







博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
Python语言、Flask后端框架、vue前端框架、MySQL数据库
基于用户协同过滤推荐算法、基于物品协同过滤推荐算法、
LSTM情感分析、Echarts可视化、Scrapy爬虫框架
功能模块
音乐数据的爬取:爬取歌曲、歌手、歌词、评论
音乐数据的可视化:数据大屏+多种分析图【十几个图】
深度学习之LSTM 音乐评论情感分析
交互式协同过滤音乐推荐: 2种协同过滤算法、通过点击歌曲喜欢来修改用户对歌曲的评分
歌词、乐评的词云、登录、注册、数据爬虫
本系统通过对研究背景意义及相关技术的简介等,从多方面说明了音乐信息分析与用户音乐推荐系统的可行性,并实现了音乐信息分析与用户音乐推荐系统的基本功能。本设计主要完成音乐如下:
(1)基于Scrapy爬虫框架实现对网易云音乐网站上音乐数据的爬取和数据处理。
(2)基于Flask框架完成实现了前后端的交互,完成了音乐推荐系统的推荐和展示功能。
(3)基于 Echarts可视化作图工具,实现了音乐数据可视化功能模块。
(4)基于ItemCF和UserCF算法实现音乐信息的推荐,并测试完善音乐推荐系统功能。
理论知识和真正的实践有很大差距,由于在此之前对于相关技术知识了解的不够深入,缺少实际开发能力,在开发过程中我遇到了数不清的问题。例如:在用户创建时,设置初始化收藏列表默认参数设置为空出错,经查看官方文档发现这样设置的话每个用户初始化时用的是同一个list;由于内存自动回收导致的列表地址越界问题;数据库模型model创建问题,导致数据库连接异常以及查询不到指定信息,从而引起推荐页面一直是空白页面;音乐信息在web页面显示时越界等等,这些问题都在老师同学的帮助和自己查找资料下得到了解决。
在系统开发过程中,我得到了宝贵的实战经验,最重要的是找到了自己在开发时编程的思路以及对数据处理的方法、思想,通过本次音乐信息分析与用户音乐推荐系统的开发,我学会了如何通过实践找到解决问题的方案,提高了自己解决实际问题的能力,我相信这些收获对我以后的发展会有很大帮助。
