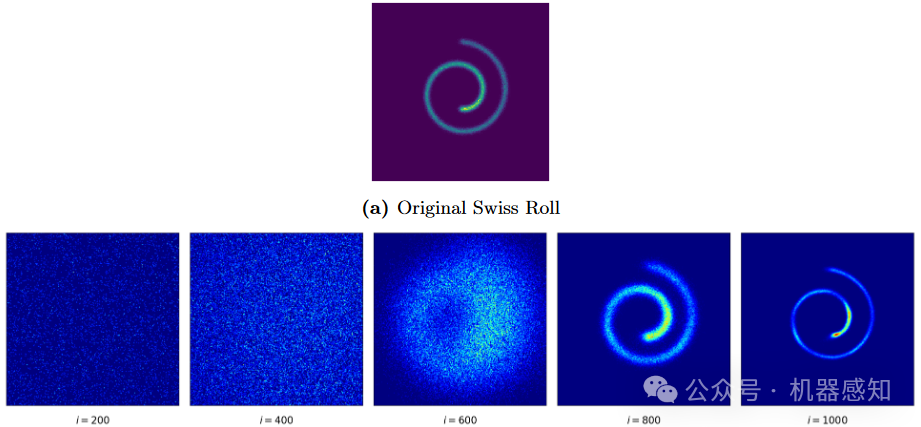
Diffusion probabilistic models (DPMs) have emerged as a promising technology in generative modeling. The success of DPMs relies on two ingredients: time reversal of Markov diffusion processes and score matching. Most existing work implicitly assumes that score matching is close to perfect, while this assumption is questionable. In view of possibly unguaranteed score matching, we propose a new criterion -- the contraction of backward sampling in the design of DPMs. This leads to a novel class of contractive DPMs (CDPMs), including contractive Ornstein-Uhlenbeck (OU) processes and contractive sub-variance preserving (sub-VP) stochastic differential equations (SDEs). The key insight is that the contraction in the backward process narrows score matching errors, as well as discretization error. Thus, the proposed CDPMs are robust to both sources of error.
UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion

Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes. This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis, and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
SpeechGPT-Gen: Scaling Chain-of-Information Speech Generation
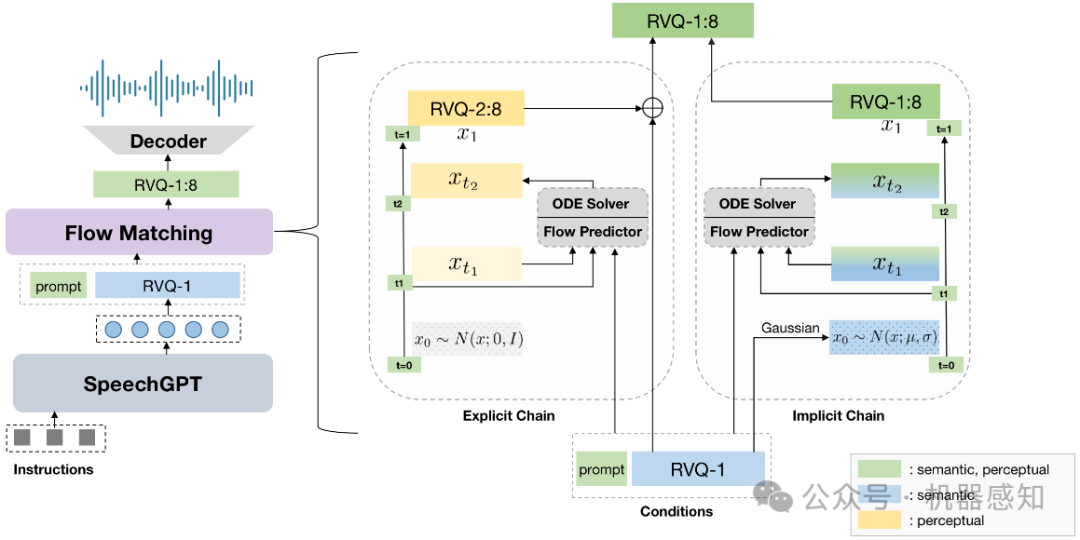
Benefiting from effective speech modeling, current Speech Large Language Models (SLLMs) have demonstrated exceptional capabilities in in-context speech generation and efficient generalization to unseen speakers. However, the prevailing information modeling process is encumbered by certain redundancies, leading to inefficiencies in speech generation. We propose Chain-of-Information Generation (CoIG), a method for decoupling semantic and perceptual information in large-scale speech generation. Building on this, we develop SpeechGPT-Gen, an 8-billion-parameter SLLM efficient in semantic and perceptual information modeling. Extensive experimental results demonstrate that SpeechGPT-Gen markedly excels in zero-shot text-to-speech, zero-shot voice conversion, and speech-to-speech dialogue, underscoring CoIG's remarkable proficiency in capturing and modeling speech's semantic and perceptual dimensions.



















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









