



 本文介绍了一位初学者如何使用Python爬虫从斗图吧网站抓取大量表情包的过程,包括分析页面结构、编写代码解析HTML以及利用多线程下载图片。通过这个简单的爬虫项目,读者可以了解到网页抓取的基本步骤。
本文介绍了一位初学者如何使用Python爬虫从斗图吧网站抓取大量表情包的过程,包括分析页面结构、编写代码解析HTML以及利用多线程下载图片。通过这个简单的爬虫项目,读者可以了解到网页抓取的基本步骤。
前言
事情要从几天前说起,我有一个朋友,他在和他喜欢的小姐姐聊天时,聊天的气氛一直非常尬,这时他就想发点表情包来缓和一下气氛,但一看自己的表情包收藏都是这样的。。。

。。。这发过去,基本就直接和小姐姐说拜拜了,然后他就向我求救问我有没有表情包,表情包我是没有,但网站有呀,来来,爬虫整起。

分析页面
今天爬取的网站是斗图吧,有一说一表情包是真的多,看这惊人的页数

接下来就该看看怎么拿到表情包图片的url了,首先打开谷歌浏览器,然后点F12进入爬虫快乐模式

然后完成下图的操作,先点击1号箭头,然后再选中一个表情包即可,红色框中就是我们要爬取的对象,其中表情包的src就在里面

现在我们就搞清楚了怎么拿到表情包的url了,就开始写代码了
具体实现
解析页面
获取网页内容
这里就是获取爬取网页的信息
def askURL(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36"
}
req = urllib.request.Request(url=url, headers=head)
html = ""
try:
response = urllib.request.urlopen(req)
html = response.read()
except Exception as result:
print(result)
return html
解析网页内容
# 取出图片src的正则式
imglink = re.compile(
r'<img alt="(.*?)" class="img-responsive lazy image_dta" data-backup=".*?" data-original="(.*?)" referrerpolicy="no-referrer" src=".*?"/>',
re.S)
def getimgsrcs(url):
html = askURL(url)
bs = BeautifulSoup(html, "html.parser")
names = []
srcs = []
# 找到所有的img标签
for item in bs.find_all('img'):
item = str(item)
# 根据上面的正则表达式规则把图片的src以及图片名拿下来
imgsrc = re.findall(imglink, item)
# 这里是因为拿取的img标签可能不是我们想要的,所以匹配正则规则之后可能返回空值,因此判断一下
if (len(imgsrc) != 0):
imgname = ""
if imgsrc[0][0] != '':
imgname = imgsrc[0][0] + '.' + getFileType(imgsrc[0][1])
else:
imgname = getFileName(imgsrc[0][1])
names.append(imgname)
srcs.append(imgsrc[0][1])
return names, srcs
到现在为止,已经拿到了所有的图片的链接和名字,那么就可以开始下载了
文件下载
多线程下载
因为文件实在有点多,所以最好采用多线程的方式下载,我这里只是给了一个样例,大家按照这个逻辑写一下就好
pool = ThreadPoolExecutor(max_workers=50)
for j in range(len(names)):
pool.submit(FileDownload.downloadFile, urls[j], filelocation[j])
成果
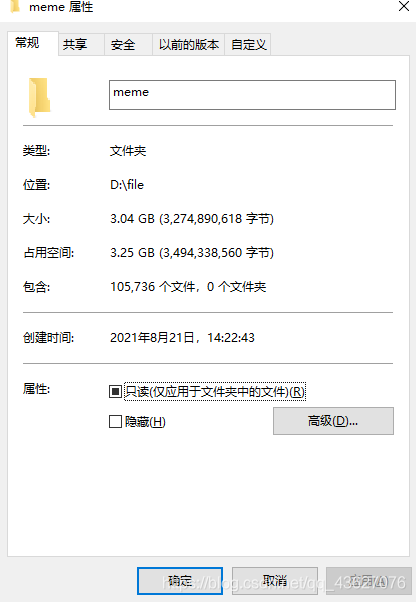

总共是爬了十万多张表情包,这次咱也是表情包大户了

总结
很简单的一个爬虫,适合我这样的初学者练练手,如果对爬虫有兴趣的话可以看看我的爬虫专栏的其他文章,说不定也有你喜欢的

希望大家多多点赞关注哦,更多福利下方领取!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









