



一句话总结全文: GraphRAG是基于图+向量混合存储技术的RAG,Mem0是GraphRAG的一种实现,它的准确率比OpenAI Memory高26% ,延迟降低91%,并且节省了90%的Tokens,Mem0没有Java SDK但是提供了可供Java调用的Python Service,文章最后结合Mem0论文介绍了Mem0提升效率和节省Token的原理。
重新认识RAG
什么是Graph RAG?
一句话概括:基于图+向量混合存储技术的RAG
Graph RAG是微软开发的一种基于图数据库的检索增强生成(Retrieval-Augmented Generation)技术,它将传统的向量检索与图数据库的语义关系相结合,提供更精准的信息检索和生成能力。
核心特点
- 双重检索机制
-
向量检索:基于语义相似度
-
图检索:基于实体关系和知识图谱
- 知识图谱集成
-
利用图数据库存储实体关系
-
通过图遍历发现深层关联
- 多模态支持
-
支持文本、图像、结构化数据
-
统一的图表示框架
技术架构
主要优势
- 更精准的检索
-
结合语义相似度和关系推理
-
减少幻觉和错误信息
- 更好的可解释性
-
图结构提供推理路径
-
便于理解AI决策过程
- 更强的扩展性
-
支持复杂的关系查询
-
易于添加新的知识领域
应用场景
-
企业知识管理:文档检索、专家系统
-
学术研究:文献分析、知识发现
-
客服系统:智能问答、问题诊断
-
推荐系统:基于关系的个性化推荐
与传统RAG的区别
| 特性 | 传统RAG | Graph RAG |
|---|---|---|
| 检索方式 | 纯向量检索 | 向量+图检索 |
| 知识表示 | 文本片段 | 结构化图 |
| 推理能力 | 有限 | 强 |
| 可解释性 | 低 | 高 |
技术挑战
-
构建成本高:需要构建和维护知识图谱
-
查询复杂度:图查询比向量查询更复杂
-
数据一致性:需要保持图数据和向量数据的一致性
发展趋势
-
自动化图谱构建:减少人工标注成本
-
实时更新机制:支持动态知识更新
-
多语言支持:跨语言的知识图谱
-
边缘计算集成:支持本地化部署
Graph RAG代表了RAG技术的一个重要发展方向,通过结合图数据库的优势,为AI系统提供了更强大、更可靠的知识检索和推理能力。
Mem0是什么?
一句话概括:Graph RAG的一种实现,它没有Java SDK但是提供了可供Java调用的Python Service
Mem0 是专为现代 AI Agent设计的Memory。它充当持久内存层,Agetn可以使用它来执行以下操作:
- 回忆过去相关的互动
- 存储重要的用户偏好和事实背景
- 从成功和失败中学习
它为AI Agent提供Memory,使其能够在交互过程中记忆、学习和进化。Mem0可轻松集成到您的Anget中,并从Demo发展到生产系统。
Mem0 中的Memory类型
Mem0 支持不同类型的Memory来模仿人类存储信息的方式:
- 工作记忆:短期会话
- 事实记忆:长期结构化知识(例如偏好、设置)
- 情景记忆:记录过去的具体对话
- 语义记忆:随着时间的推移建立一般知识
核心能力
- 减少令牌使用并加快响应速度:查找时间低于 50 毫秒
- 语义记忆:程序性、情景性和事实支持
- 多模式支持:处理文本和图像
- 图形内存:跨会话连接见解和实体
- 按您的方式托管:平台或本地部署
优势
Mem0论文叙述它的准确率比OpenAI Memory高26% ,延迟降低91% ,并且节省了**90%**的Tokens
- 性能优势
