



"大模型蒸馏就像让一个「学霸老师」把复杂的知识浓缩成「精华笔记」,教给一个「学生小弟」,让小弟用更轻便的方式掌握核心能力,既省资源又高效。"
导读
在人工智能快速发展的今天,模型的规模越来越大,计算成本也越来越高,这对中小型开发者来说无疑是一个巨大的挑战:如何通过将大模型的知识和能力浓缩到更小、更轻量化的模型中,降低硬件要求,以更低的成本享受到先进的人工智能技术?
DeepSeek-R1及其API的开源标志着这一领域的重要突破。
对于中小型开发者而言,这意味着他们不再需要依赖庞大的计算资源就能实现高效、强大的人工智能应用。DeepSeek提供的开源蒸馏检查点(如基于Qwen2.5和Llama3系列的1.5B、7B、8B等参数规模)为开发者提供了丰富的选择空间,无论是初创公司还是个人项目,都可以根据自身需求灵活调用这些模型。
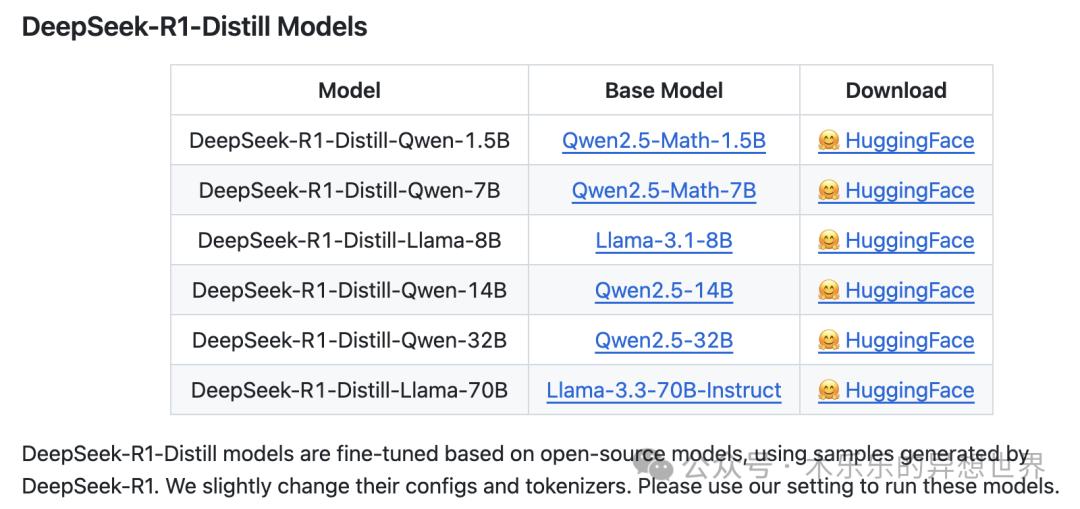
github 地址:https://github.com/deepseek-ai/DeepSeek-R1
这一技术不仅降低了人工智能的准入门槛,也为中小型开发者在资源有限的情况下实现创新提供了更多可能性。通过蒸馏模型,他们可以更专注于业务逻辑和应用场景的优化,而无需过多关注底层计算资源的限制。这无疑将推动人工智能技术在更广泛的领域中落地生根。
接下来,详细跟大家聊聊模型蒸馏。
一、为什么要用模型蒸馏?
(一)模型规模的膨胀之殇
现代深度学习模型的参数量呈指数级增长。例如,GPT-3拥有1750亿个参数,运算时需要数千张GPU卡进行训练,资源消耗巨大。这种“重量级”模型虽然性能优越,但在实际应用中面临诸多限制:
- 硬件需求高:难以在普通设备(如手机、边缘服务器)上运行。
- 推理时间长:处理速度较慢,影响用户体验。
- 成本高昂:无论是训练还是部署,都需要大量计算资源支持。
(二)知识传递的高效之道
模型蒸馏的核心思想是将“大模型”中的知识提取出来,传授给一个更小、更轻量的学生模型。这种知识传递的过程类似于人类的教学:
- 教师模型(Teacher Model):扮演“学霸老师”的角色,掌握全面的知识。
- 学生模型(Student Model):作为“学生”,需要快速掌握核心知识点。
通过蒸馏技术,学生模型可以继承教师模型的精华,同时摆脱其臃肿的身躯。这种方式既保持了高性能,又大幅降低了资源消耗。
(三)应用场景的迫切需求
在很多实际场景中,大模型的应用面临以下挑战:
- 移动端部署:需要轻量化模型。
- 实时推理:要求快速响应。
- 成本控制:希望降低算力开销。
模型蒸馏技术正好能够满足这些需求,为AI技术的普惠发展提供了新的可能。
二、模型蒸馏是如何工作的?
