



什么是大模型?接下来我将继续用业余视角,聊聊大模型,以下是本文的目录,您可以选择跳到感兴趣的部分:
1.大模型综述
2.什么是模型
3.什么是大模型
4.大模型长什么样
5.如何训练大模型
大模型综述
大模型(Large Model,简称LM),完整全称应该叫“人工智能预训练大模型”,是指具有超大规模参数(通常在十亿个以上)通过海量数据预训练得到的神经网络模型,它能够通过训练获得通用的语言和图像等模态的理解和生成能力,并展现出涌现能力(图示为国内外知名大模型参数量示例)。
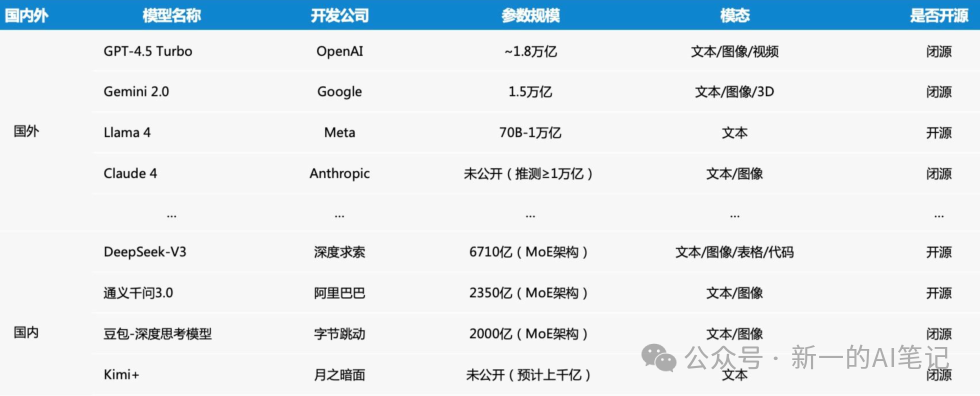
图片来源:知乎,数说新语
大模型的大不仅体现在参数量大,还包括架构规模大、训练数据大、算力需求大
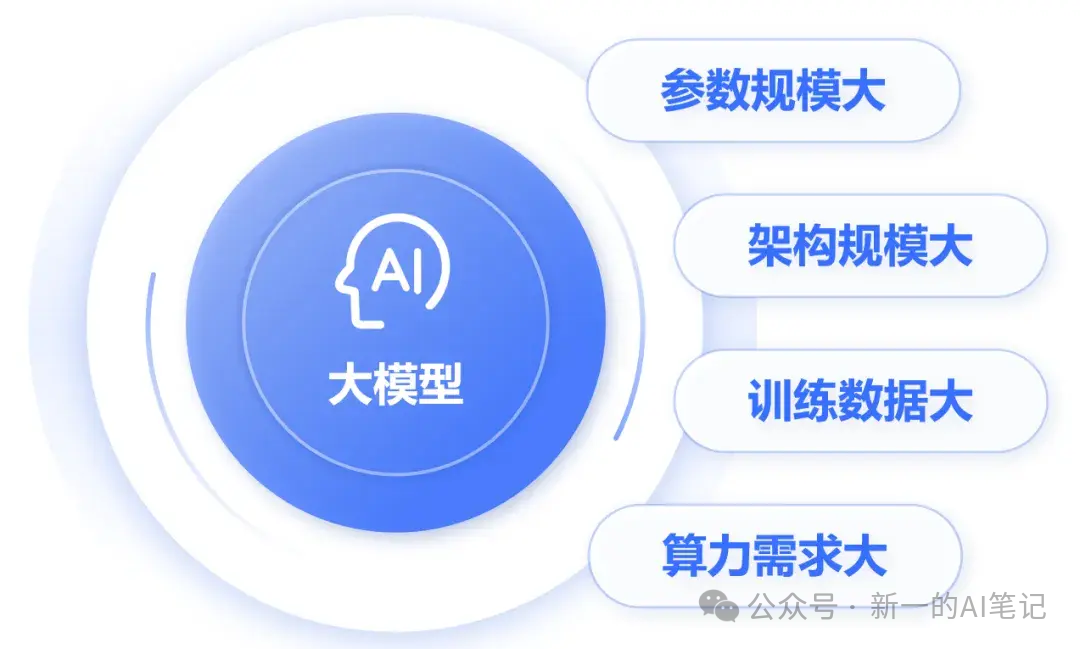
图片来源:知乎,小枣君
