



引言
在构建高质量的企业级的智能问答系统的过程中,如何高效精准地处理企业已有的海量文档是大部分开发者亟待解决的核心痛点。有了高效精准的文档解析能力,才能够构建高质量的知识库和高效的信息检索系统,这样 LLM 才能给用户更准确更全面的回答。
Doc2X 简介
Doc2X 是一款专为开发者设计的强大文档解析产品。
Doc2X 提供 RESTful API 与 SDK 工具包,支持多种开发语言与框架,让您轻松将文档处理功能嵌入现有系统,方便快捷地实现将 PDF、扫描件、图片等多种格式的文档精准转换为 Markdown、LaTeX、HTML、Word 等结构化或半结构化格式的能力。
官网:https://noedgeai.com/
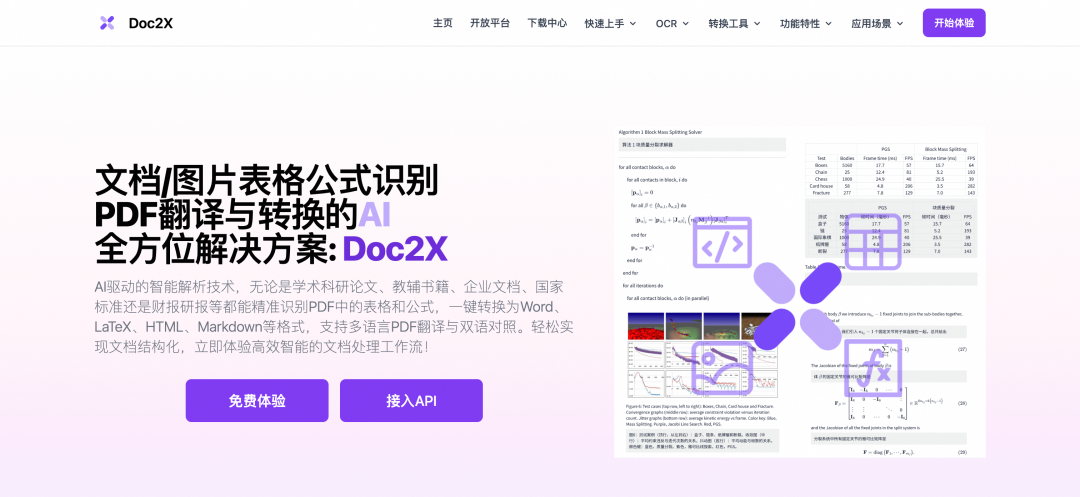
强大的功能特性
- • 市面上类似的文档解析产品,绝大部分公式识别做的不好(尤其是行内和复杂公式),而 Doc2X 则处于领先水平;
- • Doc2X 对表格识别适配优秀,甚至支持识别表格里面的图片和合并跨页表格等;
- • Doc2X 对于多栏识别的阅读顺序还原效果优异;
- • Doc2X 适配范围广相当通用,涵盖财研报、论文、教辅、专利等等;
- • 更具体的效果对比可以参考:Doc2x-v1 竞品分析(mathpix、庖丁PDFlux、pix2text、合合信息TextIn、腾讯云大模型知识引擎文档解析)[2]

友好的操作界面
当然,除了提供了快速集成的 API 之外,Doc2X 还提供了友好的操作界面,可以让你在页面上快速完成文档解析,解析完成之后可以对照着原文档进行编辑,确保准确性。

无缝集成主流工具
Doc2X 已成功接入 FastGPT、CherryStudio、扣子(国内版)等知名知识库和 AI 应用构建平台。开发者可以直接在这些平台中利用 Doc2X 的强大解析能力,快速搭建和优化自己的知识库应用。
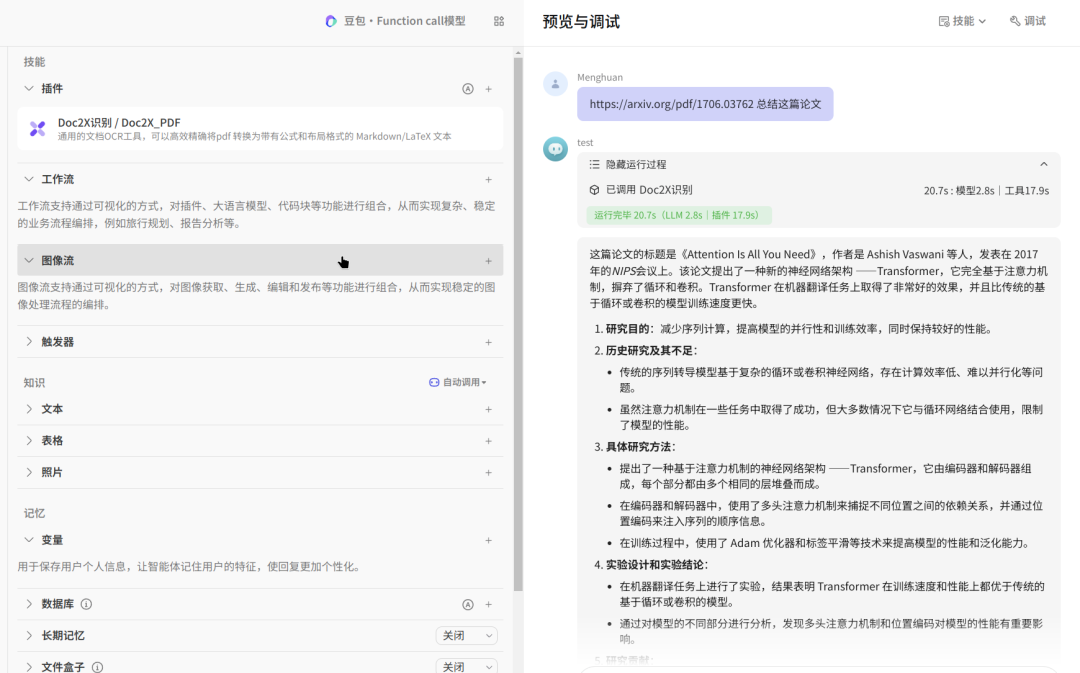
Doc2X 解析效果
从 Doc2X 的解析结果来看,Doc2X PDF 转 Markdown 的整体效果是比较出色的,大家可以根据自己的文档情况去试用看看效果。
我还是拿《2024少儿编程教育行业发展趋势报告.pdf》这个文档进行解析,相比于 MinerU ,在以下几方面 Doc2X 做的更出色:
-
- 支持多级标题的解析(MinerU 只支持一级标题解析);

-
- 表格识别能力比较强,图片中的表格基本准确识别出来,而且基本没有错位(MinerU 存在无法识别或表格错位问题);

-
- 对于多栏识别的阅读顺序还原效果优异(MinerU 对于多栏识别出现了混乱)。


Doc2X API 集成
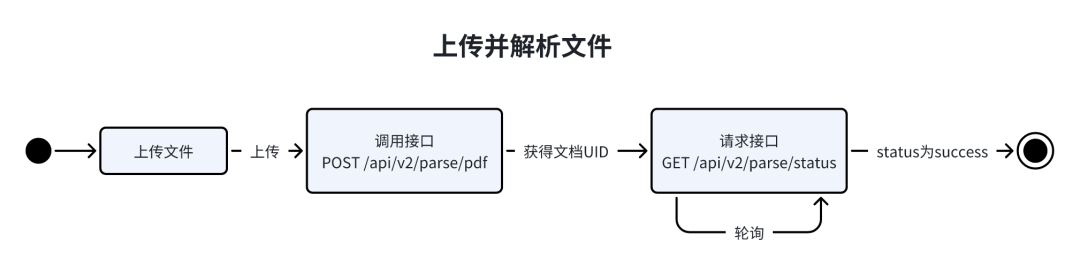
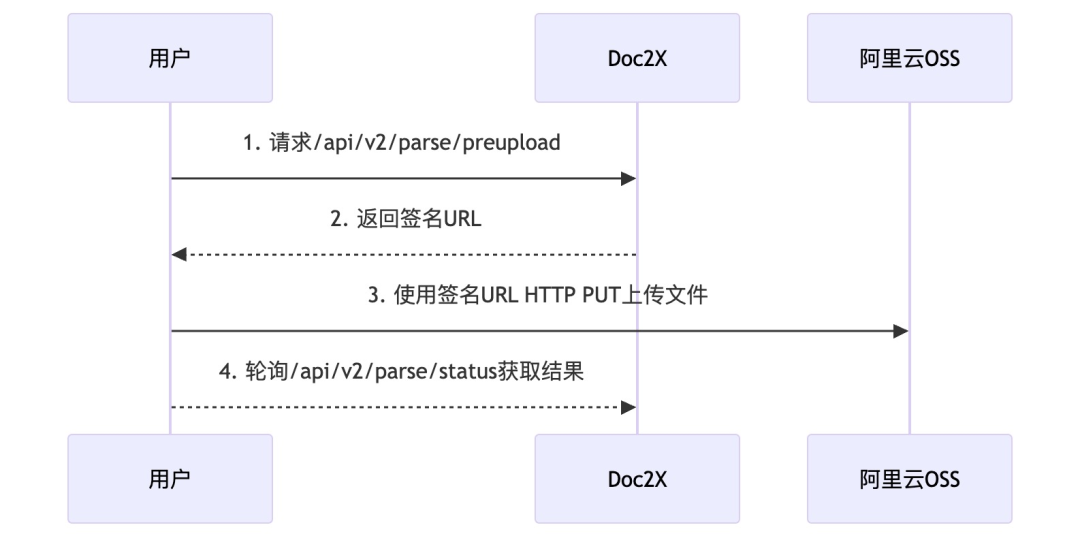
Doc2X RESTful API 的 Base URL 是 https://v2.doc2x.noedgeai.com,API 调用流程如下:
Doc2X API 文档[3]
https://noedgeai.feishu.cn/wiki/Q8QIw3PT7i4QghkhPoecsmSCnG1
接口鉴权
首先需要获取到 API Key(类似于sk-xxx),API Key 获取网址:https://open.noedgeai.com/。
获取之后,在 HTTP 请求头加入:
Authorization: Bearer sk-xxx
文件预上传
推荐使用该接口, 有更快的上传速度,大文件上传接口,文件大小<=1GB。
请求示例:
import json
import time
import requests as rq
base_url = "https://v2.doc2x.noedgeai.com"
secret = "sk-xxx"
def preupload():
url = f"{base_url}/api/v2/parse/preupload"
headers = {
"Authorization": f"Bearer {secret}"
}
res = rq.post(url, headers=headers)
if res.status_code == 200:
data = res.json()
if data["code"] == "success":
return data["data"]
else:
raise Exception(f"get preupload url failed: {data}")
else:
raise Exception(f"get preupload url failed: {res.text}")
upload_data = preupload()
print(upload_data)
返回示例:
{
"code":"success",
"data":{
"uid":"0192d745-5776-7261-abbd-814df3af3449",
"url":"https://doc2x-pdf.oss-cn-beijing.aliyuncs.com/tmp/0192d745-5776-7261-abbd-814df3af3449.pdf?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=LTAI5tS7hV6uXXVzcpk3EGfX%2F20241029%2Fcn-beijing%2Fs3%2Faws4_request&X-Amz-Date=20241029T075458Z&X-Amz-Expires=600&X-Amz-SignedHeaders=host&X-Amz-Signature=f731ea8fe4efdd7c727c210034bdcf1a63436c74b295db68f9648efdce576a91"
}
}
获取到 url 之后,使用 HTTP PUT 方法上传文件到返回结果中的 url 字段,然后使用/api/v2/parse/status 接口轮询结果,使用的是阿里云的oss,具体速度取决于您的网速(海外用户速度可能上传失败)。
import json
import time
import requests as rq
base_url = "https://v2.doc2x.noedgeai.com"
secret = "sk-xxx"
def put_file(path: str, url: str):
withopen(path, "rb") as f:
res = rq.put(url, data=f) # body为文件二进制流
if res.status_code != 200:
raise Exception(f"put file failed: {res.text}")
defget_status(uid: str):
