




 本文介绍了一位Python初学者在爬取大众点评网站时遇到的字体加密反爬问题。通过观察网络字体文件并使用fontCreator软件,解析字体编码,创建字典映射关系,实现在爬取页面时替换加密字符。提供了详细的操作步骤和参考资料。
本文介绍了一位Python初学者在爬取大众点评网站时遇到的字体加密反爬问题。通过观察网络字体文件并使用fontCreator软件,解析字体编码,创建字典映射关系,实现在爬取页面时替换加密字符。提供了详细的操作步骤和参考资料。
大家好,我是python小白,今天记录一下我的爬虫学习之路,在爬取大众点评网站的时候遇到的问题。
首先访问该网站的时候,打开浏览器检查工具,我们可以看到他将一些数据进行了加密,以防止爬客对这些数据进行抓取:

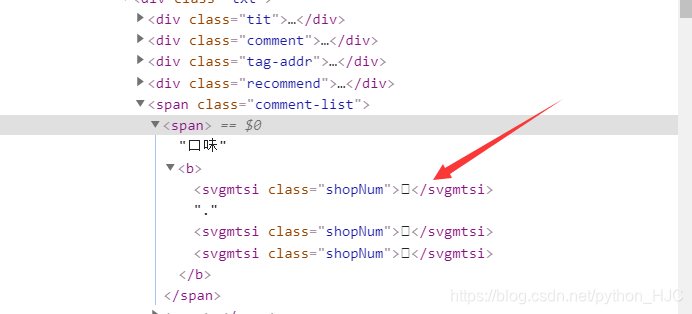
像这样的加密属于字体加密,网页使用了自定义的字体文件,我们需要利用好浏览器的检查工具去查找它所使用的的字体文件。
