 模型合金:AI黑客单机突破新境界
模型合金:AI黑客单机突破新境界




你了解过多智能体(Multi-Agent)吗?就在大家还在讨论如何让多个 AI Agent 分工协作、各司其职的时候,一种全新的、更高效的玩法——模型合金(Model Alloy)——横空出世,在不增加成本的前提下带来了显著的性能提升。
来自美国渗透测试公司 XBOW 的 AI 负责人 Albert Ziegler 近日发表了一篇博文,揭示了他们团队的一个「简单而新颖」的想法。这个想法,让他们的 AI 黑客(漏洞检测 Agent)在基准测试中的成功率从 25% 一路飙升至 40%,最终达到了 55%!🚀
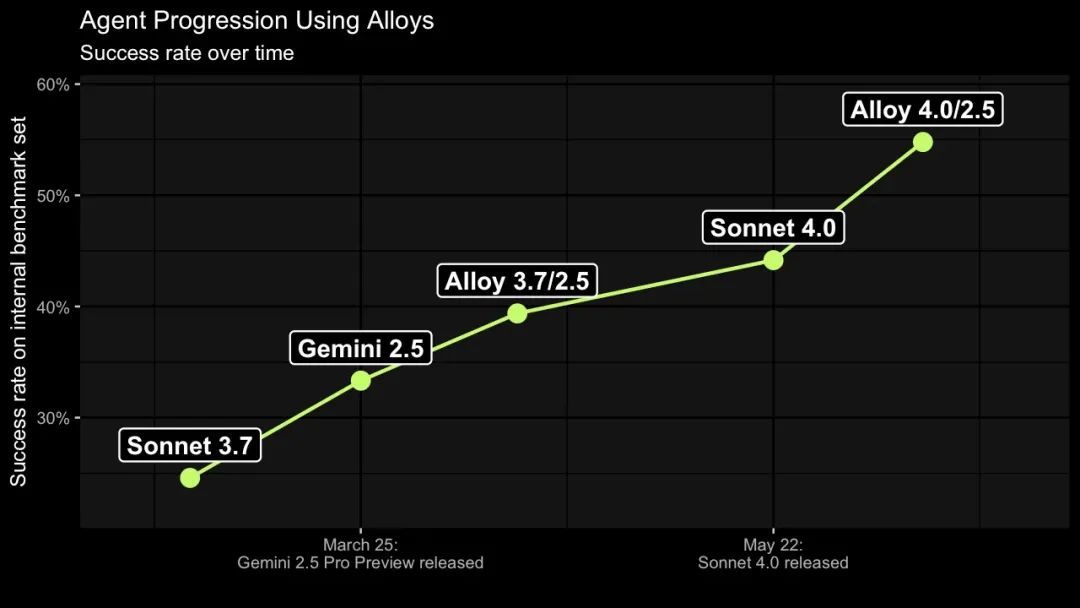
最关键的是,这种方法的原理并不局限于网络安全领域,而是适用于一大类 Agentic AI 的应用场景。
它不依赖于复杂的 Agent 间通信或任务拆解,而是用一种极其巧妙的方式,在一个对话流中「融合」多个不同大模型的智慧,将它们「合体」成一个更强大的超级个体。
这和当前主流的多智能体框架有什么区别?让我们一起学习一下 XBOW 的骚操作。
🤖 缘起:AI 自主黑客的困境
要理解「模型合金」的精妙之处,首先要了解它诞生的背景。
XBOW 主营业务的是自主渗透测试。简单来说,你把你的网站交给它,它就会像一个人类黑客一样,自动尝试攻击它,寻找安全漏洞,然后生成报告让你修复。整个过程完全自主,无需人类干预。
在这个复杂的任务中,反复出现的核心子任务是:给定一个具体的攻击面(比如网站的某个登录接口)和要寻找的漏洞类型(比如 SQL 注入),AI Agent 需要在有限的步骤内成功复现这个漏洞。
这非常像一个网络安全领域的 CTF 挑战:Agent 需要在一系列尝试中找到那个隐藏的「Flag」,证明漏洞的存在。
XBOW 的 AI 负责人 Albert Ziegler 指出,这类任务的特殊之处在于,它不是一个「稳步前进」就能解决的问题。它更像是在一个巨大的搜索空间里勘探金矿:Agent 需要在很多地方挖掘,可能会追随一些错误的线索,然后不断修正方向,最终在某个意想不到的地方发现金矿。
在整个挑战过程中,AI Agent 需要在一堆无效的尝试中,迸发出几个关键的、绝妙的想法,并将它们组合起来才能成功。
为了评估和迭代他们的 Agent,XBOW 建立了一套 CTF 风格的基准测试集。
最初,Agent 的迭代次数被限制在 80 次以内,因为超过这个次数,Agent 积累的错误理解和假设往往会让它陷入死胡同,重新开始一个「干净」的 Agent 反而更有效率。
一开始,团队尝试了市面上所有最顶尖的 LLM。从 OpenAI 的 GPT-4,到后来表现更佳的 Anthropic Claude 3.5 Sonnet。模型不断升级,从 Sonnet 3.7 到谷歌的 Gemini 2.5 Pro,最后到最新的 Sonnet 4.0,模型的性能一代比一代强。
但一个有趣的现象出现了:没有一个模型能在所有挑战中称王。有些挑战,Sonnet 解决起来得心应手;而另一些,则是 Gemini 的强项。