url = f"{base_url}/api/v2/parse/status?uid={uid}"
headers = {
"Authorization": f"Bearer {secret}"
}
res = rq.get(url, headers=headers)
if res.status_code == 200:
data = res.json()
if data["code"] == "success":
return data["data"]
else:
raise Exception(f"get status failed: {data}")
else:
raise Exception(f"get status failed: {res.text}")
url = upload_data["url"]
uid = upload_data["uid"]
put_file("test.pdf", url)
whileTrue:
status_data = get_status(uid)
print(status_data)
if status_data["status"] == "success":
result = status_data["result"]
withopen("result.json", "w") as f:
json.dump(result, f)
break
elif status_data["status"] == "failed":
detail = status_data["detail"]
raise Exception(f"parse failed: {detail}")
elif status_data["status"] == "processing":
# processing
progress = status_data["progress"]
print(f"progress: {progress}")
time.sleep(3)
文件预上传流程图如下:
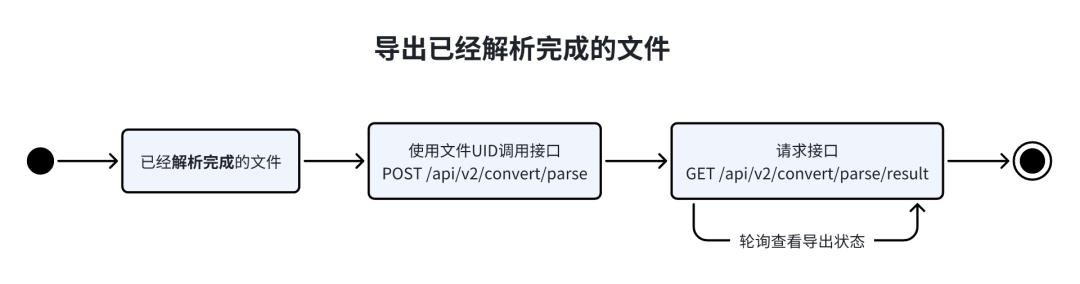
请求导出文件
通过/api/v2/parse/status 接口轮询结果完成之后,需要通过 /api/v2/convert/parse接口触发导出文件任务。
请求示例:
import requests
import json
url = "https://v2.doc2x.noedgeai.com/api/v2/convert/parse"
headers = {
"Authorization": "Bearer sk-xxx",
"Content-Type": "application/json",
}
data = {
"uid": "01920000-0000-0000-0000-000000000000",
"to": "md",
"formula_mode": "normal",
"filename": "my_markdown.md",
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)
返回示例:
// 进行中
{
"code":"success",
"data":{
"status":"processing",
"url":""
}
}
导出获取结果
通过/api/v2/convert/parse接口触发导出文件任务后,需要通过/api/v2/convert/parse/result接口轮询导出文件任务状态,成功之后会返回文件 URL。
