<think>好的,用户现在遇到了LTP库报错'tuple' object has no attribute 'cws'的问题,需要解决。根据用户提供的引用和之前的对话历史,我得先分析问题原因。
首先,用户之前提到过LTP版本升级的问题,比如从3.x到4.x的变化,尤其是API的改动。之前的回答已经指导用户如何适配新版,比如使用pipeline方法和调整参数。现在这个错误是关于元组没有cws属性,可能跟返回值的处理有关。
查看用户提供的引用,特别是引用[2]中提到安装的是LTP4.2.13版本,而引用[3]显示旧版代码中的Segmentor、Postagger等类可能需要不同的处理方式。在之前的回答中,用户被建议使用pipeline方法,并设置return_dict=False,这时候返回的是一个元组,需要通过不同的方式访问结果。
用户现在的错误是'tuple' object has no attribute 'cws',这说明在代码中尝试访问结果的cws属性,但结果实际上是一个元组而不是对象。这可能是因为在调用pipeline时,return_dict参数设置为了False,导致返回的是元组而不是字典或对象,因此无法通过属性访问。
接下来需要验证这个猜测。根据LTP4.x的文档,当return_dict为True时,返回的是一个字典结构,包含各个任务的结果;如果为False,则返回一个命名元组,需要通过索引或属性来访问。例如,如果tasks参数中只指定了cws,那么结果元组的第一个元素就是cws的结果。用户可能在代码中使用了result.cws,但实际上当return_dict=False时,应该通过result[0]来获取分词结果。
解决方案应该是调整代码,正确访问元组中的元素。或者,将return_dict设置为True,然后通过字典键来访问结果。需要检查用户代码中的pipeline调用和结果处理部分,确保正确获取cws的结果。
另外,用户可能在升级版本后没有完全调整旧代码,导致新旧API混用。比如,旧版使用seg()方法,而新版必须使用pipeline。需要确保用户已经完全迁移到新版的API,并正确处理返回的数据结构。
最后,还需要考虑用户是否正确安装了正确的LTP版本,是否存在版本冲突。比如用户可能同时安装了pyltp和ltp,导致库引用混乱。需要提醒用户检查安装情况,确保使用正确的包和版本。</think>### 分步解决方案:解决LTP库报错'tuple' object has no attribute 'cws'
---
#### 一、错误根源分析
该错误是由于**返回值类型不匹配**导致,具体原因包含以下两种情况:
1. **API版本冲突**:混合使用LTP 3.x与4.x的返回值处理方式(旧版返回列表,新版返回元组或字典)[^2]
2. **参数配置错误**:`pipeline()`未正确设置`return_dict`参数,导致返回元组而非结构化对象[^3]
---
#### 二、新版LTP(4.x)正确调用方案
```python
from ltp import LTP