Albert 意识到,如果一个挑战需要 5 个绝妙的点子才能解决,那么有些挑战所需的点子组合恰好是 Sonnet 擅长的,而另一些则更符合 Gemini 的「思维模式」。但如果恰好有一个挑战需要 3 个 Sonnet 式的点子和 2 个 Gemini 式的思路呢?
传统的单模型 Agent 就会束手无策。而主流的多智能体框架,又显得过于「笨重」。于是,「模型合金」这个想法应运而生。
💡 核心揭秘:什么是「模型合金」?
在讨论「模型合金」之前,我们先回顾一下当前主流的多智能体思路。
通常,多智能体指的是让多个 Agent 协同工作,每个 Agent 由不同的、更擅长特定领域的模型驱动。
比如,让 o3 负责规划,扮演架构师;让 Claude 负责编程,扮演程序员;让 Gemini 负责测试;让 Deepseek 负责营销。它们各司其职,像一个人类团队。
而模型合金(Model Alloy)的思路则完全不同。
它的核心思想是:在一个单一的 Agent 对话流中,交替调用不同的 LLM,并巧妙地控制对话历史,让每个模型都以为之前的对话是自己生成的。 这个「控制对话历史」的技巧就是整个方法论的精髓。
我们来看一个具体的例子。假设 Agent 的任务是「Find the bug!」。
第 1 轮:调用 Sonnet 4.0
System: Find the bug!
Sonnet 可能会回答:「我们先用 curl 命令探测一下这个应用。」
Assistant: Let's start by curling the app.
XBOW 的系统执行这个命令,得到返回结果,比如 401 Unauthorized(未授权)。
第 2 轮:调用 Gemini 2.5 Pro
现在,关键操作来了。Agent 不会再用 Sonnet,而是切换到 Gemini。它会把上一轮 Sonnet 的回答「冒充」成是 Gemini 自己说的,然后把新信息作为用户输入。
给 Gemini 的 prompt 会变成这样:
System: Find the bug! Assistant: Let's start by curling the app. User: You got a 401 Unauthorized response.
注意到吗?Gemini 看到这个对话历史,会认为「用 curl 探测」是它自己在上一轮提出的想法。现在,基于 401 的结果,Gemini 可能会提出一个新的想法:「未授权?那我们试试用管理员凭证登录。」
Assistant: Let's try to log in with the admin credentials.
第 3 轮:再次调用 Sonnet 4.0
系统执行登录操作,并成功返回 200 OK。接下来,Agent 再次切换回 Sonnet,并把刚才 Gemini 的回答也加入到对话历史中,同样交付给 Sonnet。
给 Sonnet 的 prompt 会是这样:
System: Find the bug! Assistant: Let's start by curling the app. User: You got a 401 Unauthorized response. Assistant: Let's try to log in with the admin credentials. User: You got a 200 OK response.
