






2月19日,Hugging Face 发布了一本关于如何在 GPU 集群上训练大语言模型的《超大规模训练手册》。这本手册耗时 6 个月完成,在多达 512 个 GPU 上进行了超过 4000 次的 scaling 实验。内容涵盖了从基础原理到实际操作的方方面面,对于想要深入了解大模型训练的人来说,这是一份极具价值的参考资料。

这份完整版的【LLM超大规模实战手册】已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
Hugging Face联合创始人兼CEO Clement表示,这份手册的发布旨在推动AI技术的民主化,让不同规模的公司和组织都能训练自己的AI模型。手册涵盖了从单个GPU到数千个GPU的扩展训练方法,详细介绍了显存优化、计算效率提升以及通信开销降低等关键问题。
在训练过程中,手册提出了多种优化技术,如激活值重计算、梯度累积、数据并行、张量并行和流水线并行等。这些技术通过在计算、通信和显存之间寻找平衡,显著提升了训练效率。例如,激活值重计算通过丢弃部分激活值并动态重新计算,减少了显存占用;而流水线并行则通过将模型分层部署在不同的GPU上,进一步降低了单个GPU的内存压力。
此外,手册还介绍了DeepSpeed的ZeRO优化技术,通过分区优化器状态、梯度和参数,减少了内存冗余。同时,针对长序列和大模型的挑战,手册提出了上下文并行和环形注意力机制等创新方法,进一步优化了训练过程。
Hugging Face的这一举措不仅为开发者提供了宝贵的实战经验,也推动了AI技术的普及和应用。Clement表示,未来的AI世界应该是去中心化的,让全球更多人能够参与到AI的开发和应用中。这份手册的发布,正是朝着这一目标迈出的重要一步。
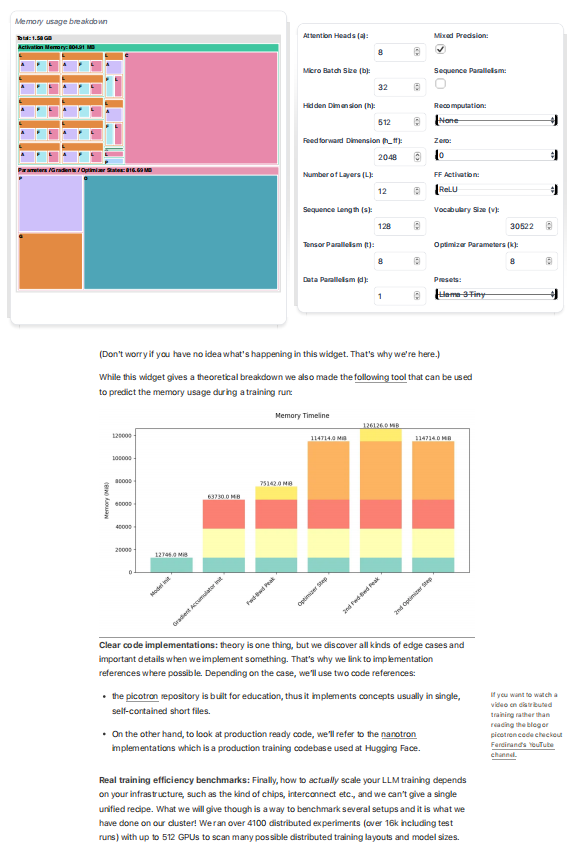
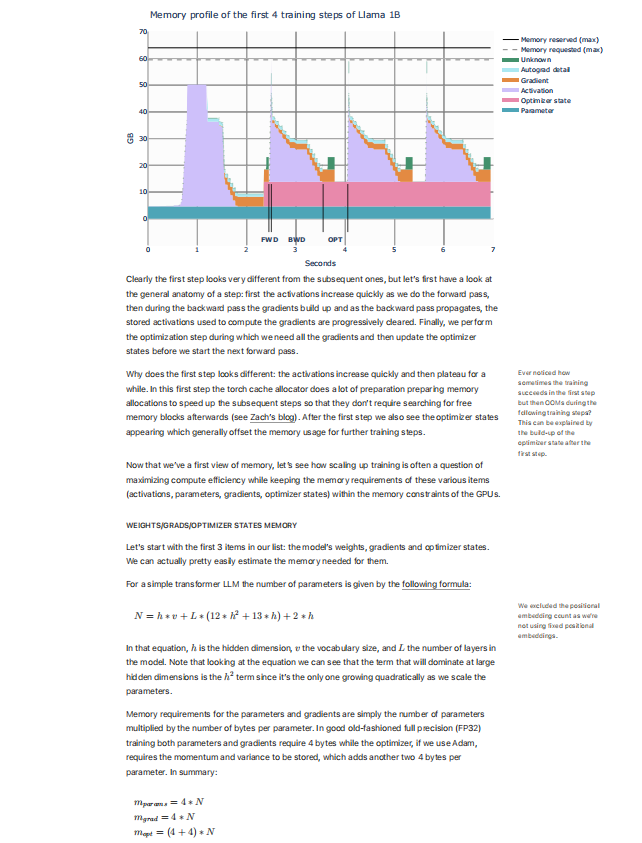
下面展示一下该手册一部分



这份完整版的【LLM超大规模实战手册】已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