广义的大模型包括语言大模型、视觉大模型、多模态大模型等,狭义的大模型特指我们常用的大语言模型(LLM),如ChatGPT、DeepSeek等。

图片来源:自绘
读了以上文字,您可能要骂了,说好的用人话解释AI的呢,就这?上来整一堆概念,让我怎么看?别骂了盆友,接下来将为您用人话解释大模型,需要点初中数学知识(你看,又骂)。
01 什么是模型
先说结论,在计算机领域,所谓的模型本质上指函数。
用烂掉的房地产行业,举个栗子。假如您是一个在杭城漂泊的牛马,经过多年努力,您打算买一套房子安家。经过大量调研,您收集了以下数据样本(实际样本可能包括户型面积、位置、朝向、交通、卫生间数量、学区等要素,为了便于解释,进行简化):
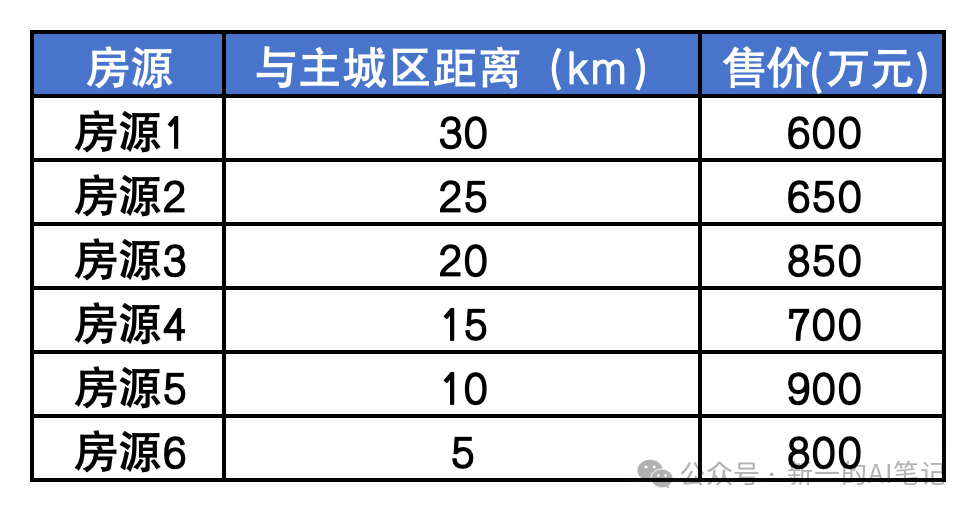
图片来源:自绘
在不考虑其他要素的条件下,您看中了一套房源,距离主城区35km,那么怎么预测售价是多少?