如此循环往复。Sonnet 和 Gemini 在一个统一的对话线程中交替出现,但它们彼此毫不知情,都以为自己是这个对话中唯一的「大脑」。
在 XBOW 的实际实现中,他们甚至使用了随机选择模型的策略,以增加多样性。
这种方法的两大核心优势是:
-
- 总的模型调用次数保持不变,没有增加额外的计算开销。
-
- 让每个模型都有机会贡献其独特的优势和灵感,实现智慧的互补。
就像炼制合金一样,将不同特性的金属(模型)熔合在一起,最终得到的合金智能体(Alloyed Agent)比任何单一纯金属(单一模型)都更加坚固和强大。
🚀 效果显著:1+1 >> 2
实验结果证明,「模型合金」的效果远超预期。
XBOW 将 Sonnet 3.7, GPT-4.1, Gemini 2.5 Pro, 和 Sonnet 4.0 两两组合进行测试。结果发现,无论怎么组合,合金 Agent 的性能都优于其任何一个单一组分。
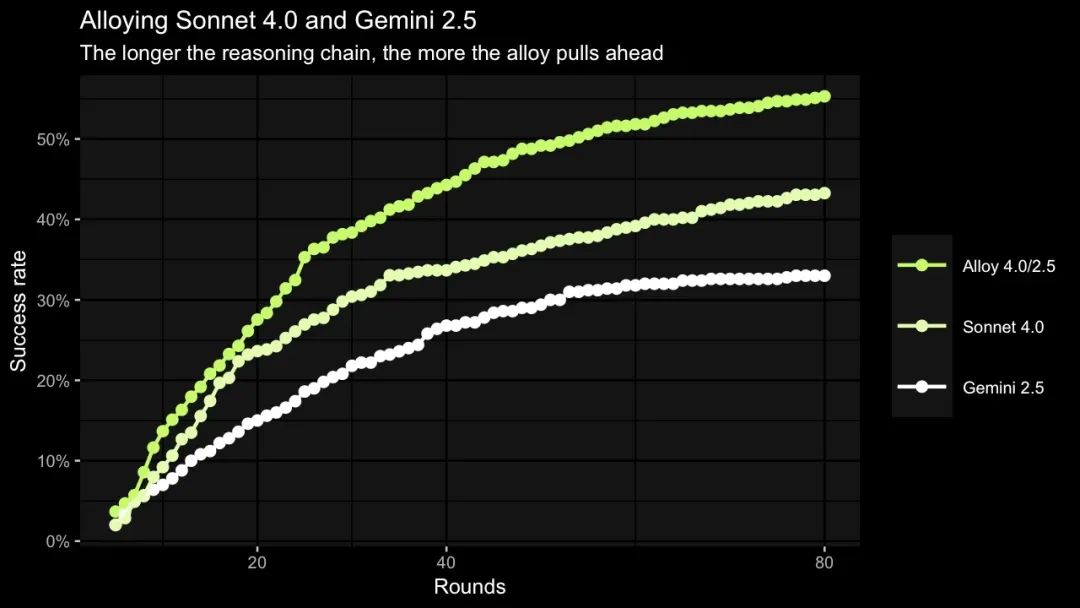
通过大量的实验,团队总结出几个关键规律:
- • 模型差异越大,合金效果越好。Sonnet 4.0 和 Gemini 2.5 Pro 在解决各个挑战的成功率上相关性最低(斯皮尔曼相关系数仅为 0.46),而它俩组成的「合金」性能提升也最大。这说明它们的「思维模式」差异大,互补性最强。
- • 强强联合,优于强弱组合。基础模型越强,组成的合金也倾向于越强。如果一个模型本身性能拉胯太多,甚至可能拖累整个合金的表现。
- • 不均衡合金应偏向更强的模型。如果一个模型明显强于另一个,那么在随机调用时,给更强的模型更高的权重,效果会更好。
为了更直观地说明合金策略的威力,XBOW 做了一个对比实验:
-
- 方案A:运行两个独立的 Agent,只要任意一个解题就算成功。
-
- 方案B:运行一个 Sonnet 4.0 Agent 和一个 Gemini 2.5 Pro Agent。
-
- 方案C:运行两个的「Sonnet 4.0 + Gemini 2.5 Pro」合金 Agent。
结果如下表所示,合金 Agent 的组合完胜其他所有组合,成功率达到了惊人的 68.8%。这甚至远高于简单地将两个最强 Agent 的成功率相加。
| 第一个 Agent | 第二个 Agent | 综合成功率 |
|---|---|---|
| Gemini 2.5 | Gemini 2.5 | 46.4% |
| Sonnet 4.0 | Sonnet 4.0 | 57.5% |
| Sonnet 4.0 | Gemini 2.5 | 57.2% |
| 合金 (S4+G2.5) | 合金 (S4+G2.5) | 68.8% |
这有效地证明了,模型合金并非简单的能力叠加,而是产生了真正的思维化学反应。
⚔️ 「合金」 vs. 「多智能体」:一场范式之争
读到这里,你可能会问,这种方法和我们熟悉的其他多模型方法有什么不同?Albert 在博文中也对比了「模型合金」与其他三种主流范式的区别。
1. vs. 任务专家分工(Specialized Agents)
这是最经典的多智能体模式,以 AutoGPT 生态为代表。其核心是为不同任务分配不同模型。比如,用一个高阶模型(如 GPT-4)做总规划,用更专业的模型执行具体计划,高阶模型定期检查进度并调整。
- • 优点:逻辑清晰,符合人类团队协作直觉。