2、项目界面
(1)数据可视化分析大屏
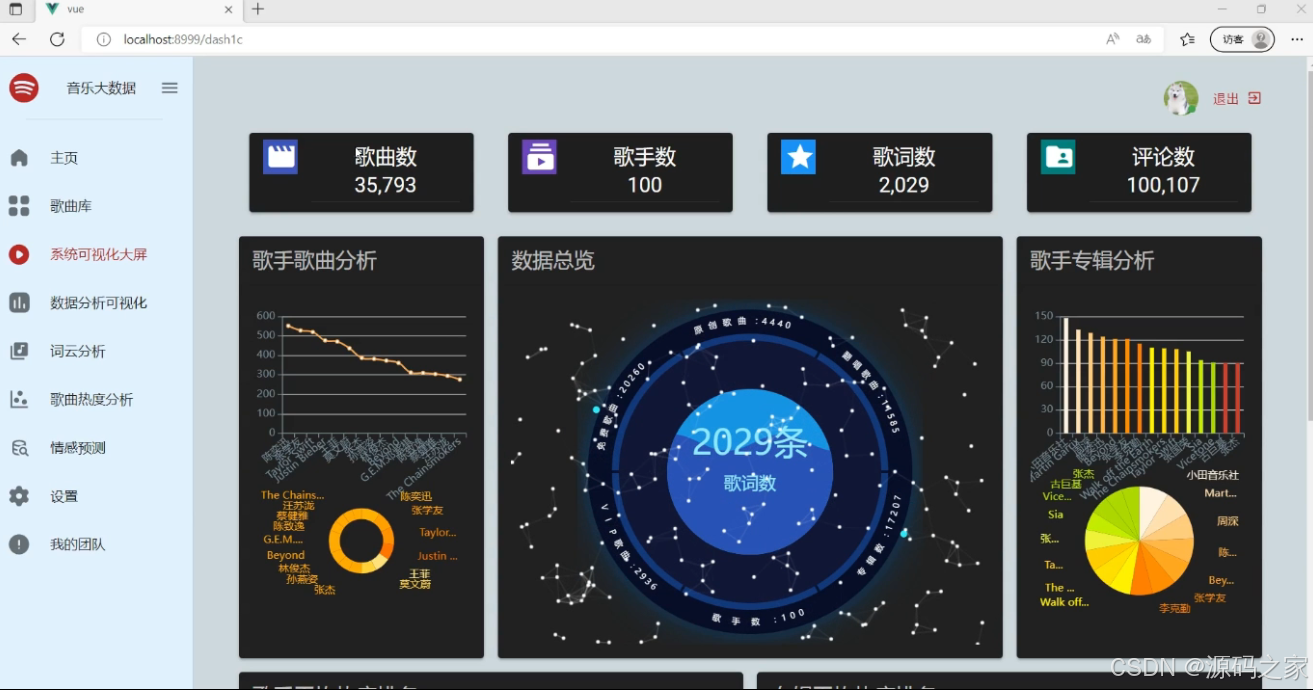
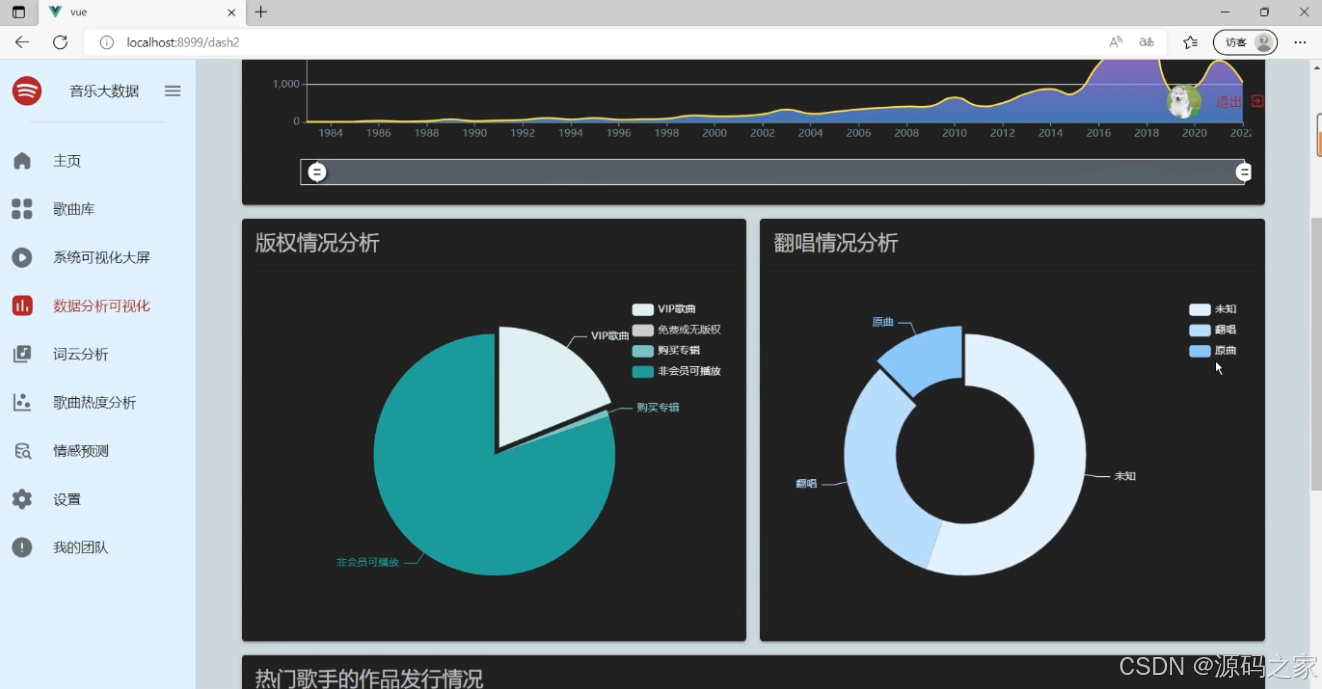
(2)音乐数据可视化分析
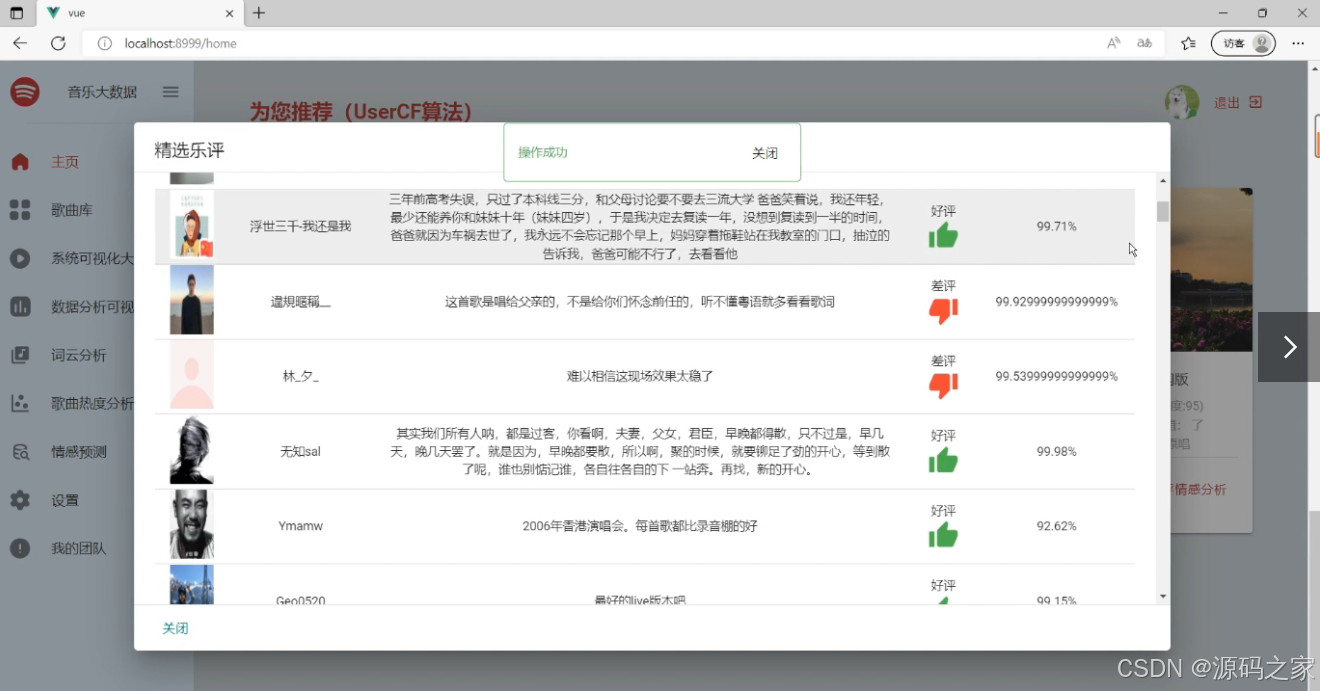
(3)音乐评论情感分析
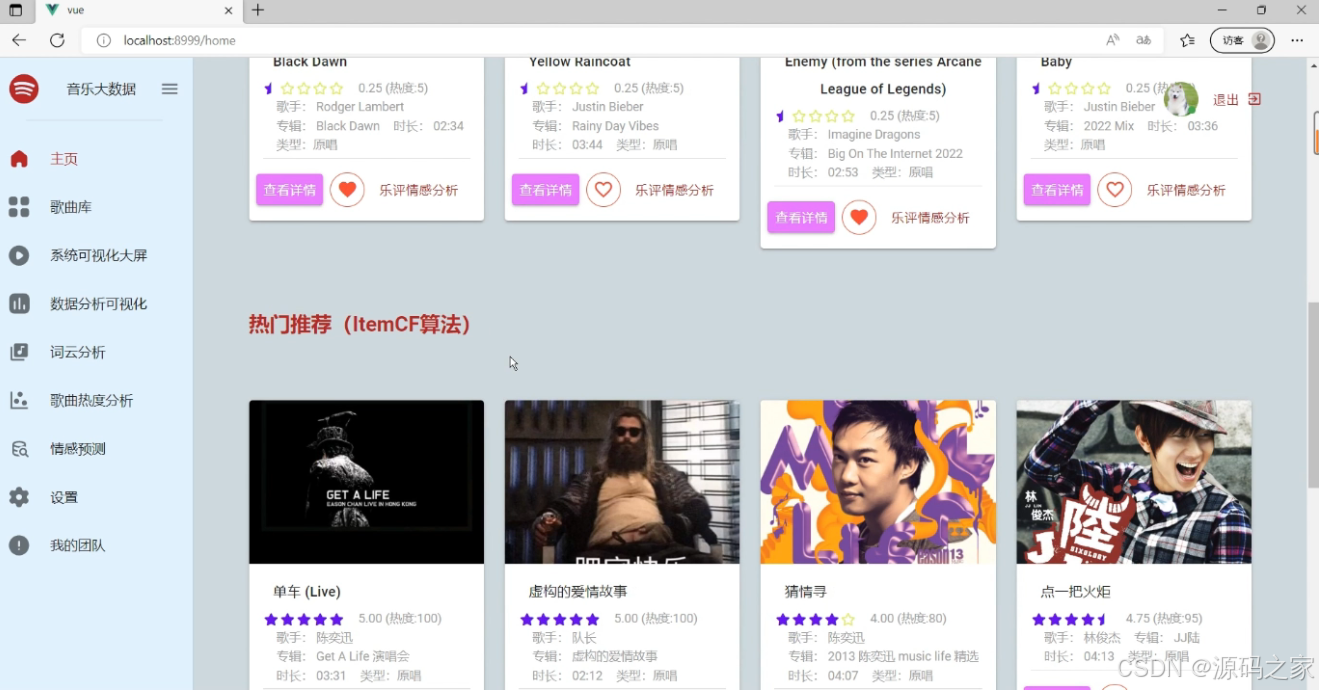
(4)基于协同过滤推荐算法推荐模块
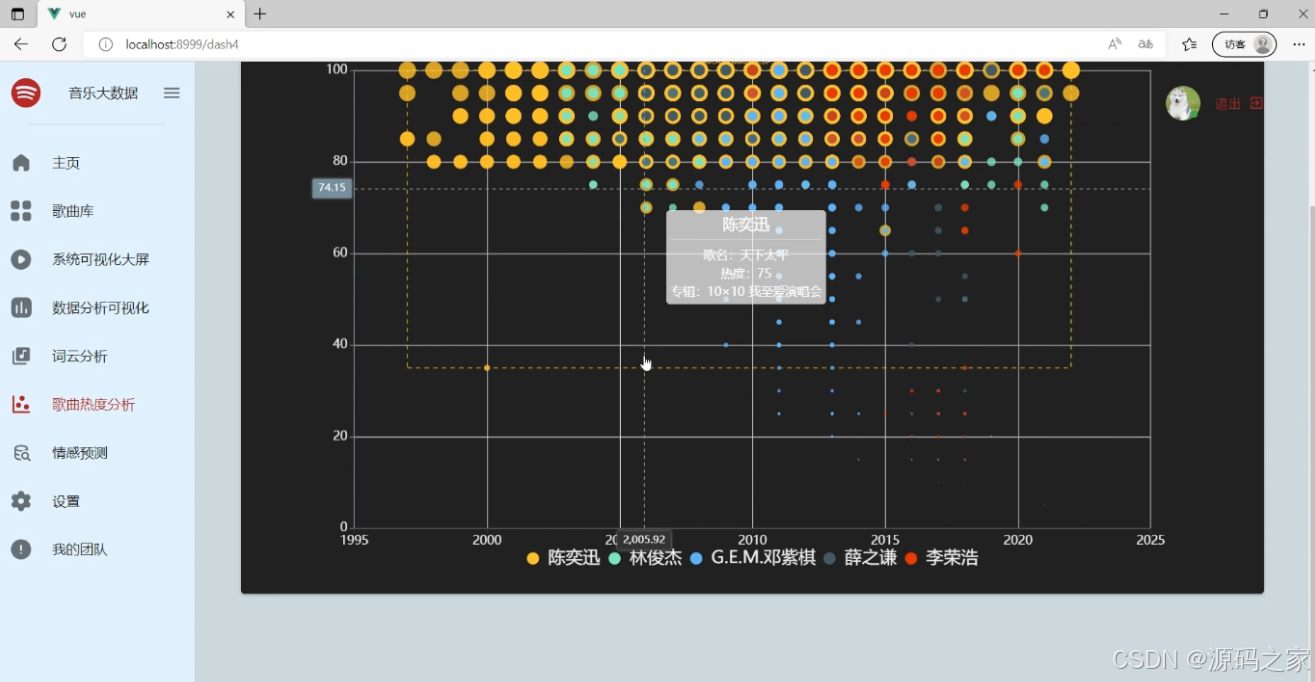
(5)歌曲热度分析
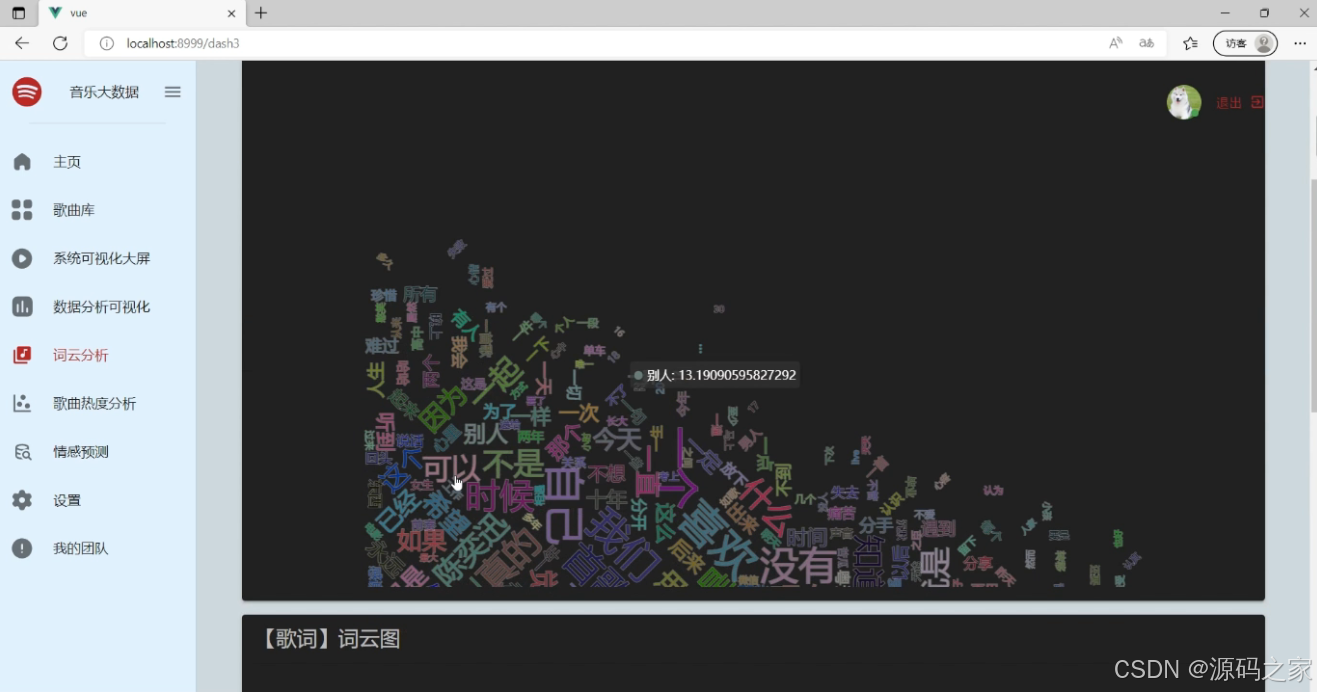
(6)词云分析
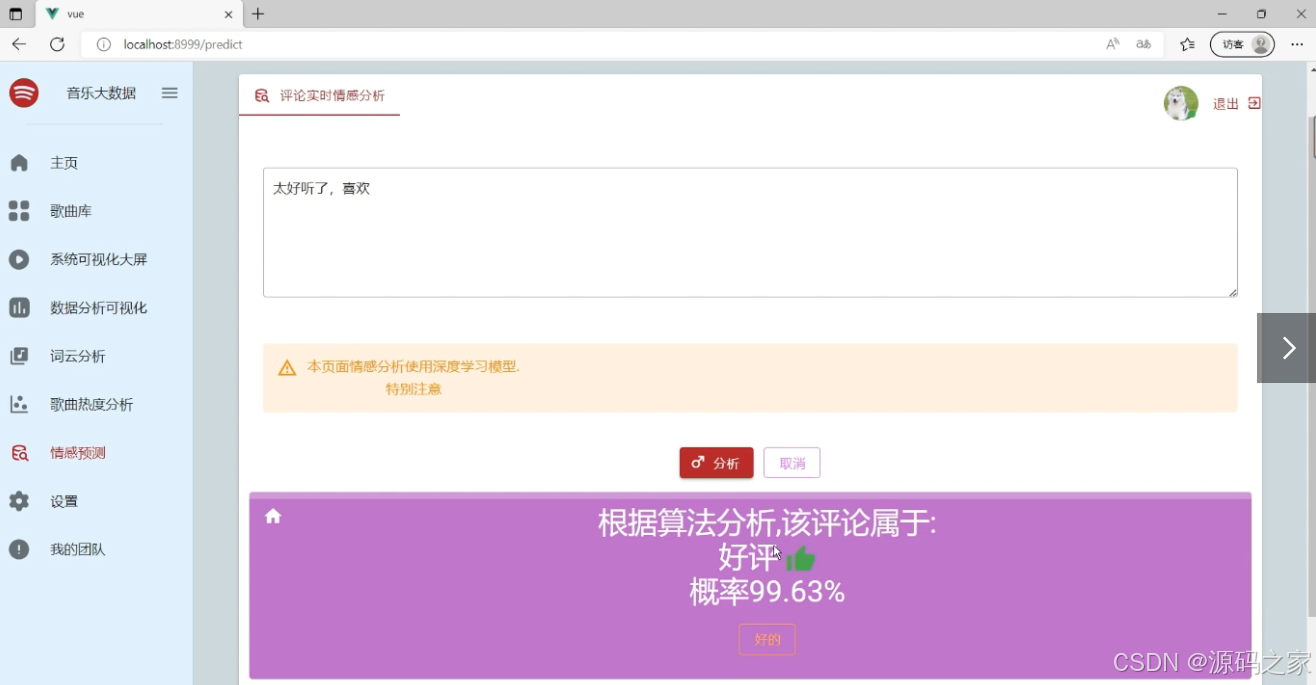
(7)情感分析情感预测模块------LSTM深度学习算法
(8)注册登录模块
(9)项目架构图

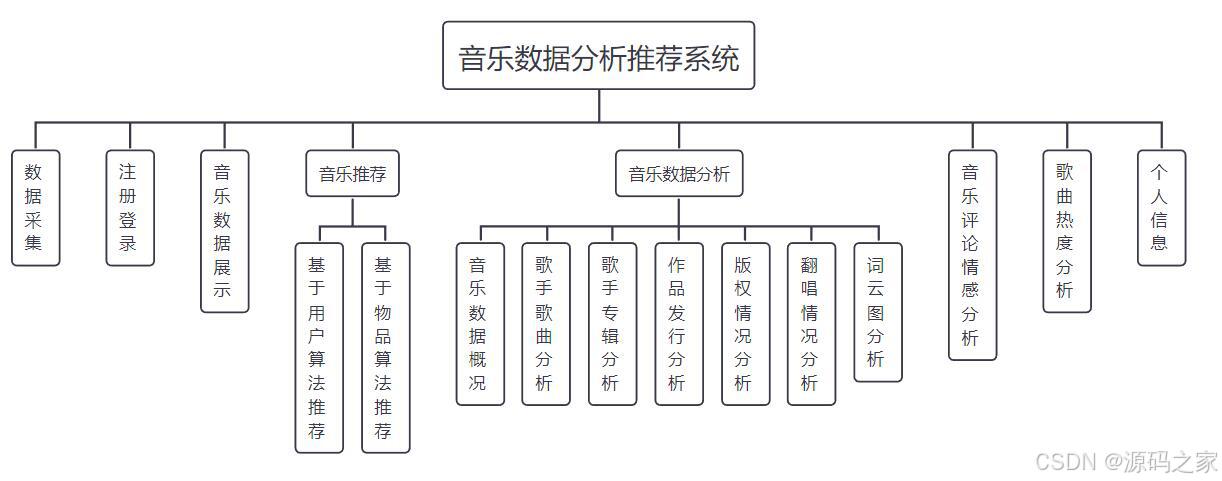
3、项目说明
摘要
多媒体数字技术的不断发展和应用使得数字音乐越来越受到大众的欢迎,与以往的CD、唱片等实体专辑相比,数字音乐更加经济方便,受到了大众的喜爱。因此,移动音乐和在线音乐得到了快速发展。这些音乐平台向用户提供了成千上万的歌曲供用户使用,然而,现在网络上新歌也层出不穷,本就非常庞大的音乐库也变得越来越大,用户想要从这些没有听过的歌曲中找出自己喜欢的歌曲太过的困难,也会耗费大量的时间精力。这些问题在音乐推荐系统出现后得到了很好地解决,音乐推荐系统是通过收集用户的个人属性、行为记录等等,根据用户信息和音乐数据特征,分析并推测出用户的潜在喜好和可能感兴趣的歌曲,主动向用户推荐音乐,解决一些用户的选择困难,节省用户的搜索时间,优化用户的听歌体验,也能提升企业的竞争力。
