



TensorRT的硬件平台支持范围
1. NVIDIA GPU平台(原生支持)
-
支持设备:
-
数据中心级:Tesla (A100/V100)、RTX系列 (A6000/4090)
-
边缘计算:Jetson系列 (Orin/NX)
-
消费级:GeForce GTX/RTX
-
-
技术依赖:
-
必须搭载 CUDA核心 和 Tensor Core(用于FP16/INT8加速)
-
需要安装对应版本的 NVIDIA驱动 和 CUDA Toolkit
-
-
典型场景:
# 检查GPU兼容性 import tensorrt as trt print(trt.__version__) # 需>=8.6
2. 纯CPU平台(不支持原生运行)
-
限制原因:
-
TensorRT的优化内核依赖CUDA指令集
-
CPU架构缺少Tensor Core等专用硬件单元
-
-
替代方案:
方案 性能对比 适用场景 OpenVINO Intel CPU优化 x86服务器部署 ONNX Runtime 跨平台通用 多架构兼容需求 TensorFlow Lite 移动端CPU优化 边缘设备部署 -
转换示例(通过ONNX中转):
# 将TRT引擎转为ONNX polygraphy convert engine.plan --format onnx -o model.onnx
3. 手机端(有限支持)
-
Android平台:
-
Jetson AGX Orin 等嵌入式板卡可运行完整TensorRT
-
普通手机GPU(如Adreno/Mali)无法直接运行
-
-
替代方案:
-
TensorRT-LLM for ARM:部分NVIDIA Jetson设备支持
-
NNAPI (Android):调用手机NPU加速
-
Core ML (iOS):苹果设备专用加速
-
-
性能对比(ResNet50推理时延):
平台 TensorRT TFLite (CPU) TFLite (GPU) NVIDIA Jetson 3.2ms 28ms 12ms Snapdragon 888 N/A 45ms 8ms
跨平台部署技术路线图
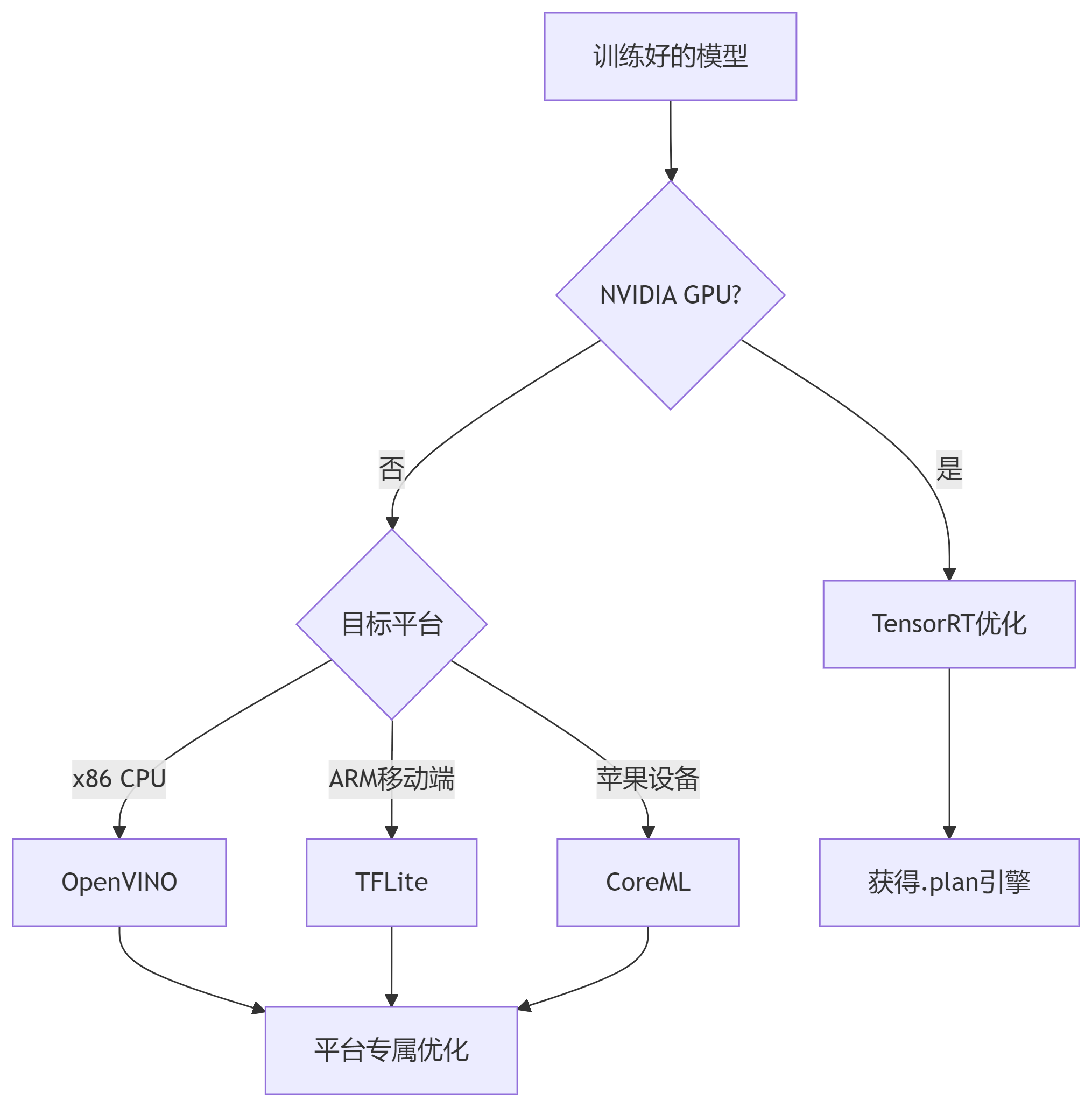
各平台性能优化建议
1. NVIDIA GPU最佳实践
-
量化策略:
config.set_flag(trt.BuilderFlag.FP16) # 大部分架构可用 config.set_flag(trt.BuilderFlag.INT8) # 需Turing/Ampere架构 -
