



不同方法的全面概述

检索增强生成(RAG)系统和多模态大型语言模型(LLMs)正在迅速发展,应用范围从增强搜索体验到生成复杂内容。这些方法不断被改进,以扩展人工智能的能力边界。但是,如果你可以结合它们的优势,构建一个不仅处理文本,还能无缝处理图像的RAG系统呢?
现在想象一下,进一步发展这个系统,而不依赖于像LangChain或LlamaIndex这样的预构建框架?
无框架的方法使你拥有完全的控制权,让你可以根据自己的确切需求量身定制应用,而不受外部依赖或版本限制的约束。
在这篇博客中,我们将带你深入了解这个过程。从比较文本和图像提取工具,到从零开始构建一个强大的多模态RAG系统,我们将逐步引导你,帮助你创建自己的定制解决方案。
本教程的完整代码可在以下Colab笔记本中找到(文章中的代码格式可能会出现问题):
Colab Notebook: Multimodal RAG Implementation
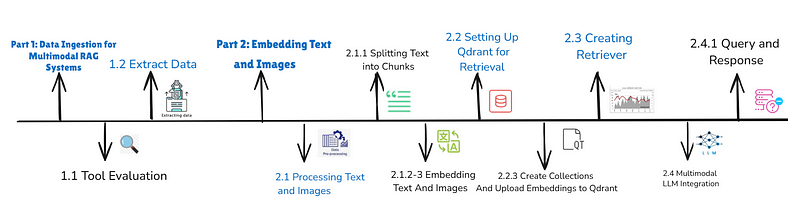
Part 1: 数据摄取用于多模态RAG系统
任何RAG系统的基础是可靠的数据。为了使系统能够检索和生成准确的结果,它处理的内容需要干净、完整且结构良好。处理PDF时,这意味着不仅要提取文本,还要提取图像和表格,确保没有有价值的信息丢失。
选择合适的PDF处理工具至关重要。由于可用的库众多,决定哪个最适合您的需求可能会让人感到不知所措。有些优先考虑速度,有些则注重准确性,还有一些在两者之间提供平衡。为了帮助您做出明智的决策,我们评估了三个流行的库:PyMuPDF、PDFium和PDFPlumber。
在 RAG 系统中选择合适的 PDF 处理工具
PDFPlumber:
pdfplumber 可以从 PDF 中提取相当准确的文本和表格。然而,它有一个显著的缺点:对于复杂的 PDF 文件,它可能会非常耗时。例如,从一个 100 页的 PDF 中提取内容可能需要 1 分钟和 10-30 秒。这是一个相当大的延迟,特别是在处理多个 PDF 时。
Code Example:
!pip install pdfplumber
import pdfplumber
import time
defread_text_pdfplumber(pdf_path):
""" Extracts text and tables from pdf using pdfplumber """
text_results=[]
tables=[]
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
# Text extraction
text = page.extract_text()
text_results.append(text)
# Table extraction
table = page.extract_tables()
tables.append(table)
return(text_results,tables)
对于一个 622 页的 PDF,该脚本花费了 152.35 秒 来提取文本和表格。
PDFium:
pdfium 是一个快速的库,可以在 5–15 秒内将 PDF 内容转换为文本。由于其将 PDF 页面转换为图像并从中提取文本的方法,文本提取相当准确。这使得它成为快速文本提取的绝佳选择。然而,它有一个限制:它并不明确支持将图像或表格与文本分开。
Code Example:
!pip install pypdfium2
import pypdfium2 as pdfium
defread_text_pdfium(path):
""" Extracts text from pdf using pdfium """
pdf = pdfium.PdfDocument(path)
version = pdf.get_version() # get the PDF standard version
n_pages = len(pdf)
pdfium_text=""
for i inrange(len(pdf)):
page = pdf[i] # load a page
width, height = page.get_size()
textpage = page.get_textpage()
text_part = textpage.get_text_bounded(left=50, bottom=100, right=width, top=height)
pdfium_text+=text_part
return pdfium_text
对于一个 622-页的 PDF,该脚本花费 5–10 秒 提取文本。
PyMuPDF
如果您正在寻找从PDF中提取内容的最佳工具之一,PyMuPDF无疑是一个不错的选择。它非常快速,处理一个PDF仅需4到7秒。它不仅可以提取文本,还能处理图像,使其成为一个全面的选项。如果您需要在多个PDF中获得快速且可靠的结果,PyMuPDF绝对值得考虑。
代码示例:
!pip install pymupdf
import fitz # PyMuPDF library
def read_text_pymupdf(path):
"""Extracts text from a PDF using PyMuPDF."""
