



在企业中,每家公司都有自己的规章制度、新员工手册、某个工作的流程指南、或自家产品的介绍信息等。这些内容可能以不同的形式散落在不同的地方,需要查询的时候要到不同的地方去搜索查找,还可能会找不到,信息的获取成本比较高。现在借助大模型和 RAG 技术(检索增强生成 Retrieval-Augmented Generation)我们可以以一种比较统一的方式把这些内容集中起来,搭建成一个知识库,并以问答的形式获取我们想要查找的内容,大大降低了信息的获取成本。
这篇文章就讲一下如何基于 RAG 技术和大模型搭建自己的知识库,仓库地址,可以在这里看完整的代码。
原理说明
下面是大致的原理图。我们首先收集资料,这些资料包括文本、PDF、网页、图片、视频等,然后使用 embedding 模型把它们编码成向量,存储到向量数据库中。接下来在我们搜索内容的时候,系统会把我们搜索的内容也编码成向量,然后查询向量数据库,比较我们要查询的向量和数据库中已有的向量之间的相似度,返回最相似的几条数据。然后我们把这些相似数据和我们的问题一起发送给大模型,大模型再结合我们查询到的资料内容和模型中已有的数据进行处理,返回最终的答案。
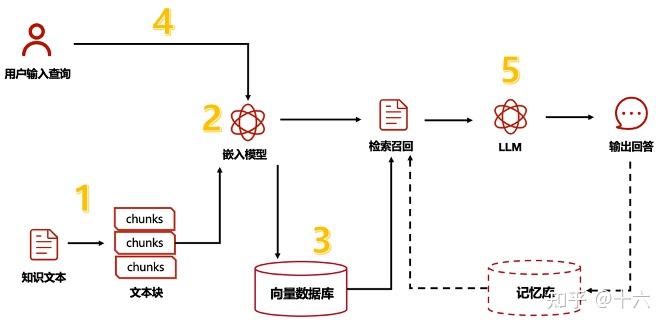
下面我们就结合具体的代码来看如何实现这个系统,完整的代码在这个仓库的 examples/knowledge-base 目录下。
拆分文档
首先我们需要对文档进行拆分,因为我们的文档长度可能会非常长,而大模型一次能处理的内容长度有限,超出长度限制之后模型接口会报错,所以我们首先需要对文档进行拆分。
我们现在的代码实现中,目前处理了 txt 文本和 html 文档,没有处理图片和 PDF 等格式的资料,所以下面的代码只讲这两种文档的处理方式,其他格式的文档处理可能后续再进行更新。
拆分 txt 文档
首先是 txt 文本,我们可以从网上下载一个书籍的 txt 文档,这里不提供具体的 txt 文件。txt 文本一般比较大,如果是书籍,可能会有几十万字甚至上百万字,因此分块是非常有必要的。
拆分文档也有一些策略,比如说我们可以采用固定长度分割文档, 每 500 个字分一个块,这种方式是一种比较简单的策略。但是采用固定的字数分块可能会在中间把一些句子切分开,会影响查询的效果。我们还可以再迭代一下,比如基于段落分块,如果段落大于 500 个字,我们再把段落拆分开,拆分的时候基于符号进行分割,比如 ,.,。等符号。如果句子也太长的话,我们可以进行分词,把句子拆分开,拆分句子的时候可以通过语义分析句子,避免直接把一个词从中间拆分开。这样处理完成之后,我们就得到了一个文本数组,数组中是分块过后的文本。
拆分文档的策略,可以看一下这个文章,这里面讲了几种不同的拆分文档方式:文本拆分的五个级别
下面是拆分 txt 内容的代码:
from langchain_text_splitters import RecursiveCharacterTextSplitter
async def get_texts_from_txt(self, file: UploadFile = File(...)):
"""从 txt 文件中读取文本"""
content = await file.read()
content_str = content.decode("utf-8")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_text(content_str)
return texts我们使用了 langchain 的工具库,方便我们分割文本,具体的可以看文档 langchain 参考文档。
这里面的方法的两个关键参数含义:chunk_size :块的最大大小;chunk_overlap :块之间的目标重叠数量,当上下文被分割在块之间时,重叠的块有助于减少信息丢失。我们这里用了 300 和 20 作为演示。
我使用了《围城》小说做了一个例子,下面是分块的一些结果,每个分块长度会在 300 以内,同时如果一个段落被截取到两个文本中的话,前后会有一些重叠的句子:
[
"方鸿渐到了欧洲,既不钞敦煌卷子,又不访《永乐大典》,也不找太平天国文献,更不学蒙古文、西藏文或梵文。四年中倒换了三个大学,伦敦、巴黎、柏林;随便听几门功课,兴趣颇广,心得全无,生活尤其懒散。第四年春天,他看银行里只剩四百多镑,就计划夏天回国。方老先生也写信问他是否已得博士学位,何日东归,他回信大发议论,痛骂博士头衔的毫无实际。方老先生大不谓然,可是儿子大了,不敢再把父亲的尊严去威胁他;便信上说,自己深知道头衔无用,决不勉强儿子",
",但周经理出钱不少,终得对他有个交代。过几天,方鸿渐又收到丈人的信,说什么:“贤婿才高学富,名满五洲,本不须以博士为夸耀。然令尊大人乃前清孝廉公,贤婿似宜举洋进士,庶几克绍箕裘,后来居上,愚亦与有荣焉。”\n\n方鸿渐受到两面夹攻,才知道留学文凭的重要。这一张文凭,仿佛有亚当、夏娃下身那片树叶的功用,可以遮羞包丑;小小一方纸能把一个人的空疏、寡陋、愚笨都掩盖起来。",
"自己没有文凭,好像精神上赤条条的,没有包裹。可是现在要弄个学位。无论自己去读或雇枪手代做论文,时间经济都不够。就近汉堡大学的博士学位,算最容易混得了,但也需要六个月,干脆骗家里人说是博士罢,只怕哄父亲和丈人不过;父亲是科举中人,要看“报条”,丈人是商人,要看契据。\n\n他想不出办法,准备回家老着脸说没得到学位,一天,他到柏林图书馆中国书编目室去看一位德国朋友,瞧见地板上一大堆民国初年上海出的期刊,《东方杂志》、《小说月报》、《大中华》、《妇女杂志》全有。",
"信手翻着一张中英文对照的广告,是美国纽约什么“克莱登法商专门学校函授班,将来毕业,给予相当于学士、硕士或博士之证书,章程函索即寄,通讯处纽约第几街几号几之几,方鸿渐心里一运,想事隔二十多年,这学校不知是否存在,反正去封信问问,不费多少钱。\n\n那登广告的人,原是个骗子,因为中国人不来上当,改行不干了,人也早死了。他住的那间公寓房间现在租给一个爱尔兰人,具有爱尔兰人的不负责、爱尔兰人的急智、还有爱尔兰人的穷。\n\n相传爱尔人的不动产(Irishfortune)是奶和屁股;这位是个萧伯纳式既高且瘦的男人,那两项财产的分量又得打折扣。",
"他当时在信箱里拿到鸿渐来信,以为邮差寄错了,但地址明明是自己的,好奇拆开一看,莫名其妙,想了半天,快活得跳起来,忙向邻室小报记者借个打字机,打了一封回信,说先生既在欧洲大学读书,程度想必高深,无庸再经函授手续,只要寄一万字论文一篇附缴美金五百元,审查及格,立即寄上哲学博士文凭,回信可寄本人,不必写学术名字。\n\n署名PatricMahoney,后面自赠了四五个博士头衔。方鸿渐看信纸是普通用的,上面并没刻学校名字,信的内容分明更是骗局,搁下不理。爱尔兰人等急了,又来封信,们如果价钱嫌贵,可以从长商议,本人素爱中国,办教育的人尤其不愿牟利。",
"方鸿渐盘算一下,想爱尔兰人无疑在捣鬼,自己买张假文凭回去哄人,岂非也成了骗子?可是--记着,方鸿渐进过哲学系的--撒谎欺骗有时并非不道德。\n\n柏拉图《理想国》里就说兵士对敌人,医生对病人,官吏对民众都应哄骗。圣如孔子,还假装生病,哄走了儒悲,孟子甚至对齐宣王也撒谎装病。父亲和丈人希望自己是个博士,做儿子女婿的人好意思教他们失望么?买张文凭去哄他们,好比前清时代花钱捐个官,或英国殖民地商人向帝国府库报效几万镑换个爵士头衔,光耀门楣,也是孝子贤婿应有的承欢养志。反正自己将来找事时,履历上决不开这个学位。"
]拆分 html 文档
langchain 也有 html 文档的分块工具,下面是演示代码:
from langchain_text_splitters import HTMLSectionSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
]
html_splitter = HTMLSectionSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
html_header_splitsHTMLSectionSplitter 会基于 h1 和 h2 标签把内容进行分段,具体的可以查询 langchain 的文档。
