



本文将深入探讨如何使用 FastAPI、LangChain 和 Ollama 来构建一个 支持多轮对话 的智能聊天机器人。
通过本文,你将学会:
-
1. 如何利用 LangChain 和 FastAPI 进行 API 设计。
-
2. 如何使用 会话管理 来支持多轮对话。
-
3. 如何优化聊天机器人的 提示模板 以提升响应质量。
环境搭建
在开始实际编码之前,首先需要搭建一个干净、稳定的开发环境。本文推荐使用 conda 管理虚拟环境,并利用 pip 安装所需的依赖包。以下将详细介绍如何创建环境并安装相关依赖。
创建开发环境
使用 conda 创建一个独立的虚拟环境,可以确保项目间依赖不会相互干扰。执行以下命令,即可创建名为 langchain-api 的 Python 3.10 环境:
bin/conda create -n langchain-api python=3.10
这条命令会自动下载并安装 Python 3.10,同时为该环境配置基本的包管理工具。使用虚拟环境不仅有助于依赖的隔离,还能在需要时轻松切换不同版本的 Python 环境,适应各种项目需求。
在创建环境后,记得激活该环境:
conda activate langchain-api
安装依赖包
在环境搭建好后,我们需要安装实现 API 所需的各个依赖包。本文主要涉及以下几个核心组件:
-
• langserve:用于将 LangChain 链封装为 API 路由,便于与 FastAPI 集成。
-
• langchain:核心链式处理框架,负责提示模板、模型调用等功能。
-
• langchain_community:社区扩展包,提供了与 Ollama 大语言模型交互的接口。
-
• FastAPI:轻量级、高性能的 Web 框架,用于构建 API 服务。
pip install "langserve[all]"
pip install langchain
pip install langchain_community
pip install fastapi
实现原理与代码详解
在完成环境搭建之后,接下来的重点工作便是构建 API 服务。本文将结合代码示例,详细介绍如何利用 LangChain 与 Ollama 模型进行交互,并将整个流程封装为一个 API 接口。
环境依赖导入与模型初始化
import os
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.llms import Ollama
from langserve import add_routes
设置环境变量
import os
os.environ["MODEL_NAME"] = "deepseek-r1:14b"
os.environ["BASE_URL"] = "http://xxx.xxx.xxx.xxx:11434" # 请替换为实际的Ollama模型服务地址
语言模型(LLM)初始化
我们使用 Ollama 作为语言模型,它支持 API 访问:
from langchain_community.llms import Ollama
llm = Ollama(
model=os.environ["MODEL_NAME"],
base_url=os.environ["BASE_URL"],
temperature=0.3 # 控制生成随机性,0.3 表示输出稳定但仍有一定随机性
)
优化建议:
-
•
temperature=0.3表示平衡创造性与稳定性。如果你的应用更需要精准回答(如金融、法律),可以设为0.1,而如果更注重对话自然性,可以调高到0.7。 -
• 可选模型优化:如果你要使用 OpenAI API 或其他模型,LangChain 允许快速切换,例如:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
model_name="gpt-4",
api_key=os.getenv("OPENAI_API_KEY")
)
提示模板(Prompt Template)
良好的 Prompt Design 直接影响 LLM 的回答质量,我们可以使用 ChatPromptTemplate 进行定义:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt_template = ChatPromptTemplate.from_messages([
('system', '你是一个支持多轮对话的AI助手,请确保回答简明且准确。'),
MessagesPlaceholder(variable_name='history'),
('human', '{input}') # 用户的输入
])
实际应用优化建议
- • 提升提示词质量,例如:
('system', '你是一个专业的AI助手,能够处理用户的问题,并根据上下文提供精准的回答。请遵循以下规则:1. 避免冗长 2. 仅在必要时请求更多信息 3. 保持友好而专业。') - • 增加
role适配性,例如客服聊天机器人可以使用:('system', '你是一个客户支持助手,请基于历史对话提供最符合用户需求的帮助。')
多轮会话管理
为了实现 持久化会话,我们使用 ChatMessageHistory:
from langchain_community.chat_message_histories import ChatMessageHistory
session_store = {}
def get_session_history(session_id: str) -> ChatMessageHistory:
if session_id not in session_store:
session_store[session_id] = ChatMessageHistory()
return session_store[session_id]
实际应用优化方案:
- • 使用 Redis 作为持久化存储:
这样可以支持跨进程会话管理,适用于集群部署。from langchain.memory import RedisChatMessageHistory session_store = {} def get_session_history(session_id: str) -> RedisChatMessageHistory: if session_id not in session_store: session_store[session_id] = RedisChatMessageHistory(url="redis://localhost:6379", session_id=session_id) return session_store[session_id]
处理管道(Processing Pipeline)
构建聊天处理流程:
from langchain_core.runnables import RunnableWithMessageHistory
defconvert_output_to_dict(output: str):
return {"response": output}
conversation_chain = (
prompt_template
| llm
| convert_output_to_dict
)
chain_with_history = RunnableWithMessageHistory(
conversation_chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
优化建议:
- • 可以添加 token 限制,避免 LLM 输出过长:
llm = Ollama( model=os.environ["MODEL_NAME"], base_url=os.environ["BASE_URL"], temperature=0.3, max_tokens=500 # 限制最大输出字数 )
API 服务(FastAPI)
我们使用 FastAPI 作为后端:
from fastapi import FastAPI
from langserve import add_routes
app = FastAPI(
title="Multi-Turn Chat API",
version="1.0",
description="支持多轮对话的智能聊天接口"
)
add_routes(
app,
chain_with_history,
path="/chat",
input_type=dict
)
# 运行服务
if __name__ == "__main__":
import uvicorn
uvicorn.run(
app,
host="0.0.0.0",
port=12345
)
调用效果
开启第一个会话
curl -X POST http://localhost:12345/chat/invoke \
-H "Content-Type: application/json" \
-d '{
"input":
{
"input":"你好,我是齐得隆咚呛"}
,
"config": {
"configurable": {
"session_id": "session-1"
}
}
}'
得到结果
你好!很高兴认识你,齐得隆咚呛。听起来像是一个有趣的名字!今天有什么我可以帮你的吗?
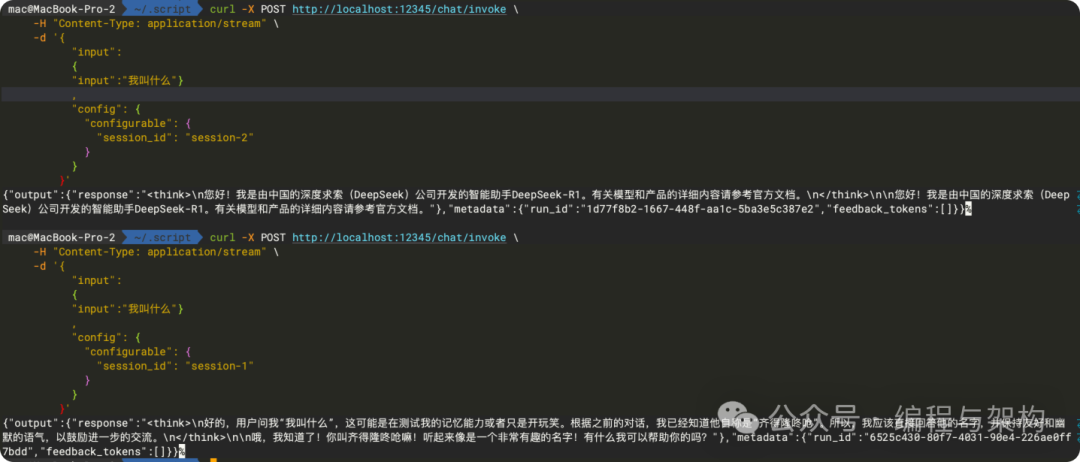
下面我分别用 session-1和 session-2 来问他,发现只有 session 相同时,他才知道我叫什么。说明基于 session 会话成功。
curl -X POST http://localhost:12345/chat/invoke \
-H "Content-Type: application/json" \
-d '{
"input": {
"input": "你好,我是齐得隆咚呛"
},
"config": {
"configurable": {
"session_id": "session-1"
}
}
}'
curl -X POST http://localhost:12345/chat/invoke \
-H "Content-Type: application/stream" \
-d '{
"input": {
"input": "我叫什么"
},
"config": {
"configurable": {
"session_id": "session-1"
}
}
}'
curl -X POST http://localhost:12345/chat/invoke \
-H "Content-Type: application/stream" \
-d '{
"input": {
"input": "我叫什么"
},
"config": {
"configurable": {
"session_id": "session-2"
}
}
}'
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

















 2725
2725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