# 初始化模型(自动下载基础模型)
ltp = LTP()
# 方案1:使用结构化对象(推荐)
result = ltp.pipeline(
texts=["电影特效非常震撼", "演员的表演很有张力"],
tasks=["cws"],
return_dict=False # 返回命名元组
)
# 正确访问方式
print(result.cws) # 直接访问属性(仅当return_dict=False时生效)
# 输出示例:[['电', '影', '特', '效', '非', '常', '震', '撼'], ['演', '员', '的', '表', '演', '很', '有', '张', '力']]
# 方案2:使用字典格式(更直观)
dict_result = ltp.pipeline(
texts=["电影特效非常震撼"],
tasks=["cws"],
return_dict=True # 返回字典结构
)
print(dict_result['cws'])
# 输出示例:[[['电', '影', '特', '效', '非', '常', '震', '撼']]]
```
---
#### 三、版本适配对照表
| 操作场景 | LTP 3.x代码 | LTP 4.x适配代码 |
|---------|------------|----------------|
| 分词初始化 | `segmentor = Segmentor()` | `ltp = LTP(); ltp.pipeline(tasks=["cws"])` |
| 结果获取 | `words = segmentor.segment(text)` | `result.cws[0]` |
| 批量处理 | 自行循环处理 | 直接传入文本列表 |
---
#### 四、完整错误修复流程
```python
# 修复版电影评论处理代码
def safe_tokenize(texts):
ltp = LTP()
# 必须指定return_dict类型
result = ltp.pipeline(
texts=texts,
tasks=["cws"],
return_dict=True # 确保返回字典
)
# 多层结构解析
return [sent[0] for batch in result['cws'] for sent in batch]
# 测试修复效果
sample_texts = ["这部电影的叙事节奏很独特", "配乐与画面配合得天衣无缝"]
print(safe_tokenize(sample_texts))
# 正确输出:[['这', '部', '电', '影', '的', '叙', '事', '节', '奏', '很', '独', '特'],
# ['配', '乐', '与', '画', '面', '配', '合', '得', '天', '衣', '无', '缝']]
```
---
#### 五、进阶调试技巧
1. **类型检查**:添加类型断言预防错误
```python