我用搜狐新闻的网页做了测试,实际提取出来的内容里面会有比较多的冗余信息,比如 js 代码和 css 代码、多余的标签等,需要再做单独处理。因此针对搜狐新闻的网页,我这里并没有用 HTMLSectionSplitter,这里的代码用了 BeautifulSoup 这个库对新闻的正文做提取。同时,因为搜狐新闻的正文主要在 class="post_body" 这个 div 标签下面,因此我用了 post_body = soup.find(class_="post_body") 先把主要的正文片段提取出来,再解析文本。对解析后的文本进行拆分,还是使用的 RecursiveCharacterTextSplitter 这个工具方法。处理完成的文本,类似上面《围城》的文本,会把文本分成不同的片段。
这里的代码:
from bs4 import BeautifulSoup
async def get_texts_from_html(self, url: str):
"""从 html 文件中读取文本"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Referer": url, # 伪造来源
"Accept-Language": "zh-CN,zh;q=0.9",
}
response = requests.get(url, headers=headers)
response.raise_for_status()
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# souhu的新闻网页格式
post_body = soup.find(class_="post_body")
texts = []
# 提取其中的文本内容
if post_body:
text = post_body.get_text(separator="\n", strip=True) # 使用换行符分隔段落
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.split_text(text)
return texts把文本变成向量
把文本变成向量,需要使用向量模型。huggingface 上有很多 embedding 模型,不同的模型支持的语言不同,他们的效果也有差异。综合网上的对比之后,在项目中使用了 BAAI/bge-m3 这个向量模型。
代码如下:
from sentence_transformers import SentenceTransformer
DB_DIR = "./lancedb_data"
TABLE_NAME = "vector_store"
VECTOR_DIMENSION = 1024 # 根据模型输出维度设置
def __init__(self):
self.model = SentenceTransformer("BAAI/bge-m3")
async def create_embedding(self, file: UploadFile = File(...), type: str = "txt", url: str = ""):
texts = await self.split_text(file, type, url)
# 生成向量
embeddings = self.model.encode(texts)通过 self.model.encode(texts) 就可以把文本变成向量,还是比较简单的。
保存向量到数据库
上面的代码把文本变成向量,接下来我们需要把向量保存到数据库中。
这里的数据库使用的 lancedb。
这部分代码如下:
def __init__(self):
"""初始化数据库连接和模型"""
self.db = lancedb.connect(DB_DIR)
self._initialize_table()
def _initialize_table(self):