您说,简单,这题我会。并快速在坐标系中画出了数据分布图,并发现了距离主城区越远,售价越低的趋势。
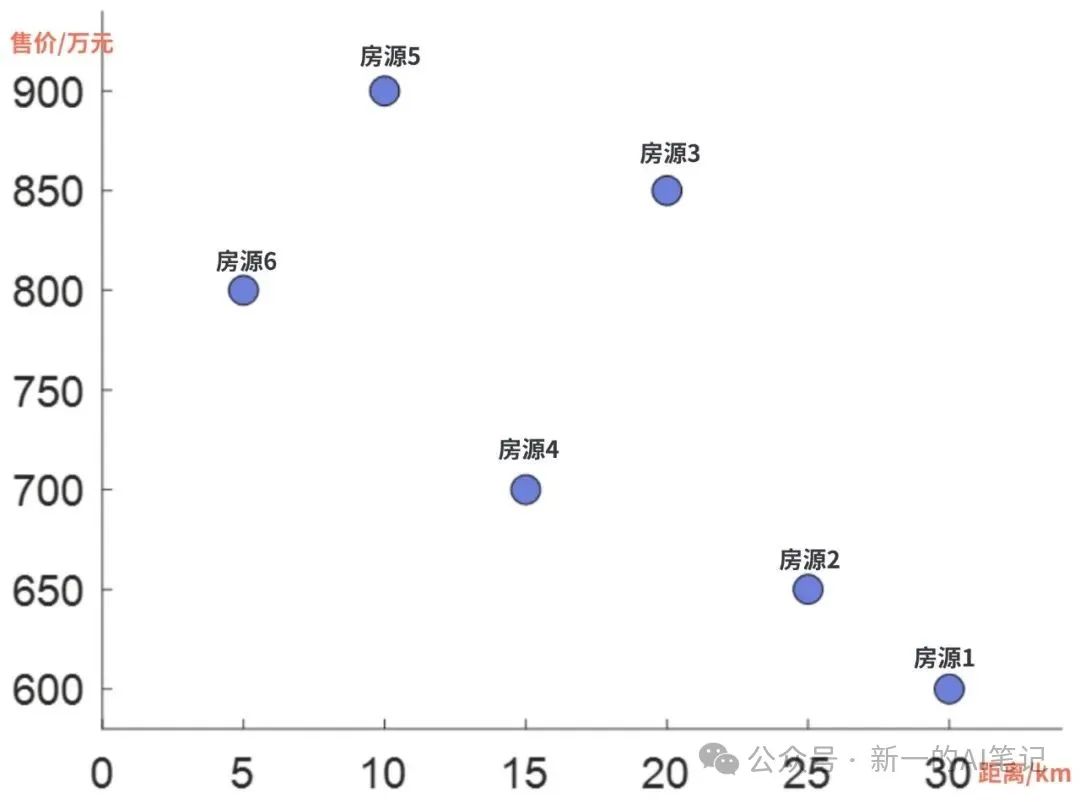
图片来源:自绘
分析了以上数据分布后,你打算选择初中二年级学过的二元一次函数y = wx + b来描述与主城区的距离x与售价y的关系,w和b是函数中未知的参数,只要求得w和b的具体数值,再把x = 35带入的上述函数,就能得到距离主城区35km时,房屋的售价。
到此,预测房价的问题,被转化为确定w和b的具体数值的数学问题,也就是说,您为房价预测建立了一个数学模型:y = wx + b。
实际您也只能求得一个最优解,使得曲线距离所有的样本点总误差最小。
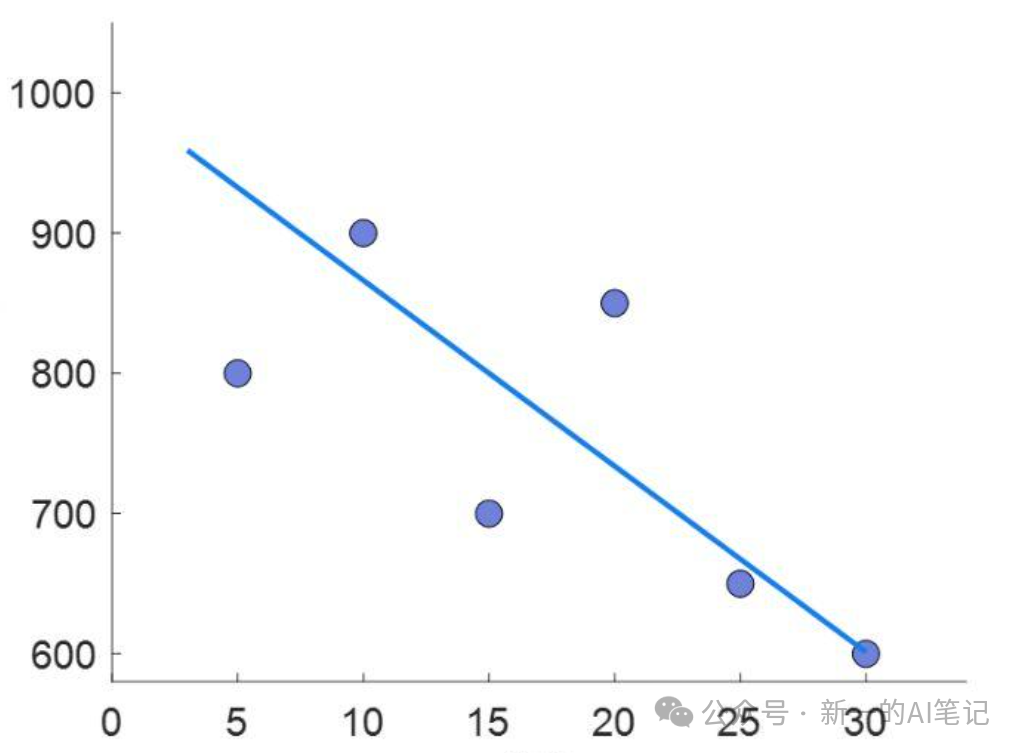
图片来源:自绘
瓦特?等下...模型?参数?预测?难道网上神乎其神的大模型,几亿参数的那种,就这?
没错,为了方便盆友们理解,我对大模型进行了抽象简化。大模型的真相就是一个形式复杂,参数极多的一个函数。通过以上栗子,其实您已经掌握了大模型预训练和推理的原理:
1.模型预训练:模型厂商通过海量数据,求参数w和b,来最大化的拟合数据分布。上线发布,供用户使用。