架构专用优化:
-
Ampere GPU:启用
TF32计算(builder.fp32_mode = True) -
Jetson:使用
DLA(深度学习加速器)
-
2. CPU平台优化方案
-
OpenVINO示例:
mo --input_model model.onnx --data_type FP16 --output_dir ir_models -
关键参数:
-
--num_threads 4:设置CPU线程数 -
--enable_ssd_throughput_mode:优化吞吐量
-
3. 移动端部署技巧
-
TensorFlow Lite优化:
converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] -
硬件加速:
-
Android:
delegate = GpuDelegate() -
iOS:
Core ML delegate
-
技术限制与应对策略
1. TensorRT的不可移植性
-
根本原因:
-
依赖NVIDIA专有指令集(如CUDA、Tensor Core)
-
引擎文件(.plan)绑定具体GPU架构
-
-
解决方案:
-
为不同GPU生成多个引擎:
trtexec --onnx=model.onnx --saveEngine=model_a100.plan --device=0 trtexec --onnx=model.onnx --saveEngine=model_jetson.plan --device=1
-
2. 手机端替代方案对比
| 方案 | 优势 | 劣势 |
|---|---|---|
| TFLite + GPU | 通用性强,支持多数Android设备 | 需厂商驱动优化 |
| Qualcomm SNPE | 深度优化骁龙芯片 | 仅限高通平台 |
| Apple Core ML | 无缝集成iOS生态 | 无法跨平台 |
总结:平台选择决策树
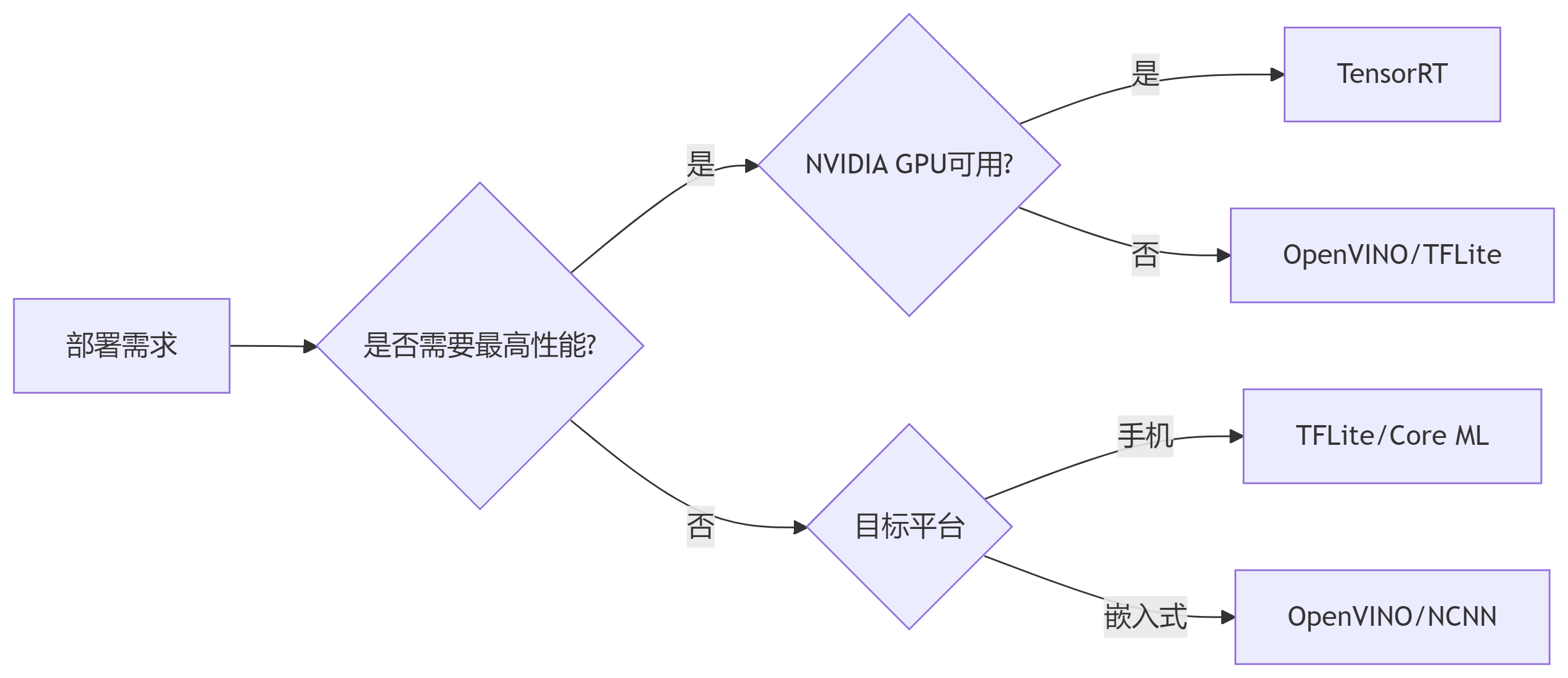
最终建议:
-
工业级部署:优先TensorRT(NVIDIA GPU)
-
移动端应用:采用TFLite + 硬件加速
-
x86服务器:使用OpenVINO优化
-
跨平台需求:ONNX Runtime作为中间层



















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