(一)知识蒸馏的基本原理
知识蒸馏是一种迁移学习的技术。具体来说:
- 教师模型:首先需要在大规模数据上进行训练,掌握丰富的知识点。
- 蒸馏过程:
- 教师模型对输入样本给出预测结果和概率分布(软标签)。
- 学生模型通过模仿教师的输出,学习到更细粒度的知识。
- 学生模型:经过蒸馏后,能够掌握接近甚至超越教师模型的能力。
(二)蒸馏的具体实现方法
- 软标签蒸馏:
- 教师模型输出概率分布(Soft Labels),而非单一类别标签。
- 学生模型通过最小化预测结果与软标签之间的差异来学习。
- 硬标签蒸馏:
- 使用教师模型的预测类别作为监督信号。
- 混合策略:
- 结合多种蒸馏方法,提升效果。
(三)如何选择学生模型?
- 结构设计:根据具体需求设计轻量级的学生网络架构(如deepseek 使用的 qwen 和Llama等)。
- 参数调整:通过蒸馏过程优化学生的参数,使其更好地模仿教师的行为模式。
三、知识传递的方式与策略
在具体的蒸馏过程中,可以根据不同的需求选择多种策略:
离线蒸馏
教师模型在训练完成后保持固定状态,学生模型单独进行训练。这种模式类似于传统的教学方式,教师的知识已经固化,学生通过模仿学习掌握技能。
- 优点:易于实现,适合大规模部署
- 缺点:需要大量标注数据
GPT 提供的蒸馏方案,就属于这种类型的。
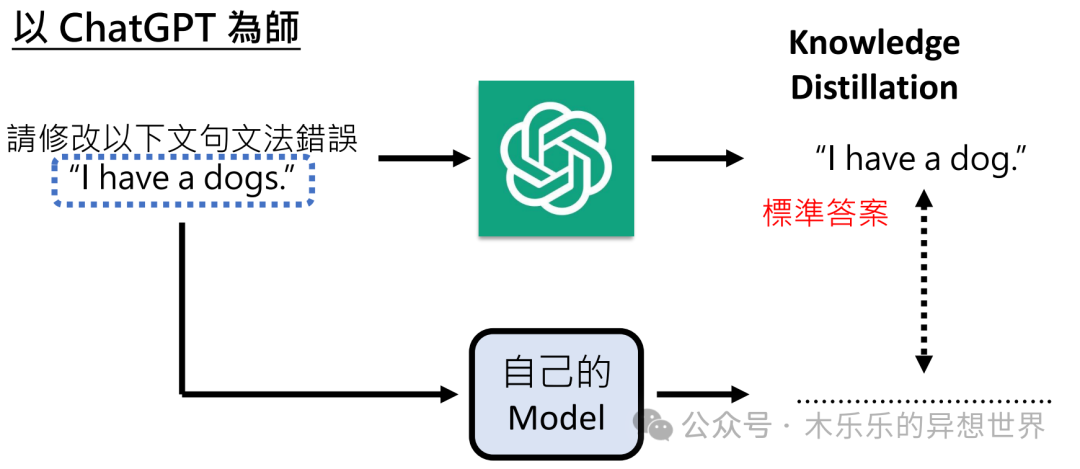
链接:https://arxiv.org/abs/2212.10560
链接:https://platform.openai.com/docs/guides/distillation
在线蒸馏
教师和学生模型同时参与训练过程,两者互相影响、共同优化。这种方法更接近于师生互动的教学场景。
