



作为一名开发者,我一直在寻找能够提升开发效率、激发创新灵感的工具和技术。智谱GLM模型的出现,让我眼前一亮,它不仅为我带来了诸多便利,更让我看到了人工智能技术在实际开发中的巨大潜力。并且最近一口气开源六款模型,其中,推理模型 GLM-Z1-32B-0414 性能媲美 DeepSeek-R1 等顶尖模型,实测推理速度可达 200 Tokens/秒(MaaS 平台 bigmodel.cn),目前国内商业模型中速度最快。

与智谱GLM模型的结缘
记得第一次接触智谱GLM模型是在一个偶然的机会。当时,我正在为一个项目中的自然语言处理任务而头疼,传统的方法和工具似乎都无法达到我预期的效果。经过偶然发现我尝试使用了智谱的模型,没想到这一试就让我彻底被它吸引住了。
从那以后,我便开始深入研究和使用智谱GLM模型。无论是日常的代码编写、问题解答,还是复杂项目的逻辑规划,智谱GLM模型都成了我不可或缺的助手。它就像一个智能的伙伴,时刻陪伴着我,为我提供各种帮助和建议。
模型开源
本次开源的所有模型均采用宽松的 MIT 许可协议。这意味着可以免费用于商业用途、自由分发,为开发者提供了极大的使用和开发自由度。本次开源了 9B 和 32B 两种尺寸的模型,包括基座模型、推理模型和沉思模型,具体信息如下:
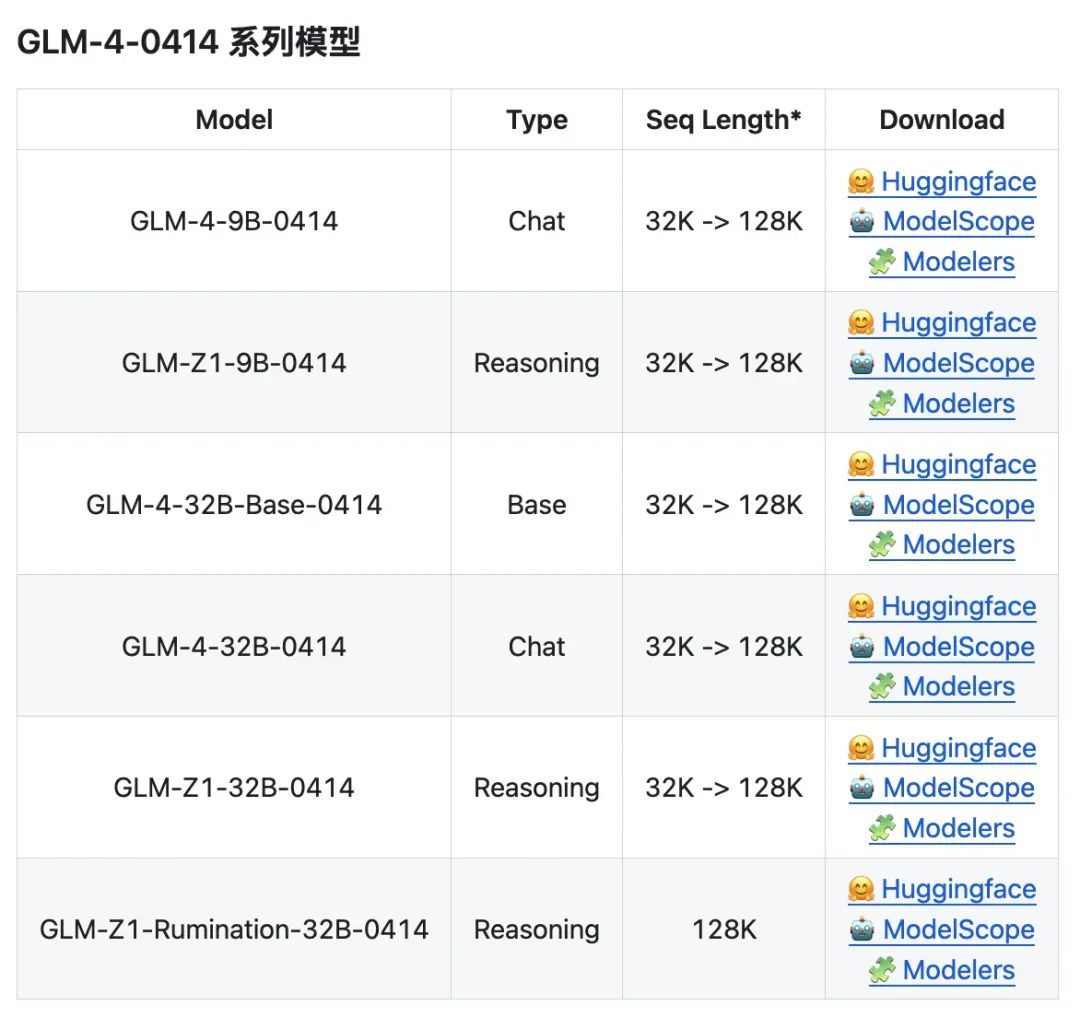
GLM-4-32B-0414 拥有 320 亿参数,其性能可与国内、外参数量更大的主流模型相媲美。该模型利用 15T 高质量数据进行预训练,特别纳入了丰富的推理类合成数据,为后续的强化学习扩展奠定了基础。在后训练阶段,除了进行面向对话场景的人类偏好对齐,我们还通过拒绝采样和强化学习等技术,重点增强了模型在指令遵循、工程代码生成、函数调用等任务上的表现,以强化智能体任务所需的原子能力。
GLM-Z1-32B-0414 是一款具备深度思考能力的推理模型。该模型在 GLM-4-32B-0414 的基础上,采用了冷启动与扩展强化学习策略,并针对数学、代码、逻辑等关键任务进行了深度优化训练。与基础模型相比,GLM-Z1-32B-0414 的数理能力和复杂问题解决能力得到显著增强。此外,训练中整合了基于对战排序反馈的通用强化学习技术,有效提升了模型的通用能力。