本文设计并实现了一个基于Python的音乐信息可视化推荐系统,通过爬取网易云网上多种类的有效信息,将多种类的音乐信息的数据存入mysql数据库,再以数据库为连接,然后使用 Python 开源web框架 Flask和vue进行系统搭建,结合协同过滤算法基于音乐信息完成对用户的音乐信息推荐,完成整个爬取以及数据检索到成功进行音乐推荐的网页端操作展示。
【关键词】 协同过滤算法,音乐推荐,Flask框架,可视化
该算法主要用相似统计的方法得到具有相似爱好或者兴趣的相邻用户。基于用户(User-Based)的协同过滤算法首先要根据用户历史行为信息,寻找与新用户相似的其他用户;同时,根据这些相似用户对其他项的评价信息预测当前新用户可能喜欢的项。给定用户评分数据矩阵 R,基于用户的协同过滤算法需要定义相似度函数 s:U×U→R,以计算用户之间的相似度,然后根据评分数据和相似矩阵计算推荐结果。
具体步骤如下:第一步,收集用户信息。收集可以代表用户兴趣的信息。一般的网站系统使用评分的方式或是给予评价,这种方式被称为“主动评分”。另外一种是“被动评分”,是根据用户的行为模式由系统代替用户完成评价,不需要用户直接打分或输入评价数据。电子商务网站在被动评分的数据获取上有其优势,用户购买的商品记录是相当有用的数据。第二步,最近邻搜索(Nearest neighbor search, NNS)。以用户为基础(User-based)的协同过滤的出发点是与用户兴趣爱好相同的另一组用户,就是计算两个用户的相似度。例如:查找 n 个和 A 有相似兴趣用户,把他们对 M 的评分作为 A 对 M 的评分预测。一般会根据数据的不同选择不同的算法, 目前较多使用的相似度算法有 Pearson Correlation Coefficient(皮尔逊相关系数)、Cosine-based Similarity(余弦相似度)、Adjusted Cosine Similarity(调整后的余弦相似度)。
基于项目的协同过滤算法
该以项目为基础的协同过滤方法有一个基本的假设“能够引起用户兴趣的项目,必定与其之前评分高的项目相似”,通过计算项目之间的相似性来代替用户之间的相似性。
具体步骤如下:第一步,收集用户信息。同以用户为基础(User-based)的