doc = fitz.open(path)
text_results = []
for page in doc:
text = page.get_text()
text_results.append(text)
return text_results
在这里,我将使用PyMuPDF从PDF中提取图像。这些图像将保存在输出目录中。
代码示例:
import fitz # PyMuPDF
import os
defextract_images_from_pdf(pdf_path, output_folder):
""" Extract images from pdf using PyMuPDF """
pdf_document = fitz.open(pdf_path)
os.makedirs(output_folder, exist_ok=True)
for page_number inrange(len(pdf_document)):
page = pdf_document[page_number]
images = page.get_images(full=True)
for image_index, img inenumerate(images):
xref = img[0]
base_image = pdf_document.extract_image(xref)
image_bytes = base_image["image"]
image_ext = base_image["ext"]
image_filename = f"page_{page_number+1}_image_{image_index+1}.{image_ext}"
image_path = os.path.join(output_folder, image_filename)
withopen(image_path, "wb") as image_file:
image_file.write(image_bytes)
print(f"Saved: {image_path}")
pdf_document.close()
对于一个622页的PDF,PyMuPDF仅用5到6秒就提取了文本,提供了相对于其他库的显著性能优势。这种效率使其成为处理大型或多个PDF的绝佳选择。然而,理想的库取决于您的具体用例和需求。
PDF库的处理时间比较
下表比较了使用三种库(PDFium、PyMuPDF和PDFPlumber)处理不同页数的PDF所需的时间。
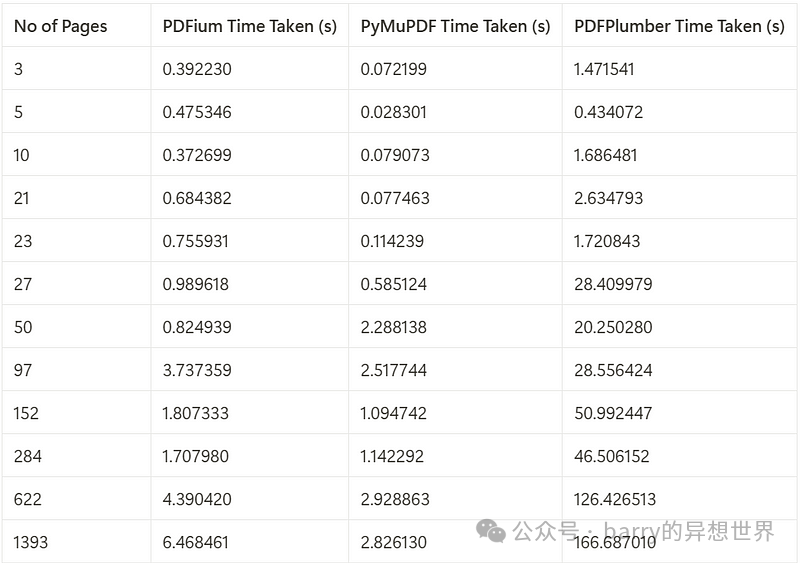
根据性能分析,PyMuPDF的性能始终优于PDFium和PDFPlumber,对于处理页数超过1,000的PDF,速度比PDFium快2.3倍,比PDFPlumber快59倍。
主要要点
- • PyMuPDF 是最快的,非常适合大规模或时间敏感的任务。
- • PDFium 在速度和准确性之间提供了平衡,但缺乏图像提取功能。
- • PDFPlumber 较慢,但在从复杂PDF中提取详细表格方面表现出色。
库性能比较

如果您想了解更多关于PDF基准测试的信息,请查看这个仓库:
https://github.com/py-pdf/benchmarks?tab=readme-ov-file
第二部分:嵌入文本和图像
现在我们已经处理了PDF内容,下一步是构建一个多模态RAG系统。这涉及将提取的文本和图像集成到一个检索增强的管道中。
对于内容提取,我将使用PyMuPDF,因为它具有卓越的速度和处理文本与图像的能力。为了构建多模态检索器,我将利用QdrantDB作为向量存储。
处理和嵌入文本和图像
文本内容被拆分为更小、可管理的块,以优化嵌入性能和检索准确性。在这里,我们使用 LangChain 的 RecursiveCharacterTextSplitter,因为它简单且可配置。然而,拆分文本可以通过多种方式完成,例如编写自定义拆分器或利用 NLTK 或 spaCy 等库。
在这个例子中,我们为每个块添加元数据,包括 PDF 路径和唯一的 UUID。元数据有助于在检索过程中保持上下文。
安装依赖:
#for colab to load openai client
%%capture
!pip install openai==1.55.3 httpx==0.27.2 --force-reinstall --quiet
!pip install transformers torch pillow
!pip install --upgrade nltk
!pip install sentence-transformers
!pip install --upgrade qdrant-client fastembed Pillow
!pip install -U langchain-community
将文本拆分为块
