 李沐手搓语音大模型教程及学习资源分享
李沐手搓语音大模型教程及学习资源分享




李沐老师终于带着他的手搓语音大模型教程回归了,一千万小时音频数据训练的TTS,效果秒杀一众商业&开源的TTS。

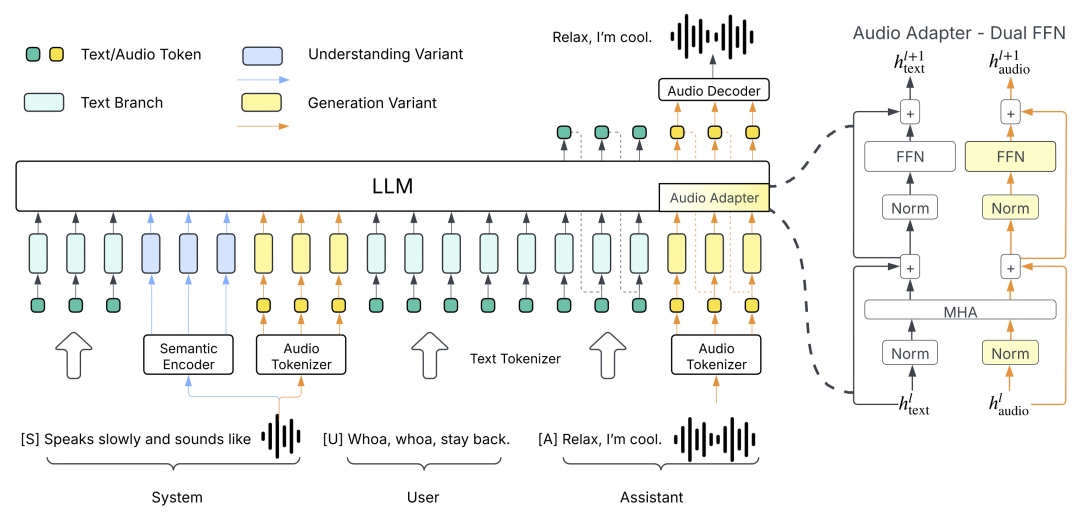
本期视频不讲论文,李沐老师来手把手教大家怎样玩转他们团队最新研发的Higgs Audio V2模型,不仅能处理文本,还能同时理解并生成语音。
视频教程:https://www.bilibili.com/video/BV1LGbozkEDY/?spm_id_from=333.337.search-card.all.click&vd_source=4075efdd29cbc7a407952a778f815fd3
模型代码:https://github.com/boson-ai/higgs-audio
除了一些常规语音任务外,这个模型还具备一些较为罕见的能力,比如生成多种语言的自然多说话人对话、旁白过程中的自动韵律调整、使用克隆声音进行旋律哼唱以及同时生成语音和背景音乐。
整个过程堪称“大力出奇迹”,直接将1000万小时的语音数据整合到LLM的文本训练,让它能听也能说。(当然还有亿点点细节)
粗暴,但有效!
鬼畜视频?人力手搓已经OUT了,李沐老师直接用算力帮大伙搞定,效果be like:
沐导今日组会内容速记
传统的语音和文本模型之间相互独立,李沐老师就想,欸,能不能将两者结合起来,直接让LLM用语音进行沟通。
那么首先就要知道文本语言模型的本质是用给定的一段指令去生成预测结果,就是将任务先拆解为系统指令(system)、用户输入(user)、模型回复(assistant)三个部分。
system告诉模型,需要做什么事情,例如回答该问题、写一段文字或者其他,user就是告知事情的详细内容,例如问题具体是什么、文字要什么风格。
所以如果要让模型支持语音,就需要为模型增加一个系统命令,在user里输入要转录为语音的文字,让模型从system里输出对应语音数据。
这样语音任务就能转换成相同的处理格式,直接打通语音和文本之间的映射,通过追加更多的数据和算力,直接scaling law“大力出奇迹”。
这就引出了新的问题,语音信号本质是连续的,要如何才能在离散的文本token中表示呢?