协同过滤。第二步,针对项目的最近邻搜索。先计算已评价项目和待预测项目的相似度,并以相似度作为权重,加权各已评价项目的分数,得到待预测项目的预测值。例如:要对项目 A 和项目 B 进行相似性计算,要先找出同时对 A 和 B 打过分的组合,对这些组合进行相似度计算。第三步,产生推荐结果。以项目为基础的协同过滤不用考虑用户间的差别,所以精度比较差。但是却不需要用户的历史数据,或是进行用户识别。对于项目来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而降低了在线计算量,提高推荐效率,尤其是在用户多于项目的情形下尤为显著。
4、核心代码
import json
import os
import random
import time
from flask import Flask, send_from_directory, request
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
from api.alipayApi import payBp
from api.baiduApi import idocr
from api.musicApi import musicBp
from api.orderApi import orderBp
from base.core import JSONEncoder
from base.response import ResMsg
from api.userApi import userBp
import logging
# Flask配置
from deeplearning.predict_lstm import sentimentalAnalysis_single
from utils.smsutil import Sms
app = Flask(__name__)
# 注册用户相关的方法
app.register_blueprint(userBp, url_prefix='/user')
app.register_blueprint(payBp, url_prefix='/alipay')
app.register_blueprint(orderBp, url_prefix='/order') # 订单接口
# 具体业务
app.register_blueprint(musicBp, url_prefix='/music')
# 数据库配置信息
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:123456@localhost:3306/flask_music_b'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['JSON_AS_ASCII'] = False
app.config['SECRET_KEY'] = 'KJDFLSjfldskj'
UPLOAD_FOLDER="upload"
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
basedir = os.path.abspath(os.path.dirname(__file__))
ALLOWED_EXTENSIONS = set(['txt','png','jpg','xls','JPG','PNG','gif','GIF'])
# 日志系统配置
handler = logging.FileHandler('error.log', encoding='UTF-8')
logging_format = logging.Formatter(
'%(asctime)s - %(levelname)s - %(filename)s - %(funcName)s - %(lineno)s - %(message)s')
handler.setFormatter(logging_format)
app.logger.addHandler(handler)
# 返回json格式转换 使用这个的话就不需要每次都写json返回了,简化代码
app.json_encoder = JSONEncoder