2.模型推理:用户将x输入,函数后台进行计算,返回y。这就是您和DeepSeek聊天时,您输入文本,模型返回答案的过程。
02 什么是大模型
我们已经知道,模型的真相——函数。在实际应用中,模型的种类有很多,上述例子中,我们使用的是线性回归模型,可以用于应对一些简单的预测问题。但是如果将户型面积、位置、朝向、交通、卫生间数量、学区等要素全部考虑,线性回归模型就显得过于简单,无法应对复杂的数据分布了(比如图示这种)。
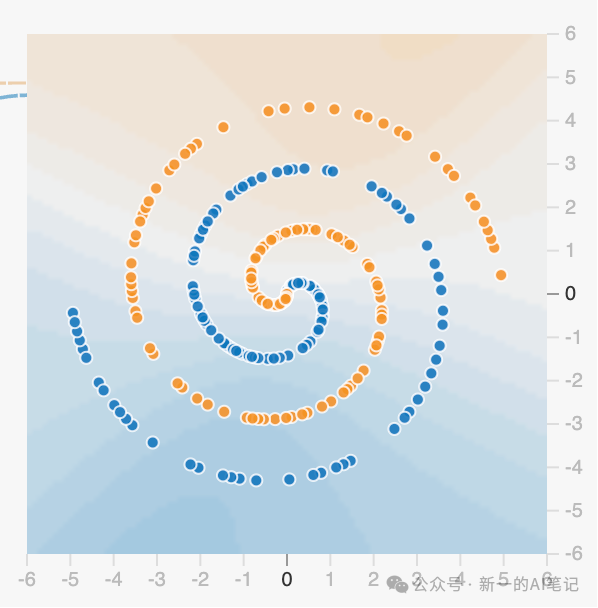
图片来源:http://playground.tensorflow.org
莫方,为了能够拟合复杂的数据分布,有很多模型可以用,比如逻辑回归、随机森林、决策树等。
目前大模型所采用的是神经网络模型(模仿人脑的神经元),对于样本的一个或多个输入(x值),经过网络多个隐藏层的层层计算,最终得到一个或多个输出(y值),以上所说的多个,都可以根据需要设置具体的值。
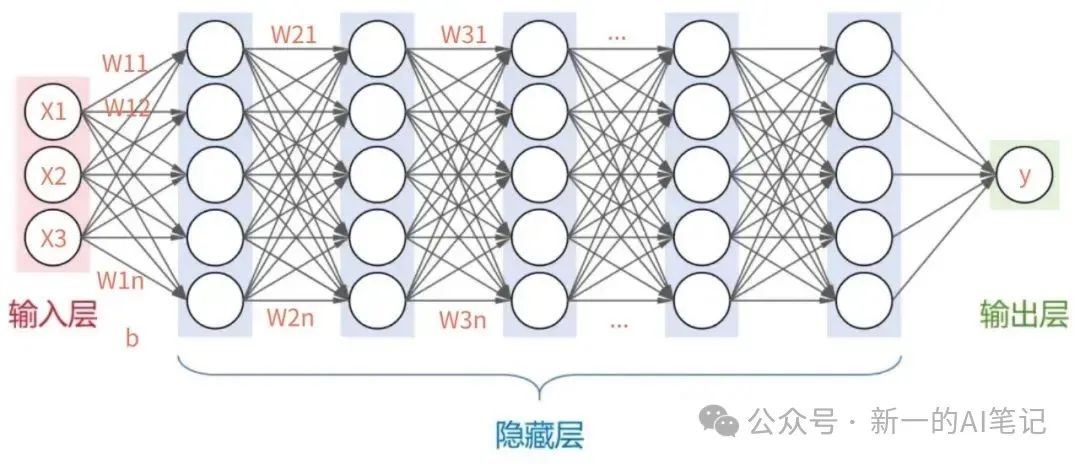
图片来源:自绘