- • 缺点:「模型合金」的作者认为,这种方法会给他们的 Agent 循环增加过多的开销。对于 XBOW 这种需要快速迭代、不断试错的搜索任务来说,效率太低。
2. vs. 模型投票(Mixture-of-Agents)
这种方法是在每一步都同时问询多个模型,然后通过投票或引入一个「裁判」模型来选出最佳答案。知名的 Mixture-of-Agents (MoA) 就是一个很好的例子。
- • 优点:集思广益,提升单步决策的可靠性。
- • 缺点:成本和延迟会成倍增加。XBOW 认为,用这些额外的成本,他们宁愿多启动几个独立的 Agent 去碰运气。
3. vs. 多智能体辩论(Multi-Agent Debate)
这种模式让模型之间直接对话,互相提出论点、反驳和完善对方的答案。
- • 优点:对于极其关键、不容有失的单步决策,这种方法能做到极致的审慎和深入。
- • 缺点:太「重」了。XBOW 的任务本质上是一个搜索过程,它需要快速地「翻开一块块石头」,而不是成立一个委员会来决策下一块石头应该怎么翻。
总结来说,「模型合金」巧妙地避开了上述所有方法的缺点。它既没有增加模型调用的总数,也没有引入复杂的任务管理开销,而是通过一种轻量级、优雅的方式,在一个 Agent 内部实现了多个模型智慧的动态融合。
🧭 「炼金」指南:你的项目适合用「模型合金」吗?
看到这里,你一定也跃跃欲试了。不过,模型合金虽好,也并非万能。Albert 贴心地给出了应用指南。
什么时候应该考虑使用模型合金?
- • 你的任务是通过一个迭代循环调用 LLM 来解决问题,且调用次数较多(比如几十次以上)。
- • 任务的解决需要组合多个不同的想法或洞察。
- • 这些想法可以在流程中的不同时间点出现,没有严格的先后顺序。
- • 你能接触到足够多样化(最好来自不同厂商)的大模型。
- • 这些模型各有千秋,在不同方面有各自的长处和短处。
什么情况下「模型合金」可能不是最优选?
- • 你的 prompt 远长于模型的生成内容。这种情况下,你非常依赖
prompt caching(提示词缓存)来降低成本和延迟。而模型合金需要为每个模型维护一个缓存,这会使缓存的成本和复杂性翻倍。 - • 你的任务是「稳步前进」型,而不是需要「灵光一闪」。对于前者,合金模型的表现可能只会是几个模型表现的平均值。
- • 只有一个模型在你的任务上表现突出。这样你就没有合适的模型来和你的「王牌模型」炼成合金了。
- • 你手头的所有模型「思维方式」太相似。它们对任务难点的判断高度一致,无法形成互补。XBOW 团队就发现,将同属 Anthropic 公司的模型合金化,性能提升微乎其微。
最后的这一点尤其关键:记住,模型合金的魔力,源于「差异性」。只有当不同厂商、采用不同架构和训练数据的模型融合时,才能真正碰撞出智慧的火花。
✨ 写在最后
「模型合金」为我们打开了一扇新的大门。它揭示了在构建强大 AI Agent 时,我们不必总是在复杂的「群体智能」和单一的「个体智能」之间做选择。
通过一种简单而巧妙的「融合」,我们可以创造出一种全新的智能形态——它拥有单一 Agent 的简洁高效,又兼具了多个大脑的多样性智慧。这无疑为 AI Agent 领域的发展提供了极具价值的参考。
如果你也对这个想法感兴趣,不妨现在就动手试试,或许下一个性能飙升的,就是你的 AI Agent!
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