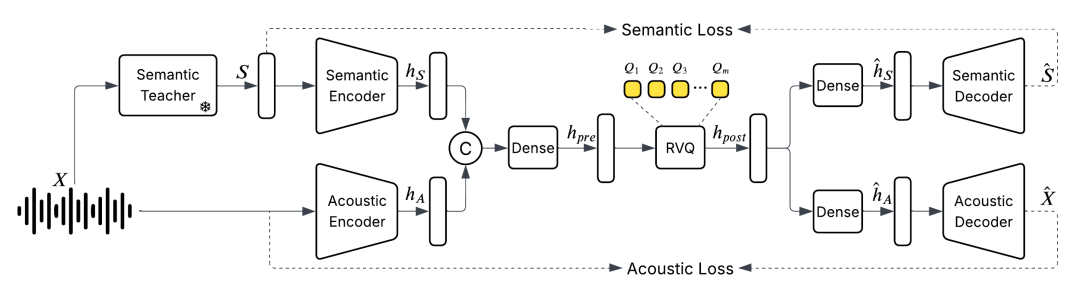
现有的方法是将一秒的语音信号裁切成多段(如100毫秒一段),为每一段匹配最相似的预定义模板(如45个模板),然后将其表示为长度为10的编号序列,也就是一个个token。
但这样做,虽然可以将一小时的音频从60兆压缩到0.16兆,但质量相当糟糕,所以需要优先保留语音的语义信息,而声学信号只保留少量部分,后续再通过其他手段还原。
于是他们训练了一个统一的离散化音频分词器,以每秒25帧的速度运行,同时保持甚至提高音频质量,以捕获语义和声学特征。
然后要让模型很好地理解和生成声音,就需要利用模型的文本空间,将语音的语义尽量地映射回文本,当中需要大量的数据支持。
由于版权问题,沐导没有使用B站或YouTube这类公开视频网站数据,而是购买或从允许抓取的网站获取。
这样得到的数据质量参差不齐,需要删除其中的90%才能满足1000万小时的训练数据需求。
其次,将语音对话表示为相应的system(场景描述、声学特征、人物特征等)、user(对话文本)、assistant(对应音频输出)的形式。
由于OpenAI和谷歌一向禁止使用他们的模型输出再训练,且训练成本过高,为了实现这种标注,他们利用相同的模型架构额外训练出一个语音模型AudioVerse。
该模型接收用户语音输入,分析并输出场景、人物、情绪、内容等信息,再将输出反过来作为生成模型的system提示和user输入,实现模型的共同进步。
举个例子就是,如果想要教一个徒弟同时会拳脚功夫,但师傅一次又教不了,那就同时教两个徒弟,一个学打拳,一个学踢腿,然后让他们俩天天互相打,打着打着两个就都会拳脚功夫了。
最终,这个多模态模型就完成了,不仅可以完成简单的文本转语音,还能实现更复杂的任务,比如让它写一首歌并唱出来,再加上配乐。
还能根据语音分析场景、人物(性别、年龄、情绪状态)、环境音(室内外),并进行复杂的理解和推理。
在实时语音聊天上,还可实现低延迟、理解情绪并表达情绪的自然语音交互,而不仅仅是机械的问答。
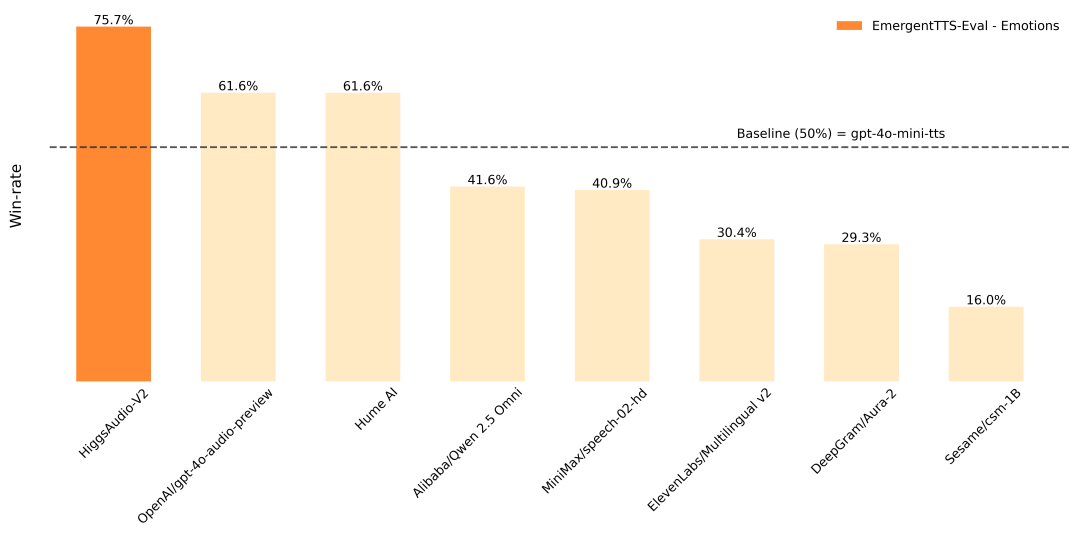
在EmergentTTS-Eval基准上,相较于其他模型,性能可以说是遥遥领先,尤其是在“情绪”和“问题”类别中,相比GPT-4o-mini-tts高出了75.7%和55.7%的胜率。
此外,它在Seed-TTS Eval和情感语音数据集 (ESD) 等传统TTS基准测试中也取得了最佳性能。
那么,我们能玩吗?相信同学们都已经跃跃欲试了。
放心,沐导都包圆了,模型代码都已全部发布在GitHub上(可点击文末链接获取~),并提供了在线试玩平台和Hugging Face版本。
想要安装在自己电脑上的同学,需要准备好GPU版Pytorch,或使用media驱动提供的Docker简化安装,readme里还有一些语音样例(包含文本和对应的音频),大家可以自行体验学习。
尤其是喜欢搞搞鬼畜视频、虚拟主播的同学们,这个模型一定要试试,它可以直接复制特定人物的声音。
不过温馨提醒,生成特定场景的文本时,最好提供类似场景中人物说话的语音信息(例如吵架、放松、大笑的语音),可以更好地进行声纹克隆嗷~
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