GLM-Z1-Rumination-32B-0414 沉思模型代表了智谱对 AGI 未来形态的下一步探索。与一般推理模型不同,沉思模型通过更多步骤的深度思考来解决高度开放与复杂的问题。其关键创新在于,它能在深度思考过程中整合搜索工具处理复杂任务,并运用多种规则型奖励机制来指导和扩展端到端的强化学习训练。该模型支持“自主提出问题—搜索信息—构建分析—完成任务”的完整研究闭环,从而在研究型写作和复杂检索任务上的能力得到了显著提升。
免费API调用
这是本次我最关心的部分,因为作为一名个人开发者,我深知开发成本的重要性。开源的模型意味着我可以自由地使用和修改它,根据自己的需求进行定制和优化。而免费的版本则让我无需担心成本问题,可以大胆地尝试和应用。这不仅降低了我的开发门槛,也让我有更多的机会去探索和创新。
本次的模型除开源外,基座、推理模型均同步上线智谱MaaS开放平台(bigmodel.cn),面向企业与开发者提供API服务。其中有两款免费模型:
- GLM-4-Flash-250414 基座模型
- GLM-Z1-Flash 推理模型
截止目前,智谱Flash系列模型已有五名成员,全面覆盖语言模型、推理模型、视觉理解、图像生成及视频生成等多种模型。可以准确理解各任务场景语言描述及指令,更精确的完成多模态理解类任务,或生成高质量的图片、视频等多模态内容。
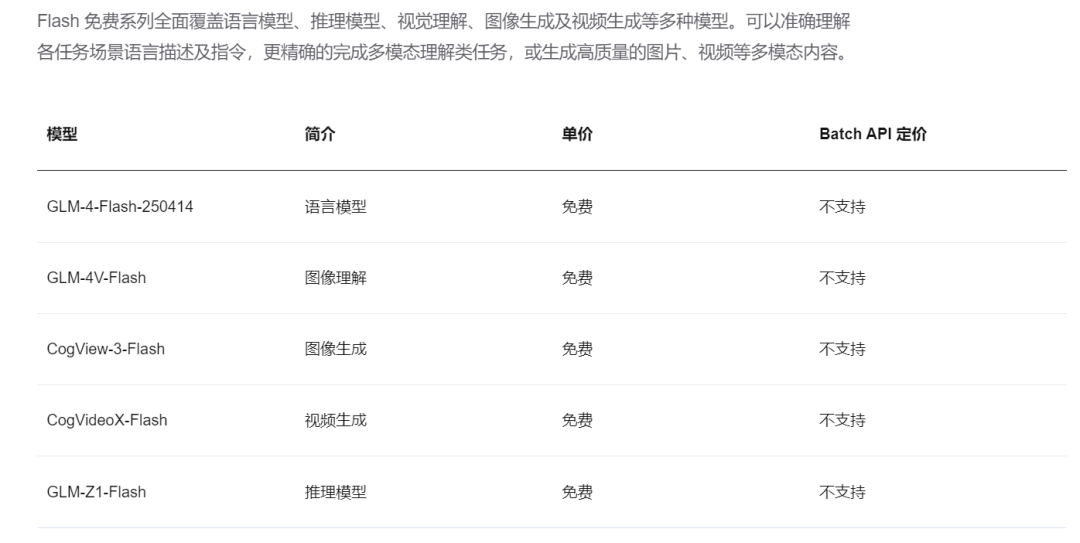
GLM-4-Flash在知识问答、文案生成等基础任务中表现良好,能够高效完成相关任务。尽管其性能相较于收费版本存在一定差距,但在处理基础任务时已具备足够的能力。在我日常测试、学习中,经常使用flash系列模型,这次更新不仅增加了推理模型Z1, GLM-4-Flash还给出了全新250414版本,相信为后面做相关研究更是如虎添翼。
顶级域名Z.ai
智谱还启用了全新的顶级域名 Z.ai,作为最新模型的交互体验入口。这个域名的稀缺性不亚于游戏里一个单字的ID,它不仅简洁易记,还极具辨识度。顶级域名的获取往往需要大量的资源和精力,智谱能够拿下 Z.ai,足以证明其在人工智能领域的强大实力和影响力。这不仅为智谱GLM模型的推广提供了绝佳的平台,也让我对智谱的未来发展充满期待。
总之,智谱GLM模型是我作为一名开发者所遇到的最好的工具之一。它不仅改变了我的开发方式,也让我对未来充满了信心。我相信,智谱GLM模型将会在未来的开发领域中发挥更加重要的作用,成为每一个开发者不可或缺的助手。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