- 优点:能够充分利用教师的实时反馈
- 缺点:实现复杂度较高
自蒸馏
同一个模型既当老师又当学生,即同一模型的不同部分之间进行知识传递,例如利用中间层特征作为监督信号。
- 优点:不需要额外的教师模型
- 缺点:需要精心设计内部结构
在选择具体策略时,需要综合考虑计算资源、数据规模和性能需求等因素。
案例:Target-driven Self-Distillation for Partial Observed Trajectories Forecasting
提出了一种目标驱动的自蒸馏方法,用于部分观测轨迹预测任务,通过自蒸馏使模型能够从自身预测结果中学习,提升预测精度
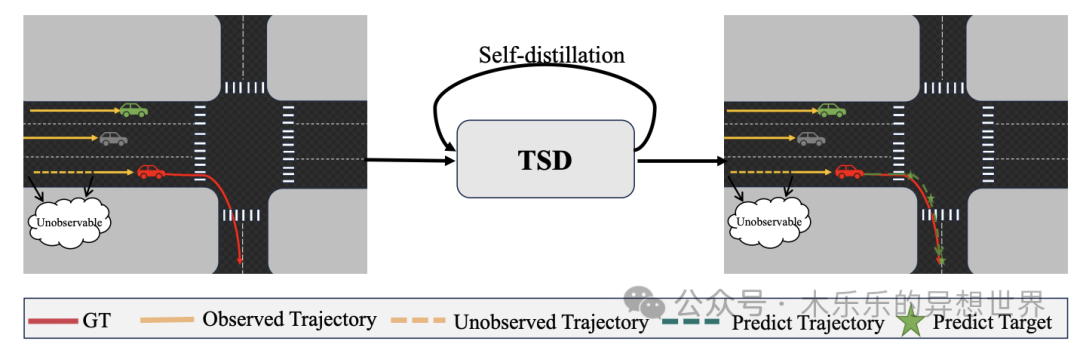
参考论文:https://arxiv.org/pdf/2501.16767
四、知识的载体与形式
模型蒸馏不仅仅是简单的参数复制,更涉及到多维度的知识传递。常见的知识表示形式包括:
结果型知识(输出层知识)
这是最直接的方式,通过对比教师和学生的输出概率分布来衡量差异。这种方法适用于分类等任务。
- 示例:用户商品偏好知识学习。
Preference-Consistent Knowledge Distillation for Recommender System
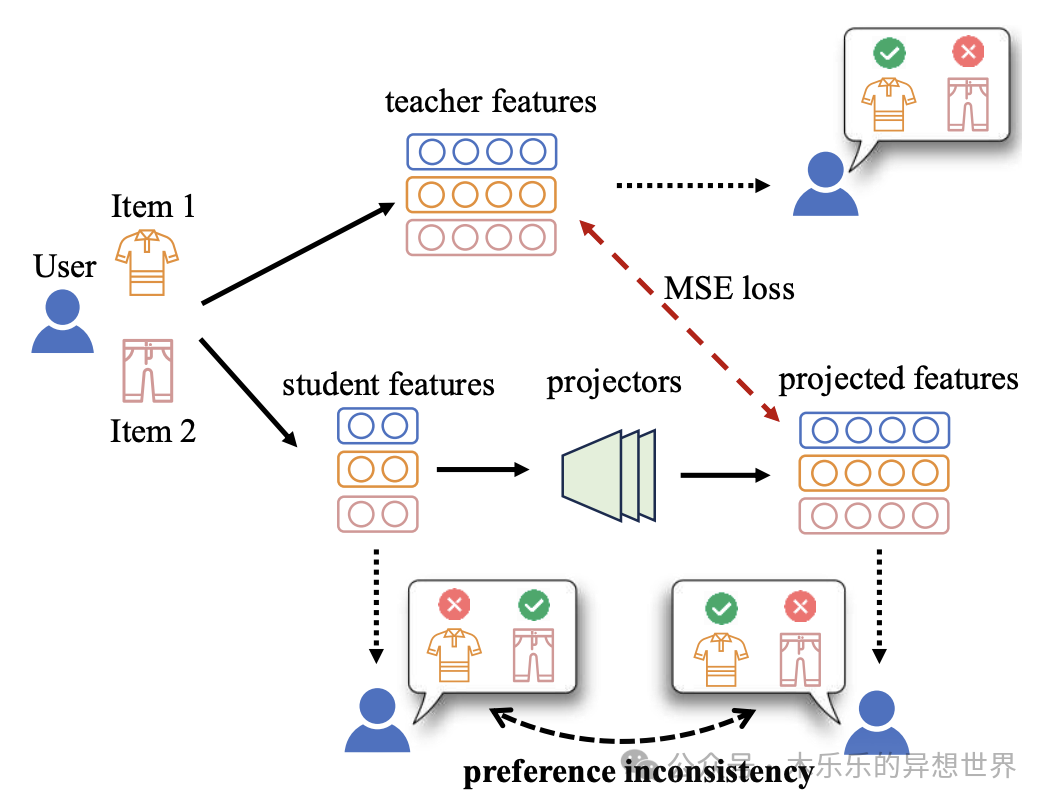
链接:https://arxiv.org/pdf/2311.04549
特征型知识(中间层特征)
基于特征的知识蒸馏方法的目标是训练学生模型学习与教师网络相同的特征。基于特征的蒸馏损失函数用于测量,然后最小化两个网络的特征激活之间的差异。
