




 本文介绍如何使用Python爬取哔哩哔哩视频,包括环境搭建、页面分析、代码实现及视频下载合并。适用于对爬虫感兴趣的开发者。
本文介绍如何使用Python爬取哔哩哔哩视频,包括环境搭建、页面分析、代码实现及视频下载合并。适用于对爬虫感兴趣的开发者。
本篇文章主要给大家讲解下如实使用python 爬取哔哩哔哩中的视频,首先我是一名大数据开发工程师,爬虫只是我的一个业余爱好,喜欢爬虫的小伙伴可以一起交流。好了多了就不多说了喜欢的朋有可以收藏,转发请复原文链接谢谢。

一、环境准备
我这里使用的是环境如下仅供参考: 开发工具: pycharm python环境:python-3.8.0 依赖的包: shutil,os,re,json,choice,requests,lxml
二、页面分析
我在这里就拿前段时间非常火的马老师的视频来举例子吧。 视频链接: https://www.bilibili.com/video/BV1Ef4y1i78b?from=search&seid=12072538764197074893
-
视频链接解析 我们这里只需要 BV1Ef4y1i78b 也就是 video后面? 号前面
-
第二部分抓包,哔哩哔哩这里的视频被分成多个小段了经过看源码分析后我们可以解析</script><script>中的内容返回一个json串解析获取我们想要的数据即可。.
-
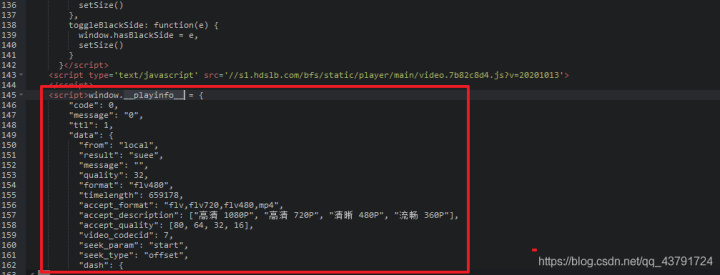
分析返回json中的具体内容
返回给我们的们如下,真正对我们有用的信息在data中

在data 下面我们就可以清晰的看到我们想要的内容了,如视频的画质,以及视频的地址等,注意:如果你拿到地址直接进行访问的话是访问不到了,哔哩哔哩中添加了Referer如果你直接在浏览器访问是没有Referer的是找不到页面的。 我们需要解析的内容如下:
PS:如有需要Python学习资料,此文源码 小伙伴可以加点击下方链接自行获取
-
视频的时长
-
视频的质量
-
视频的URL
-
音频的URL
-
音频和视频合并

三、代码实操
3.1 准备工作
依赖的包
import json import os import re import shutil import ssl import time import requests from concurrent.futures import ThreadPoolExecutor from random import choice from lxml import etree
添加请求头和随机用户代理
#设置请求头等参数,防止被反爬
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
def get_user_agent():
'''获取随机用户代理'''
user_agents = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1",
"Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.23 Mobile Safari/537.36",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20",
"Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
]
# 在user_agent列表中随机产生一个代理,作为模拟的浏览器
user_agent = choice(user_agents)
return user_agent
3.2 编写下载代码
def single_download(aid, acc_quality):
'''单个视频实现下载'''
# 请求视频链接,获取信息
origin_video_url = 'https://www.bilibili.com/video/' + aid
res = requests.get(origin_video_url, headers=headers)
html = etree.HTML(res.text)
title = html.xpath('//*[@id="viewbox_report"]/h1/span/text()')[0]
print('您当前正在下载:', title)
video_info_temp = re_video_info(res.text, '__playinfo__=(.*?)</script><script>')
video_info = {}
# 获取视频质量
quality = video_info_temp['data']['accept_description'][acc_quality]
# 获取视频时长
video_info['duration'] = video_info_temp['data']['dash']['duration']
# 获取视频链接
video_url = video_info_temp['data']['dash']['video'][acc_quality]['baseUrl']
# 获取音频链接
audio_url = video_info_temp['data']['dash']['audio'][acc_quality]['baseUrl']
# 计算视频时长
video_time = int(video_info.get('duration', 0))
video_minute = video_time // 60
video_second = video_time % 60
print('当前视频清晰度为{},时长{}分{}秒'.format(quality, video_minute, video_second))
# 调用函数下载保存视频
download_video_single(origin_video_url, video_url, audio_url, title)
3.3 编写下载代码
def download_video_single(referer_url, video_url, audio_url, video_name):
'''单个视频下载'''
# 更新请求头
headers.update({"Referer": referer_url})
print("视频下载开始:%s" % video_name)
# 下载并保存视频
video_content = requests.get(video_url, headers=headers)
print('%s\t视频大小:' % video_name, round(int(video_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')
received_video = 0
with open('%s_video.mp4' % video_name, 'ab') as output:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
# 下载并保存音频
audio_content = requests.get(audio_url, headers=headers)
print('%s\t音频大小:' % video_name, round(int(audio_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')
received_audio = 0
with open('%s_audio.mp4' % video_name, 'ab') as output:
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
print("视频下载结束:%s" % video_name)
video_audio_merge_single(video_name)
3.4 将下载好的音频和视频合并
def video_audio_merge_single(video_name):
'''使用ffmpeg单个视频音频合并'''
print("视频合成开始:%s" % video_name)
import subprocess
command = 'ffmpeg -i %s_video.mp4 -i %s_audio.mp4 -c copy %s.mp4 -y -loglevel quiet' % (
video_name, video_name, video_name)
subprocess.Popen(command, shell=True)
print("视频合成结束:%s" % video_name)
3.4 运行测试
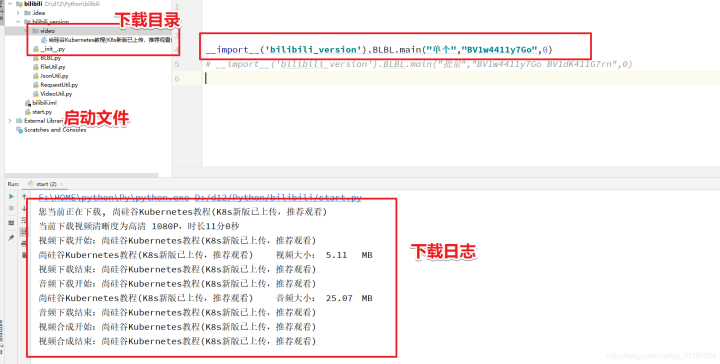
4.总结
好了到这里我们就成功爬取出哔哩哔哩中的视频了!
原文地址:Python爬取哔哩哔哩(bilibili)视频_大数据记录-优快云博客


















 1598
1598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