隐藏层的计算,主要参数是w和b,作为一个复杂模型,还有很多其他参数,这里不做过多解读,有兴趣的盆友可以深入了解。
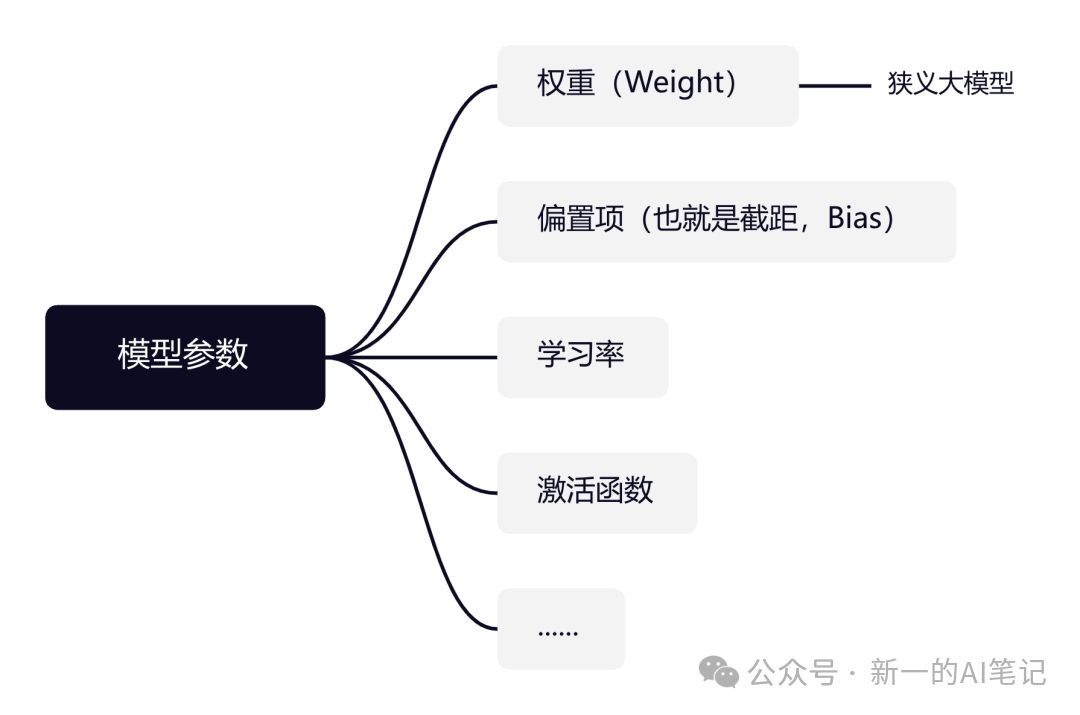
图片来源:自绘
以OpenAI的GPT-3大模型为例,隐藏层一共有96层,每层的神经元数量达到2048个,极其庞大的网络结构,参数数量达到惊人的1750亿,模型性能更是那四个字——遥遥领先。
03大模型长什么样
我们常用的生成式AI,都会提供多个模型供用户选择,每个模型采用了不同的训练策略,可以满足用户不同的需求。
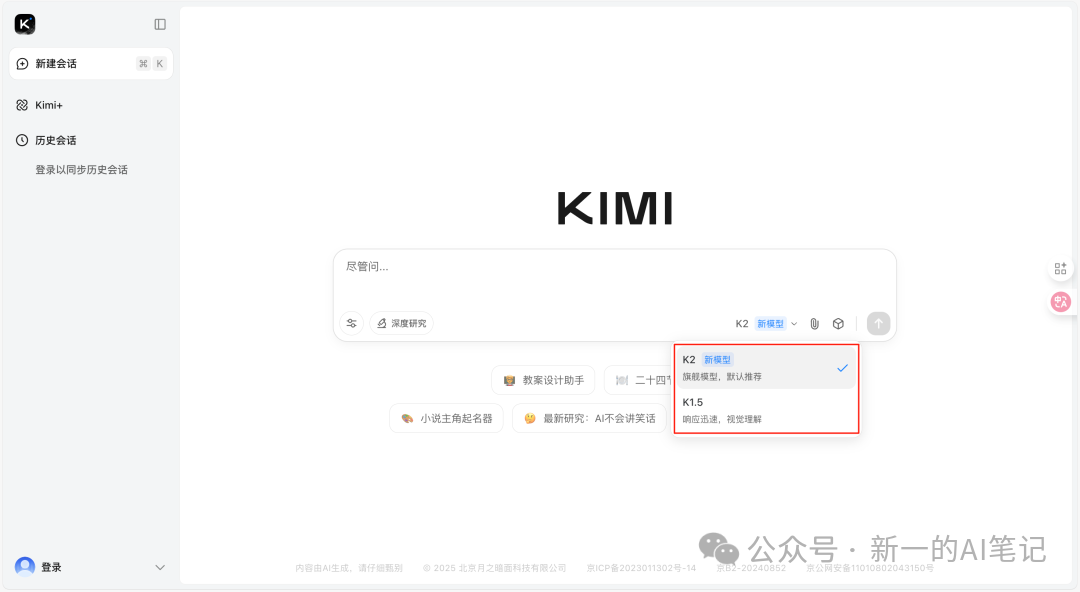
图片来源:https://www.kimi.com
1.大模型的组成部分
以大家常用的kimi为例,官方提供了2个预训练模型,供用户推理使用。我们可以去魔搭社区(国内的开源大模型免费下载平台,网址https://modelscope.cn)看看k2模型包括哪些文件。
当前开源的大模型通常以数据文件形式发布,它主要是由权重参数、配置文件两类文件构成。其中权重参数是模型在海量数据上训练后得到的参数集合,是大模型最核心的组成部分。