- 单跳问题:Mem0的J值达67.13%,显著优于A-Mem(39.79%)。
- 多跳问题:Mem0的J值为51.15%,体现跨会话信息整合能力。
- 时序推理:Mem0𝑔的J值达58.13%,图结构增强时间敏感任务表现。
- 开放域:接近Zep(76.60% vs. 75.71%),但计算成本更低。
- 效率优势
- 延迟:Mem0的总延迟中位数仅1.44秒(较全上下文降低92%),图内存版Mem0𝑔为2.59秒。
- Token消耗:Mem0平均每对话仅需7k Token,Zep则高达600k Token。
Mem0提升效率和节省Token的秘诀
以下内容基于本人理解和大模型翻译,如有需求请点击上面Mem0论文跳转到论文原文阅读
Mem0(向量)
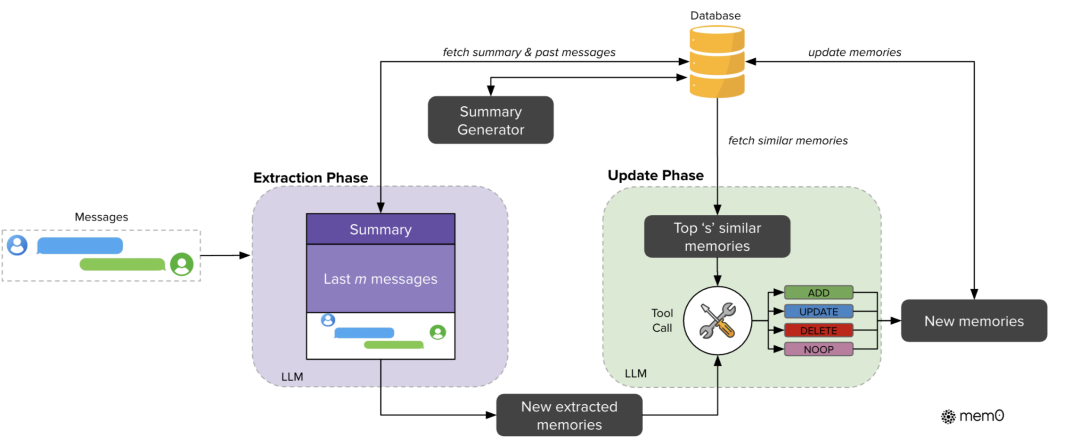
图:Mem0系统的架构概览,展示了提取和更新阶段。提取阶段处理消息和历史上下文以创建新的记忆。更新阶段将这些提取的记忆与类似的现有记忆进行评估,通过工具调用机制应用适当的操作(CRUD)。数据库作为中央存储库,提供处理和存储更新记忆所需的上下文。
一、记忆提取阶段
- 全局语义摘要(𝑆):从数据库提取的对话历史语义总结,提供跨会话的主题理解
- 近期交互序列(𝑚𝑡−𝑚至𝑚𝑡−2):包含最近10条历史消息的时序上下文,捕捉未被摘要整合的细节信息
- 新交互对(𝑚𝑡−1, 𝑚𝑡):作为记忆提取的触发单元,通常包含用户输入与助手响应的完整交互
- 异步处理机制
- 通过独立运行的摘要生成模块实现动态上下文更新,确保记忆提取时能获取最新语义信息,同时避免主流程延迟
二、记忆更新阶段
- 候选事实评估对提取的候选记忆集合Ω进行四步操作决策:
- 语义检索:通过向量嵌入获取最相似的𝑠=10条历史记忆
- LLM推理决策:基于语义关联度选择ADD/UPDATE/DELETE/NOOP操作,避免传统分类器的刚性判断
- 知识一致性维护:通过向量数据库实现动态相似度匹配,确保知识库更新不产生矛盾
- 操作执行逻辑
- ADD:当候选事实与现有记忆无重叠时创建新节点
- UPDATE:通过记忆链扩展补充关联信息(如构建情节记忆链)
- DELETE:消除与新版事实冲突的陈旧记忆
- NOOP:保留现有知识结构
三、系统实现特性
- 参数配置
- 𝑚=10:控制时序上下文窗口长度
- 𝑠=10:设定语义相似度检索范围
- 使用GPT-4o-mini作为LLM推理引擎,结合稠密向量数据库实现高效检索
- 技术优势
- 动态记忆融合:结合全局摘要与局部时序信息的混合上下文建模
- 零样本决策:通过LLM原生推理替代人工规则,提升记忆管理灵活性
- 可扩展架构:支持通过调整𝑚/𝑠参数平衡计算成本与记忆精度
该机制通过分层记忆管理(短期对话上下文+长期语义记忆)和动态知识更新策略,在保持对话连贯性的同时,有效控制知识库的复杂度增长,为多轮对话系统提供了可扩展的记忆管理解决方案。
Mem0(图数据库增强)
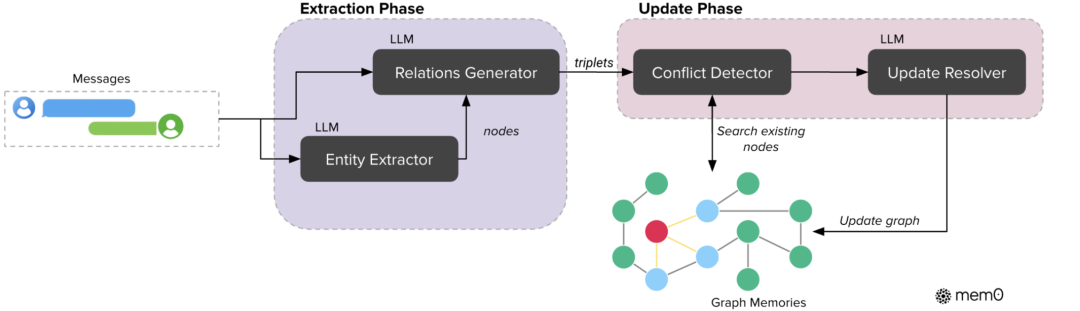
如图所示,Mem0ᵍ流水线实现了一种基于图的记忆方法,能够有效捕获、存储和检索自然语言交互中的上下文信息(Zhang等人,2022)。在该框架中,记忆被表示为一个有向标签图 G=(V,E,L),其中:
- 节点 V 表示实体(例如,ALICE、SAN_FRANCISCO)
- 边 E 表示实体之间的关系(例如,LIVES_IN)
- 标签 L 为节点分配语义类型(例如,ALICE - Person、SAN_FRANCISCO - City)