请求示例:
import requests
url = 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse/result?uid=01920000-0000-0000-0000-000000000000'
headers = {'Authorization': 'Bearer sk-xxx'}
response = requests.get(url, headers=headers)
print(response.text)
返回示例:
{
"code":"success",
"data":{
"status":"success",
"url":"https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/01927a3a-eeb0-74f6-a539-ca35916b772e5/convert_tex_none.zip?X-Amz-Algorithm=AWS4-HMACSHA256&X-Amz-Credential=AKIATKXFISLI52PK3HTP%2F20241011%2Fcn-north-1%2Fs3%2Faws4request&X-Amz-Date=20241011075617Z&X-Amz-Expires=300&X-Amz-SignedHeaders=host&&x-id=GetobjectX-Amz-Signature=05bdd04a668e9924c5fd361999728cee35aaefb2087334a403f6ebf5ba93f786f"
}
}
下载文件
从/api/v2/convert/parse/result接口获得文件 URL 后就可以通过 HTTP GET 方法请求 URL 来下载文件。
请求示例:
import requests
response = requests.get("https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/01927a3a-eeb0-74f6-a539-ca35916b772e5/convert_tex_none.zip?X-Amz-Algorithm=AWS4-HMACSHA256&X-Amz-Credential=AKIATKXFISLI52PK3HTP%2F20241011%2Fcn-north-1%2Fs3%2Faws4request&X-Amz-Date=20241011075617Z&X-Amz-Expires=300&X-Amz-SignedHeaders=host&&x-id=GetobjectX-Amz-Signature=05bdd04a668e9924c5fd361999728cee35aaefb2087334a403f6ebf5ba93f786f")
withopen('downloaded_file.zip', 'wb') as f:
f.write(response.content)
结语
本文给大家再介绍了一款优秀强大的文档解析产品 - Doc2X,通过实践表明 Doc2X 确实具有优秀的表现,可以作为大家在建设文档解析系统的候选工具,也期望通过我的介绍能给大家提供更多的选择和思路。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