打开network——>font,我们可以看到所使用的字体文件。但每刷新页面或者重新进入此链接,字体文件都不一样,网上的大佬们都是获取到字体文件的链接然后下载下来做比较,这里我就用笨一点办法啦,据我观察,所使用的字体文件总共有四个我都下载下来(此方法只适合使用的字体文件不多的情况):
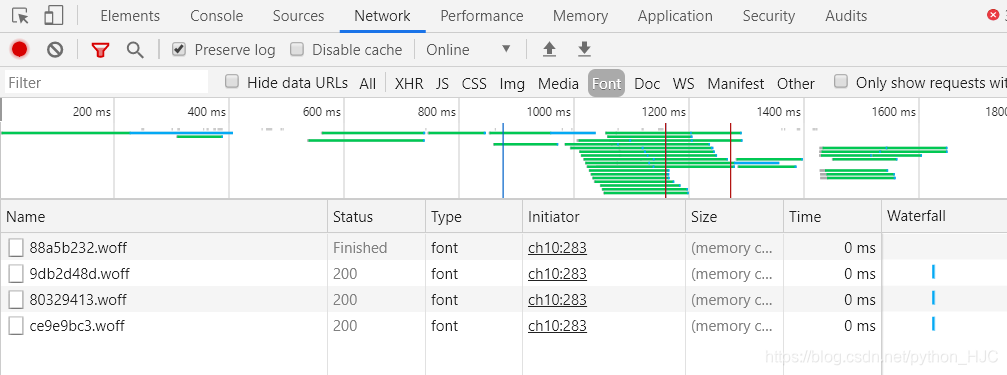
下载下来之后用fontCreator软件打开字体文件,通过观察,发现每个字体文件中字体的编码都不一样
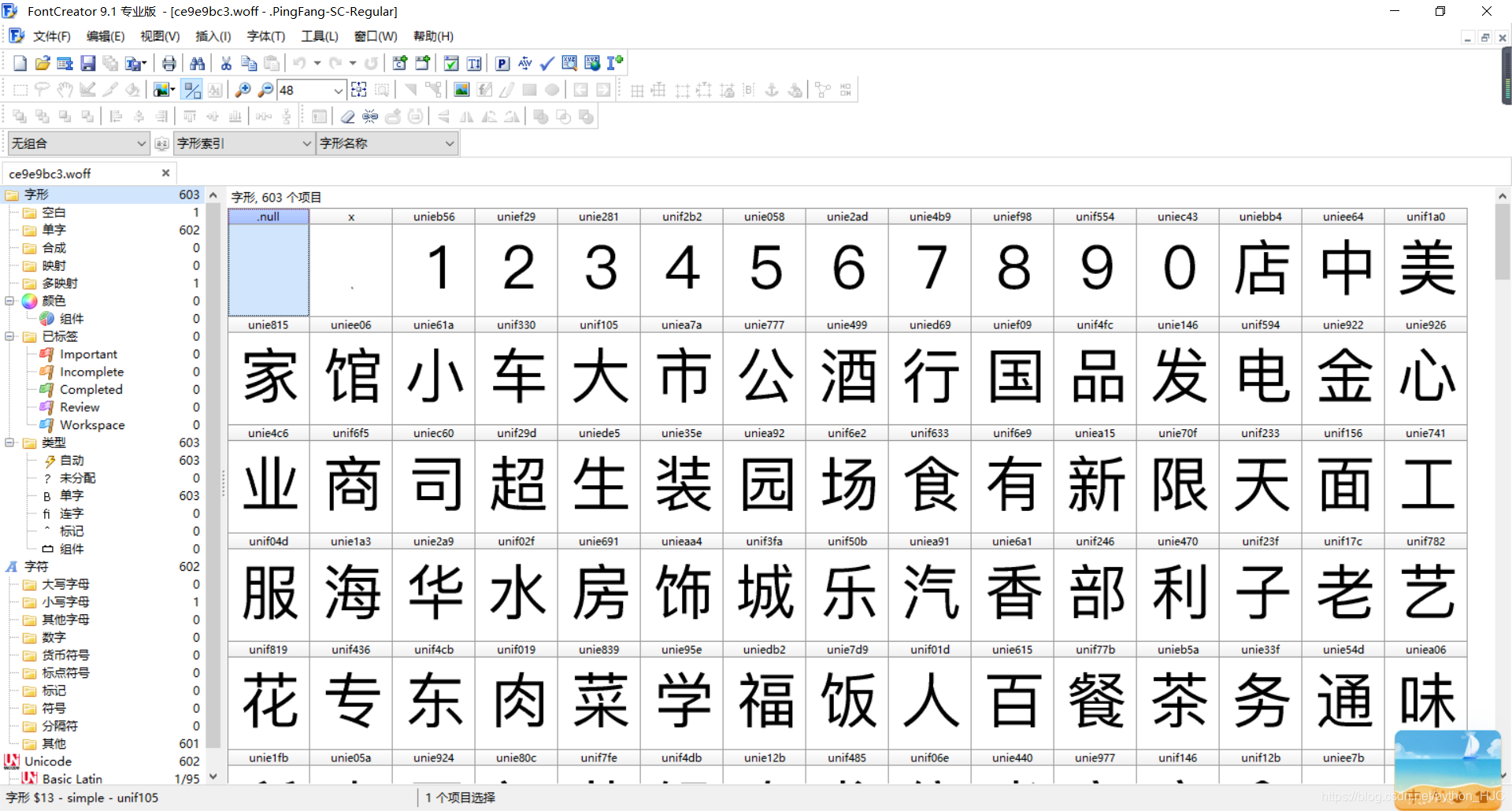
每个编码对应一个字体,例如:unieb56表示1,他渲染在标签中的编码为:�eb56;,所以我们需要得到你想要获取的数据的字体以及和他对应的编码,写入一个字典里面,如:{"�eb56;":“1”};
在爬取页面的时候,获取整个页面,如果字典中这个key在页面中出现就将它替换掉。
上代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4445
4445




 到【灌水乐园】发言
到【灌水乐园】发言