- 例如,在主要用于图像分割等计算机视觉任务的卷积神经网络中,随着数据在网络中传输,每个连续的隐藏层都会逐渐捕获更丰富的细节。在用于按物种对动物图像进行分类的模型中,最早的隐藏层可能只是辨别照片的一部分中存在动物形状;中间的隐藏层可能会辨别出动物是鸟类;最后的隐藏层(就在输出层之前)将辨别出区分一种鸟类与另一种密切相关物种的细微细节。
示例:Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
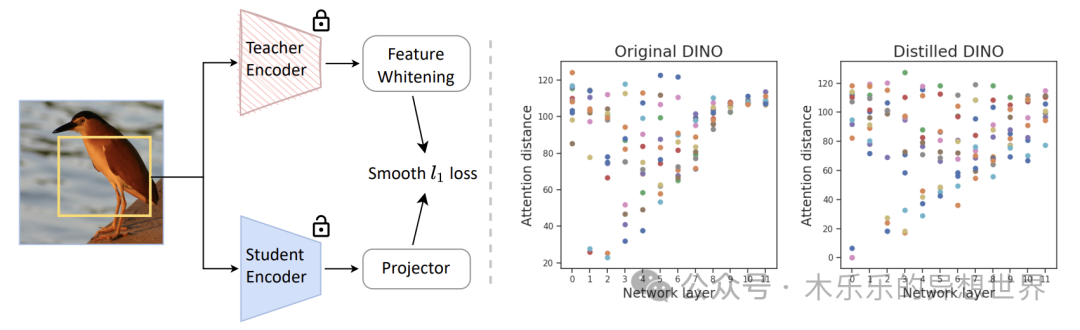
地址:https://arxiv.org/abs/2205.14141
规律型知识(关系知识)
捕捉样本之间的关系或特征间的关联性,例如通过对比学习的方式传递相似性信息。代表了训练学生网络以模拟教师模型的“思维过程”的综合方法。这些关系和相关性可以通过多种方式进行建模,包括特征图之间的相关性、表示不同层之间相似性的矩阵、特征嵌入或特征表示的概率分布。
- 示例:A Unified View of Masked Image Modeling
一种基于语言辅助表示的掩码图像预训练方法,旨在通过利用图像的文本描述来减少对大规模标注数据集的依赖。
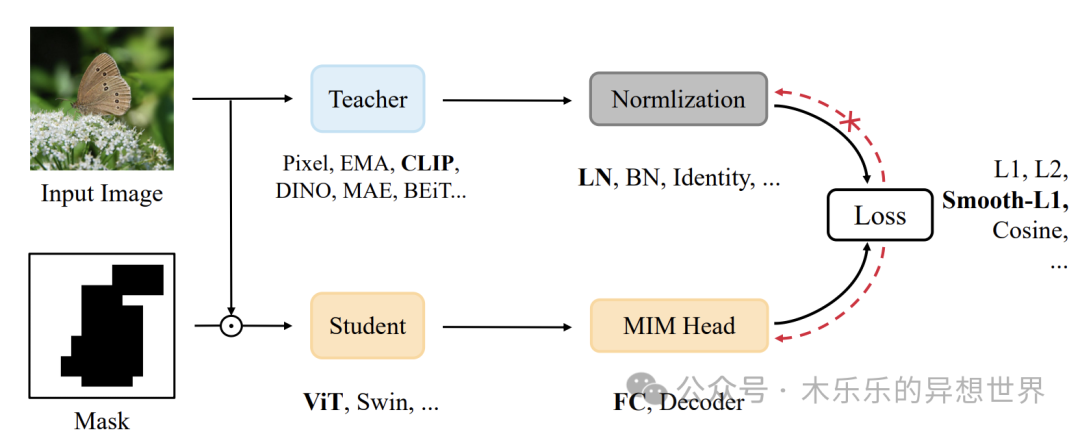
链接:https://arxiv.org/abs/2210.10615
五、模型蒸馏的落地应用
(一)实际场景中的成功案例
- 移动端自然语言处理:
- 使用蒸馏技术将大规模语言模型压缩为适合手机运行的小模型。
- 用户可以在本地完成文本生成、机器翻译等任务,无需依赖云端。
- 工业界的应用探索:
- 在图像识别领域,通过蒸馏优化边缘设备的部署效率。
- 在推荐系统中,利用蒸馏技术提升实时响应速度。
(二)如何衡量蒸馏效果?