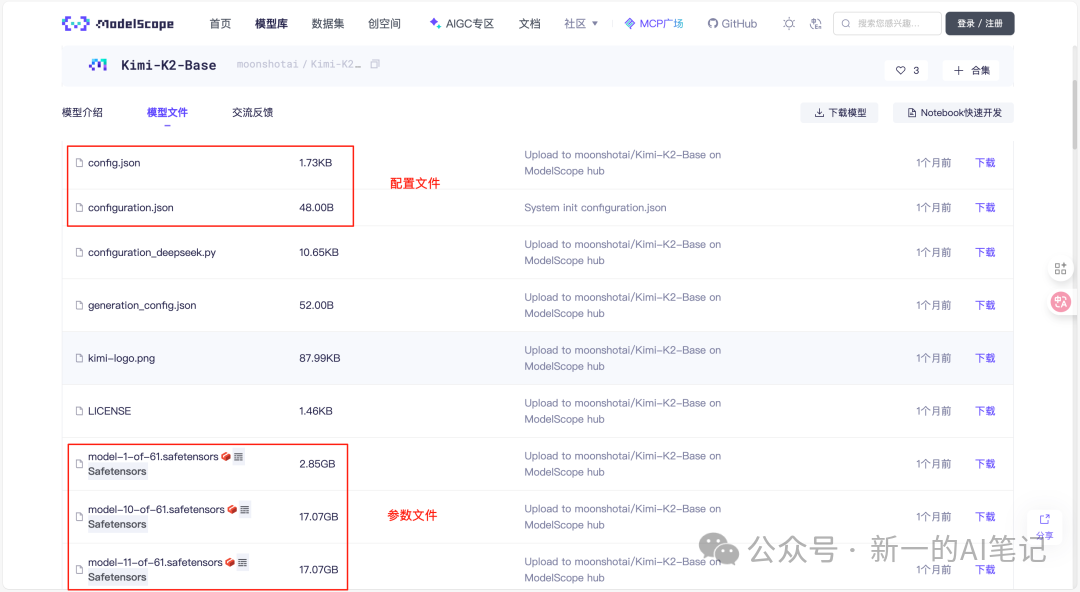
图片来源:https://www.modelscope.cn
Kimi-K2-Base大模型共计包含了75个文件,主要为json和safetensors文件。其中,61个safetensors是存储权重参数的文件格式。模型的参数,存储在该文件中,大模型的参数量达到几十亿甚至上千亿,因此该文件的数据量也是最大的,最大的约20G。
2.大模型的尺寸
在魔搭社区中检索阿里最新发布的Qwen3大模型,可以看到有多种尺寸,有0.6B,8B,32B,235B等,这个值表示的是就是模型的总参数量,B是Billion(十亿)的缩写,也就是说Qwen3最小的模型参数量有6亿个,最大的参数量有2350亿个。
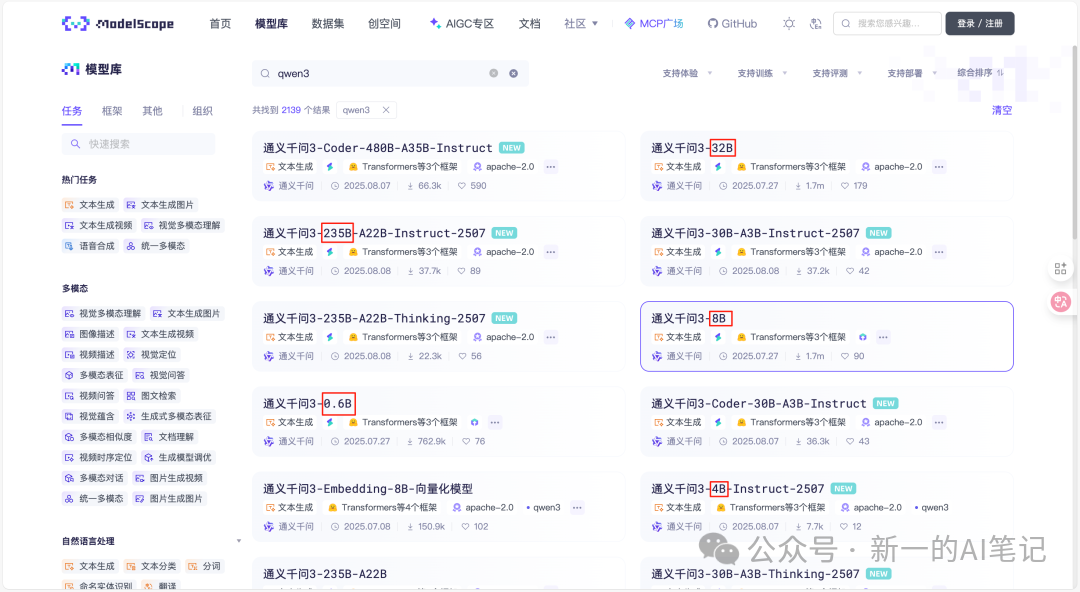
图片来源:https://www.modelscope.cn
模型参数越多,表示神经网络层次和神经元个数越多,模型就越复杂,实际推理性能越好。您可能会说,既然模型尺寸越大,性能越好,那么为什么要训练小尺寸的模型?因为越大尺寸的模型,要求的显存越大,一般设备上是没法运行的。为了在手机或AI眼镜上轻量化运行,就需要部署小尺寸模型。