# 定义 Schema(PyArrow ≥ 12.0)
# 指定vector的长度非常非常重要!
schema = pa.schema([
pa.field("id", pa.int64()),
pa.field("item", pa.string()),
pa.field("vector", pa.list_(pa.float32(), list_size=VECTOR_DIMENSION)) # 直接指定长度,一定要指定长度,否则搜索的时候会报错
])
# 创建表
if TABLE_NAME not in self.db.table_names():
self.table = self.db.create_table(TABLE_NAME, schema=schema)
else:
self.table = self.db.open_table(TABLE_NAME)
async def create_embedding(self, file: UploadFile = File(...), type: str = "txt", url: str = ""):
texts = await self.split_text(file, type, url)
embeddings = self.model.encode(texts)
start_id = self.table.count_rows()
# 构建数据
data = [
{
"id": start_id + i,
"item": line,
"vector": emb
}
for i, (line, emb) in enumerate(zip(texts, embeddings))
]
# 插入数据
self.table.add(data)
return {"message": f"成功存储{len(texts)}条数据"}首先通过 schema = pa.schema 定义表的结构,然后 self.db.create_table(TABLE_NAME, schema=schema) 创建数据表。之后使用 encode 之后的 embedding 数据和原始文本数据,组装数据为符合数据表结构的格式,然后插入到数据表中,就完成了存储向量到数据库的步骤。其中在定义数据表的 schema 的时候,需要明确指定向量的维度,否则在搜素的时候会报错。
检索数据
接下来,我们想搜索资料的时候,需要能够把我们存储到向量数据库中的数据搜索出来,代码如下:
async def search(self, query: str, top_k: int = 3):
"""执行向量搜索"""
# 生成查询向量
query_vector = self.model.encode(query)
# 调整维度格式
if query_vector.shape != (VECTOR_DIMENSION,):
raise HTTPException(500, "查询向量维度错误")
# 执行搜索
try:
results = self.table.search(query_vector) \
.limit(top_k) \
.to_pandas()
except Exception as e:
raise HTTPException(500, f"搜索失败: {str(e)}")
# 格式化结果
return [
{"content": row["item"], "distance": row["_distance"]}
for _, row in results.iterrows()
]我们需要先把查询的内容变成向量,然后使用向量搜索,指定需要的条数,数据库会返回最相近的几条数据。这个是搜索的代码:self.table.search(query_vector).limit(top_k)。然后把搜索到的数据的原始文本和距离信息返回即可。
LLM结合检索数据生成回答
上面通过向量数据库搜索到数据之后,我们把文本数据取出来,让大模型结合上下文资料以及用户的问题给出回答,就能得到我们想要的结果。
下面是这里的代码:
async def chat_with_knowledge(self, query: str):
# 生成查询向量
results = await self.search(query, 3)
context_str = "\n".join(item["content"] for item in results)
messages = [
{"role": "system", "content": "你是一个有知识的机器人"},
{"role": "user", "content": context_str + "\n 基于上下文,回答这个问题: " + query}
]
results = await llm_service.generate_response(text_llm_model="gpt-4o", messages=messages)
return {
"content": results
}我用《围城》小说内容创建向量存储到数据库之后,调用上面的代码做测试:
# 输入数据:
{
"query": "方鸿渐上学的信息"
}
模型的回答:
{
"content": "方鸿渐在欧洲的留学经历可以总结为:尽管他有机会在多个地方学习,但并没有集中精力完成学业。他在欧洲的四年多时间中没有专注于任何一个特定的领域或追求学术成就,反而在伦敦、巴黎和柏林之间辗转,听了几门课,但并未深入学习以至于获得什么显著成果。此外,他在经济上也并不宽裕,以至于在第四年春天看到银行存款所剩无几时,不得不计划在夏天回国。他对学术称号的价值持怀疑态度,对父亲的期望也十分不屑,表现出一种玩世不恭的态度。综上所述,方鸿渐的留学生涯并不成功,缺乏明确的目标和实际的收获。"
}模型给的回答参考了《围城》小说中的段落,然后给了回复,整体还是符合我们的需求的。
总结
通过上面的步骤,我们先提供 txt 和 html 内容创建向量,保存向量数据到数据库。然后进行搜索,获取到相似的数据,发送给大模型,大模型结合提供的数据给出答复。到这里大致就完成了整个流程。完整的代码参考这里的仓库。
当然,这个完整的流程中,还是有很多的细节可以优化的。比如不同的文档拆分策略、不同的向量模型的效果、召回数据的时候如果所需的数据在不同的片段中,以及不同的问法对搜索的影响等,这些都可以作为专题来进行研究。这其中的一些内容我们后续再专门写文章进行分析。
接下来的文章,我们会再结合知识库和企业微信、飞书等的 API ,搭建一个群聊中的答疑机器人来回复用户的问题。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 2720
2720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