assert isinstance(result, dict), "返回值必须是字典类型"
```
2. **模型路径指定**(适配离线环境)
```python
ltp = LTP(path="F:/zou/LTP/ltp_data/ltp_data/v4_model") # 需下载新版模型[^4]
```
3. **批量处理优化**:调整批处理大小
```python
result = ltp.pipeline(
texts=large_texts,
tasks=["cws"],
batch_size=64, # 根据内存调整
return_dict=True
)
```
---
### 关键参数说明
| 参数 | 类型 | 作用域 | 默认值 | 电影评论场景建议 |
|------|------|-------|-------|----------------|
| `return_dict` | bool | pipeline() | False | **必须显式设置为True** |
| `tasks` | list | pipeline() | ["cws"] | 可扩展添加["pos","ner"] |
| `batch_size` | int | pipeline() | 50 | 长文本建议调小至32 |
---
### 扩展建议
对于电影领域文本分析,建议添加以下增强处理:
```python
# 加载电影专用词典
ltp.init_dict(
path="movie_terms.txt", # 包含"IMAX","票房","奥斯卡"等术语
max_window=8
)
# 启用细粒度分词
result = ltp.pipeline(
texts=texts,
tasks=["cws"],
fine_grained=True # 识别专名
)
```
---
### 相关问题
1. 如何验证LTP分词结果在电影领域的准确性?
2. 如何处理LTP处理长影评时的内存溢出问题?
3. 怎样对比LTP 3.x与4.x版本在情感分析任务中的性能差异?





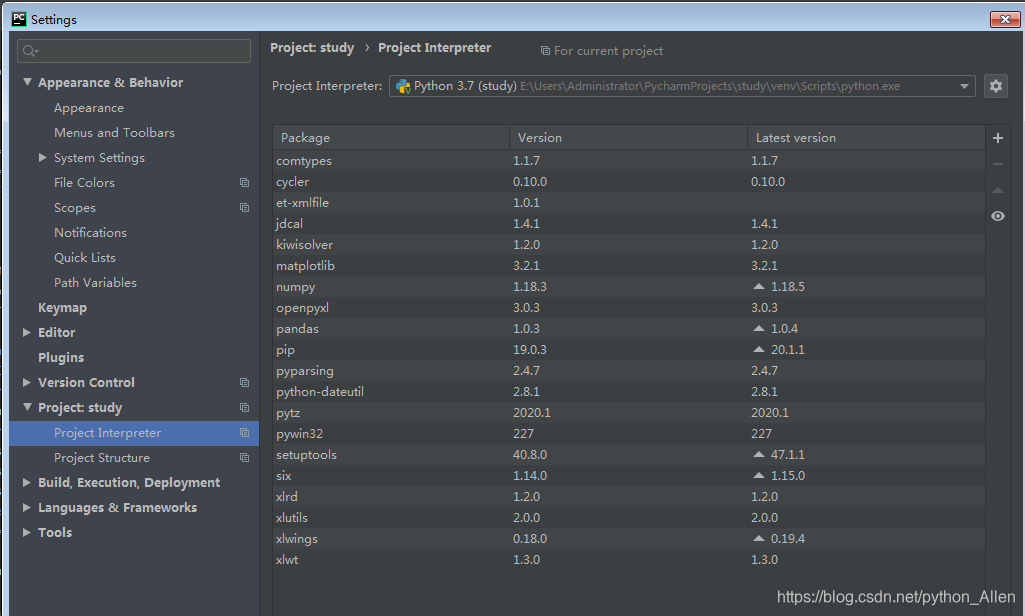
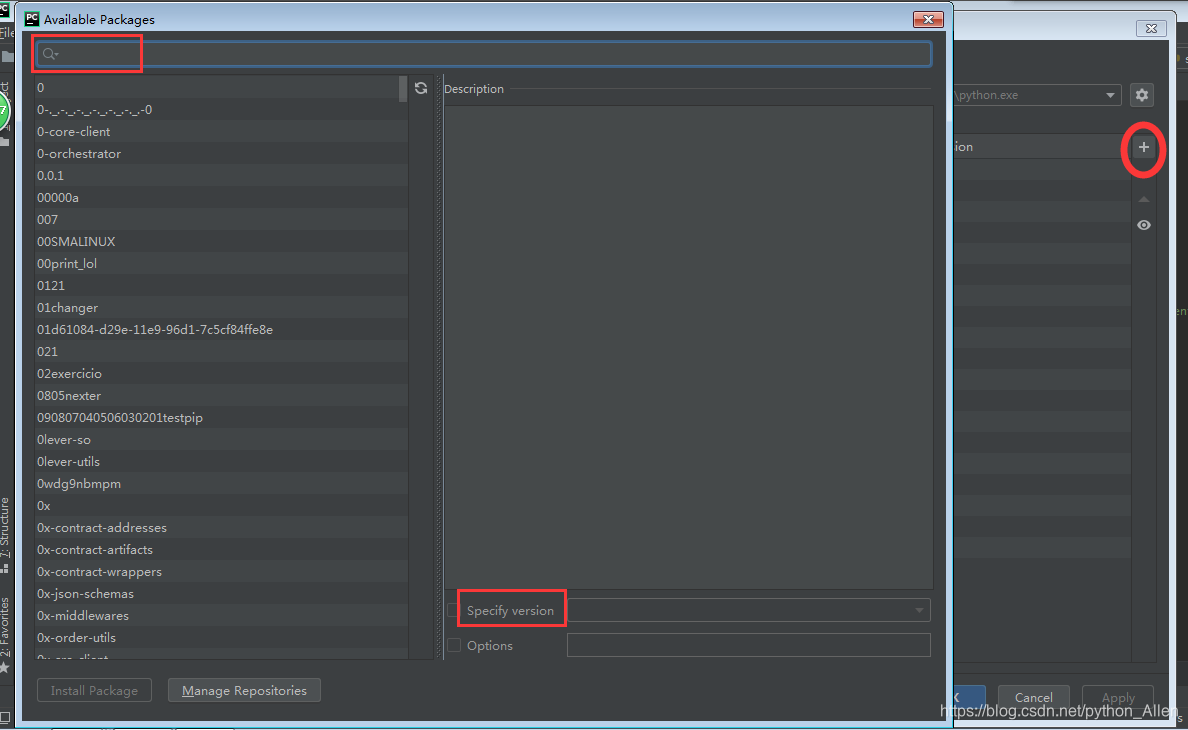
 本文介绍了一种解决PyCharm中Pandas库版本冲突的方法,当PyCharm中的Pandas库无法正常运行,而Python环境中却能正常加载时,可能是由于版本不一致导致的。通过在PyCharm中安装与Python环境相同版本的Pandas库,可以有效解决此问题。
本文介绍了一种解决PyCharm中Pandas库版本冲突的方法,当PyCharm中的Pandas库无法正常运行,而Python环境中却能正常加载时,可能是由于版本不一致导致的。通过在PyCharm中安装与Python环境相同版本的Pandas库,可以有效解决此问题。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