- 性能评估:对比蒸馏前后的模型在相同任务上的准确率、F1值等指标。
- 资源消耗分析:
- 比较两者的计算资源需求(如GPU内存占用、推理时间等)。
(三)实际应用中的挑战
- 知识传递的完整性:如何确保学生模型能够继承教师的所有关键知识点?
- 蒸馏效率的优化:如何在有限的时间内完成高效的蒸馏过程?
六、未来发展的可能性
(一)与其它技术的结合
- 联邦学习(Federated Learning):
- 在数据隐私保护的前提下,通过蒸馏技术实现知识共享。
- 边缘计算(Edge Computing):
- 利用蒸馏模型提升边缘设备的智能化水平。
(二)更高效的蒸馏方法
- 自适应蒸馏:根据具体任务需求动态调整蒸馏策略。
- 多教师学习:引入多个教师模型,进一步丰富知识来源。
(三)应用场景的拓展-跨模态学习
- 在图像、文本等多种数据类型之间进行知识传递。
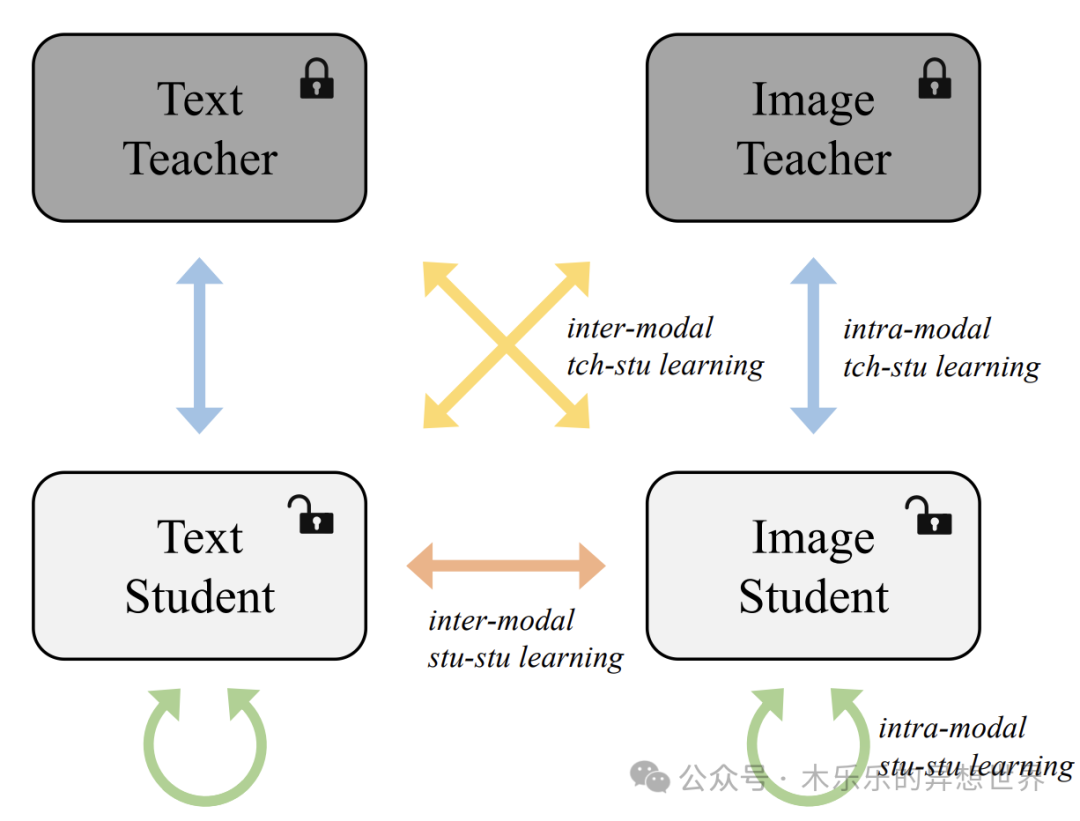
参考论文地址:https://arxiv.org/pdf/2305.17652
模型蒸馏技术为大模型的落地应用开辟了一条新的道路。它不仅解决了资源消耗过高的问题,还为AI技术的普惠发展提供了重要支持。随着技术的不断进步,我们有理由相信,在不久的将来,轻量化但高性能的模型将能够广泛服务于各个领域,推动人工智能技术真正走进人们的生活。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









