







要分析HTTP请求和响应必然少不了抓包工具,关于抓包工具的设置和下载推荐看抓包工具Fiddler的下载与设置
通过抓包得到的一个HTTP请求
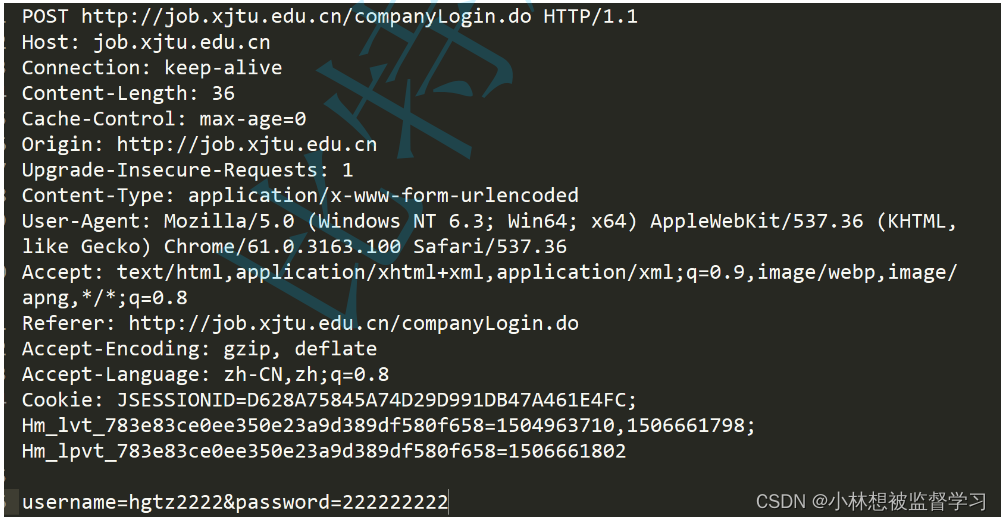
HTTP请求的格式

结构分析
一.请求行

1.post是方法,可以表示一条HTTP请求要进行的操作是什么,post通常表示该HTTP请求要向服务器发送一些数据
我们常见的方法如下:
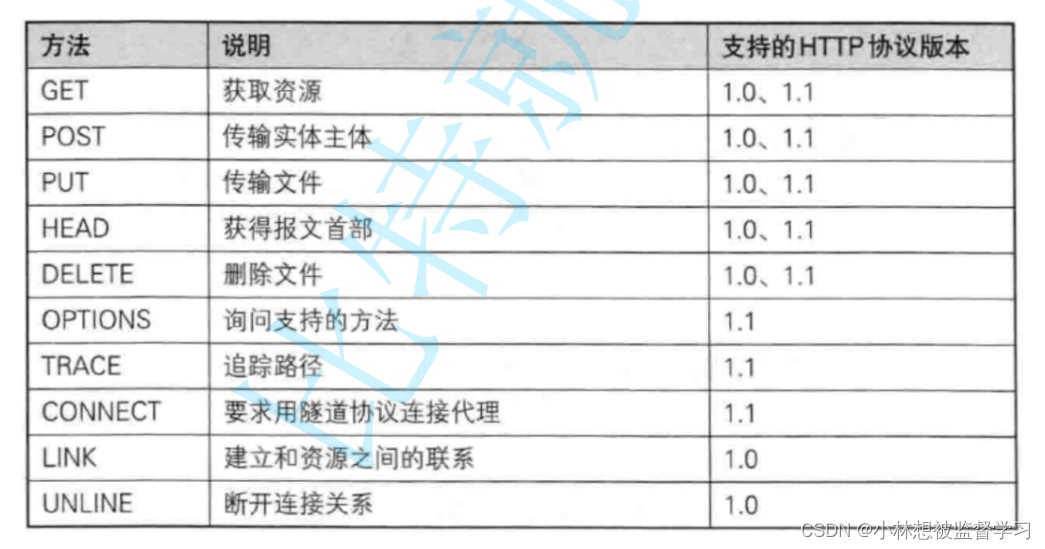 其中get方法(HTTP请求的目的是向服务器获取资源)是HTTP请求中使用最多的,而post其次,其他的方法都很少使用
其中get方法(HTTP请求的目的是向服务器获取资源)是HTTP请求中使用最多的,而post其次,其他的方法都很少使用
get和post方法之间的区别
两者最主要的区别就是:
get将一些要发送给服务器的数据放到URL的选择字符串(query string)中,而post将要发送给服务器的数据放到请求正文(body)中。
数据都是要传给服务器的,所有放在哪里没有实质上的区别,只是放到URL中用户能够看到(输入网址的时候能够看到),放到请求正文(body)中用户看不到而已
但上传数据和登录的时候还是用post居多,因为在登录时要向服务器发送用户名和密码,要是直接放到URL的选择字符串(query string)中,用户能看到,会给用户一种不太安全的错觉(实际上是安全的,因为是密文传输),当要传输的数据较多时,要是直接放到URL中会显得URL特别的长,这样不好
但其实这些都没有什么大不了的,数据放在哪里传输给服务器实际上都一样,因此可以认为 get和post方法没有本质上的区别,只是传输的数据放的位置不一样而已
2.http://job.xjtu.edu.cn/companyLogin.do 是URL(统一资源定位符),这里明确描述出要访问的服务器是哪个,要访问的资源在服务器的哪个位置。
关于URL推荐看认识 URL
3.HTTP/1.1 表示HTTP请求的版本号
二.请求报头(header)
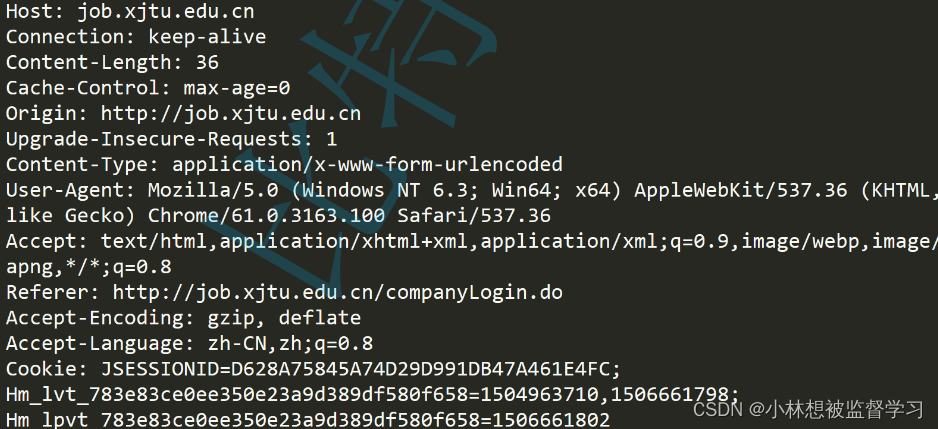 header的整体格式是键值对格式,每个键值对占一行,键和值之间采用冒号分隔,URL选择字符串中的键值对和请求正文(body)中的键值对完全是程序猿自定义的,而请求报头(header)中的键值对,主要是标准规定的(有哪些键,对应的取值有哪些都有规定),也可以有自定义的部分
header的整体格式是键值对格式,每个键值对占一行,键和值之间采用冒号分隔,URL选择字符串中的键值对和请求正文(body)中的键值对完全是程序猿自定义的,而请求报头(header)中的键值对,主要是标准规定的(有哪些键,对应的取值有哪些都有规定),也可以有自定义的部分
请求报头(header)中键的种类很多,这里主要介绍几种常见的
1.Host
表示服务器主机的地址和端口
2.Content-Length
表示请求正文(body) 中的数据长度。如果没有请求正文(body),这个字段就可以没有,如果有请求正文(body),这个字段就必须有,要不然就是非法请求。
为什么有请求正文(body)就必须要有Content-Length这个键呢?
因为HTTP数据报是面向字节流的数据,所以存在粘包问题。关于粘包问题推荐看粘包问题(TCP面向字节流批量发送数据导致)
当浏览器连续给服务器发送多条HTTP请求时,服务器如何区分从哪里到哪里是一条完整的HTTP请求呢?
当没有请求正文(body)时,就可以用请求报头(header)后的空行作为这条HTTP请求的结束标记
当有请求正文(body)时,就需要知道请求正文(body)的长度,推算出这条HTTP请求的结束位置
这样才能避免发送粘包问题(无法区分从哪里到哪里是一条完整的HTTP数据报)
3.Content-Type
表示请求正文(body)的数据格式
常见的取值有:

4.User-Agent
表示当前客户端浏览器和操作系统的版本
以前的时候这个属性比较有用,因为当时电脑没普及,导致电脑之间的性能差异较大,网站的一些功能在差的电脑上运行不起来,所以服务器需要知道客户端浏览器和操作系统的版本,对应发送客户端能够运行的HTTP数据
5.Referer
表示这个页面是从哪个页面跳转过来的(广告商可以通过这个属性知道用户是通过哪个广告平台跳转过来的,就可以付给广告平台对应的广告费)
6.Cookie
浏览器保存网站的临时数据会保存到Cookie中,Cookie中的数据保存在浏览器所处硬盘的空间
Cookie的内容很多,可以通过下面的问答方式了解
1.Cookie中的数据从哪里来?
Cookie中的数据是服务器返回给浏览器的,浏览器在将数据保存到Cookie中
2.Cookie保存在哪里?
Cookie保存在浏览器所在电脑的硬盘上,每个域名都有自己的一组Cookie
3.Cookie里的内容是啥?
Cookie中的内容都是键值对结构的数据,这里的键值对都是程序员自定义的,其中往往会有一个键值对,作为用户的身份标识
4.Cookie中的内容到哪里去?
后续再访问这个网站中的各个页面,就会在HTTP请求中带上Cookie,服务器就进一步知道了客户端的详细情况
Cookie往往会有一个很重要的键值对,是用来表示用户的身份信息的
这是Cookie典型的使用场景
首次访问网站,登陆成功以后,网站返回的HTTP数据报中就会包含用户的身份信息,浏览器就会将用户的身份信息保存到Cookie中,同时网站也会在服务器中创建出一个对应的Session(用户的档案)
服务器的用户肯定不止一个,每个用户都有自己的Session(用户的档案),并且他们的SessionID各不相同,服务器就会使用类似于hash表的方式,以SessionID为key,Session为Value,将所有的数据组织起来
后续访问网站的其他页面时,都会在请求的HTTP数据报的Cookie字段中,带上用户的SessionID(身份标识),服务器就可以根据SessionID找到对应的用户信息,返回用户所需要的HTTP数据报(此时服务器已经知道了客户的身份,就可以向客户发送需要的HTTP数据报,相当于登录网站后,去访问网站的其他页面,都不需要输入用户名和密码了,因为此时访问其他页面时发送的HTTP请求数据报的Cookie属性中包含了用户的信息)
浏览器要保存数据为什么要保存到Cookie中?直接写入一个文件,放到硬盘中不行吗?
这件事情是不行的
因为要是浏览器可以直接保存数据到硬盘中的话,就相当于可以让网页轻易的访问到你的文件系统,网页要是向系统发送以下病毒的话,后果不堪设想
所以,为了保证安全,浏览器会对网页的功能做出限制(禁止访问硬盘就是其中一个限制)
为了保证安全,同时又能存储数据,浏览器就提供了Cookie功能



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