让我们以Qwen3最小尺寸的模型0.6B为例,简单计算推理时需要的羡慕,这样能有个概念。假设每个参数为32位(bit)浮点数(float32):
1.已知:
1字节(Byte) = 8位(bit)
2.计算每个参数的字节数:
32位(bit)= 4字节(Byte)
3.推导计算机内存占用:
1GB = 1000MB
1MB = 1000KB
1KB = 1000Byte
1GB = 10^9Byte
4.计算最终结果:
0.6B = 0.6 * 10^9个
总字节数为0.6 * 10^9 * 4 = 2.4 * 10^9 Byte ,总显存为2.4GB
以上仅仅是指考虑了参数部分的显存占用情况,实际全参推理时,还会有其他显存开销,显存占用为目前的6倍以上,即2.4 * 6 = 14.4GB。0.6B的模型尚且如此,那235B模型的显存占用,只能说是Amazing。所以用户使用尺寸大的大模型,只能通过线上调用大模型,大模型厂商可以有很多显卡供咱使用。
图片来源:https://www.kimi.com
04 如何训练大模型
在第1部分什么是模型的例子中,已经简单表达了大模型的训练逻辑。就是通过海量的数据,求参数值,最大化的拟合数据分布,获得最小化的误差。
简述具体训练过程:先准备海量高质量数,每个数据样本包括特征x(类比房源与主城区距离)和真实值Y(类比售价),再选择一个具体的模型结构(比如Transfomer),模型自动初始化w和b的参数值。将海量数据x,经过神经网络层层计算,得到一个预测y,再将预测值y与数据的真实值Y比较,求得两者的差值,称之为损失(loss),再根据损失值,反向调整w和b,直至损失值最小为止,这是的模型预测值会无限接近真实值(实际预测值y和真实值Y,不可能完全相等,也就是说损失值Loss不为0)。
参数学习的过程,叫做模型预训练。用户调用的过程,则叫做模型推理。
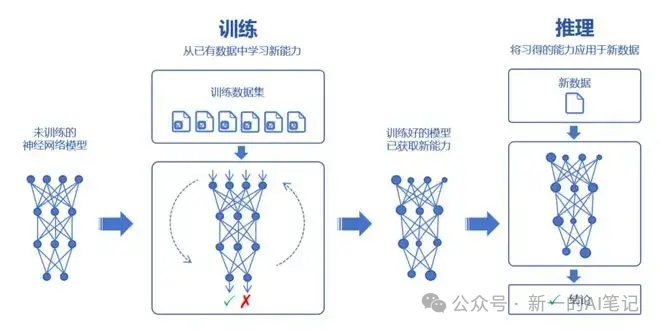
图片来源:知乎,小枣君
看完以上内容,相信您基本对大模型的原理和尺寸有所了解。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 6899
6899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