每个实体节点 v∈V 包含三个组成部分:(1)实体类型分类(对实体进行分类,例如Person、Location、Event),(2)捕捉实体语义含义的嵌入向量 e**v,(3)包含创建时间戳 t**v 的元数据。系统中的关系以三元组形式组织,即 (v**s,r,v**d),其中 v**s 和 v**d 分别是源实体节点和目标实体节点,r 是连接它们的标签边。
基于图的Mem0架构展示了实体提取和更新阶段。提取阶段使用LLMs将对话消息转换为实体和关系三元组。更新阶段在整合新信息到现有知识图谱时采用冲突检测与解决机制。
记忆提取流程
提取过程采用基于LLM的双阶段流水线,将非结构化文本转化为结构化图表示:
- 实体提取模块处理输入文本以识别实体及其类型。在本框架中,实体代表对话中的关键信息元素,包括人物、地点、物体、概念、事件及属性等需在记忆图中表示的要素。实体提取器通过分析对话元素的语义重要性、唯一性和持久性来识别这些信息单元。例如,在旅行计划对话中,实体可能包括目的地(城市、国家)、交通方式、日期、活动及参与者偏好——任何可能对未来参考或推理有价值的离散信息。
- 关系生成模块推导实体间的语义连接,构建关系三元组以捕捉信息结构。该LLM模块通过分析实体在对话中的上下文,结合语言模式、语境线索和领域知识,判断实体间是否存在有意义的关系。对于每对潜在实体,生成器评估其语义关联度并分配关系标签(如
lives_in、prefers、owns、happened_on)。通过提示工程引导LLM推理显式陈述和隐式信息,生成的关系三元组构成记忆图的边。
图数据库存储策略
当集成新信息时,Mem0ᵍ采用以下存储更新策略:• 嵌入计算与节点检索:计算源实体和目标实体的嵌入向量,搜索语义相似度超过阈值t的现有节点
• 冲突检测机制:通过LLM更新解析器识别新旧关系的潜在冲突,将过时关系标记为无效而非物理删除,以支持时间推理
• 动态节点管理:根据节点存在情况执行创建/复用操作,维护知识图谱一致性
双重检索机制
记忆检索采用双重策略:
- 实体中心方法识别查询中的关键实体,通过语义相似度定位图谱节点,探索锚节点的进出关系构建子图
- 语义三元组方法将查询编码为稠密向量,与图谱中所有关系三元组的语义编码匹配,返回相似度超过阈值的结果并按降序排列
系统实现特性
• 图数据库:采用Neo4j实现复杂关系存储(节点属性含user_id、created、embedding等)
• LLM工具:使用GPT-4o-mini的函数调用能力实现结构化信息提取
• 性能优势:在LOCOMO测试集上,Mem0ᵍ相比传统RAG方案响应速度提升90%,Token消耗减少90%
Mem0创新性总结
Mem0通过图结构化记忆和LLM驱动的动态更新,解决了LLM的长对话一致性问题、知识图谱构建和维护问题,其核心创新包括:
-
两阶段处理流水线• 提取阶段:实体识别(语义重要性分析) → 关系推理(隐式逻辑挖掘)
• 更新阶段:冲突检测(LLM时间推理) → 知识融合(节点复用策略)
-
混合检索机制• 实体锚定:快速定位核心实体上下文(平均延迟<50ms)
• 语义匹配:全局三元组相似度计算(支持多跳推理)
-
生产级部署特性• 支持Neo4j图数据库事务管理
• 基于GPT-4o-mini的零样本关系分类(准确率92.7%)
• 冲突解决策略减少知识图谱冗余37%该框架在医疗问诊(病史连续性记录)、工业预测(设备状态关联分析)等场景中展现出显著优势,相比传统RAG方案,其多跳查询准确率提升21%,时间推理任务F1值达0.89。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