# SQLAlchemy 为ORM框架,即用来简化操作数据库的包,具体内容需要学习ORM相关知识
db = SQLAlchemy(app)
# Marshmallow 是用来封装返回SQLAlchemy 的返回结果的,通过这个包可以直接把数据转成JSON,从而返回给前端使用
ma = Marshmallow(app)
# 一个测试的方法,可以测试服务器是否启动了
# @app.route('/test')
# def test(): # put application's code here
# res = ResMsg()
# test_dict = dict(name="zhang", age=19)
# res.update(data=test_dict, code=0)
# return res.data
#
@app.errorhandler(500)
def special_exception_handler(error):
app.logger.error(error)
return '请联系管理员', 500
#判断文件后缀
def allowed_file(filename):
return '.' in filename and filename.rsplit('.',1)[1] in ALLOWED_EXTENSIONS
@app.route('/file/upload', methods=['POST'], strict_slashes=False)
def api_upload():
res = ResMsg()
file_dir=os.path.join(basedir, app.config['UPLOAD_FOLDER'])
if not os.path.exists(file_dir):
os.makedirs(file_dir)
f = request.files['myfile']
if f and allowed_file(f.filename):
fname = f.filename
# fname = secure_filename(f.filename)
print(fname)
ext = fname.rsplit('.', 1)[1]
unix_time = int(time.time())
new_filename = str(unix_time)+'.'+ext
f.save(os.path.join(file_dir, new_filename))
res.update(data=new_filename, code=0)
return res.data
@app.route('/file/idocr', methods=['POST'], strict_slashes=False)
def api_id_ocr():
res = ResMsg()
file_dir=os.path.join(basedir, app.config['UPLOAD_FOLDER'])
if not os.path.exists(file_dir):
os.makedirs(file_dir)
f = request.files['myfile']
if f and allowed_file(f.filename):
fname = f.filename
# fname = secure_filename(f.filename) 有中文这个会有问题
# print(fname)
ext = fname.rsplit('.', 1)[1]
unix_time = int(time.time())
new_filename = str(unix_time)+'.'+ext
f.save(os.path.join(file_dir, new_filename))
idno = idocr(new_filename)[0]
name = idocr(new_filename)[1]
res.update(data=dict(idno=idno,pic=new_filename,name=name), code=0)
return res.data
@app.route('/file/download/<filename>/')
def api_download(filename):
# print('下载..' + filename)
return send_from_directory('upload', filename, as_attachment=False)
#阿里云短信接口
@app.route('/sms/sendSms', methods=['POST'])
def sendSms():
res = ResMsg()
phone = request.json['phone']
code = random.randint(100000, 999999)
response = json.loads(Sms().sendCode(phone, code))
if response['Code'] == "OK":
res.update(msg="发送成功", code=0, data=code)
else:
res.update(msg="发送失败", code=-1)
return res.data
# 深度学习情感分析接口
@app.route('/deeplearning/senti_single', methods=['POST'])
def senti_single():
res = ResMsg()
data = request.json['data']
datas = [data]
print(datas)
result = sentimentalAnalysis_single(datas)
res.update(msg="成功", code=0, data=result)
return res.data
if __name__ == '__main__':
app.run(debug=True,host='0.0.0.0',port=5000)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