我们将为每个块添加相关的元数据,元数据可以是任何东西,可以帮助检索块。但在这里,我只是将 pdf 路径和唯一的 uuid 作为文本的元数据添加。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1024,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
#here text_results contain all text from pdf
doc_texts = text_splitter.create_documents(text_results)
import uuid
for i inrange(len(doc_texts)):
unique_id = str(uuid.uuid4())
doc_texts[i].metadata['document_info'] = pdf_path
doc_texts[i].metadata['uuid'] = unique_id
print(doc_texts[0].metadata)
嵌入文本块
一旦分割,文本块将使用 Nomic text embedding model 进行嵌入。这将每个块转换为适合存储在检索器中的向量表示。
from transformers import AutoTokenizer, AutoModel
### Load the tokenizer and model
text_tokenizer = AutoTokenizer.from_pretrained("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
text_model = AutoModel.from_pretrained("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
defget_text_embeddings(text):
inputs = text_tokenizer(text, return_tensors="pt", padding=True, truncation=True)
outputs = text_model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings[0].detach().numpy()
### Example usage
text = "This is a test sentence."
embeddings = get_text_embeddings(text)
print(embeddings[:5])
#embedding text
texts_embeded = [get_text_embeddings(document.page_content) for document in doc_texts]
text_embeddings_size=len(texts_embeded[0])
text_embeddings_size
#output: 768
嵌入图像
图像从指定目录读取,并使用 Nomic Vision embedding model 嵌入。last_hidden_state 输出的均值用于将每个图像表示为固定长度的向量。
这是加载模型和测试图像的示例代码:
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
model = AutoModel.from_pretrained("nomic-ai/nomic-embed-vision-v1.5", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("nomic-ai/nomic-embed-vision-v1.5")
### Load the image
#testing an image on loaded model
image = Image.open("/content/drive/MyDrive/images/Screenshot 2024-09-08 025257.png")
inputs = processor(images=image, return_tensors="pt")
model.eval()
#testing model
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
print(embeddings)
对于我们的多模态 RAG,图像将通过使用 PIL 从目录中读取,然后使用加载的视觉模型进行嵌入,使用以下代码。
import os
import numpy as np
image_embeddings = []
image_files = os.listdir(output_directory)
for img in image_files:
try:
image = Image.open(os.path.join(output_directory, img))
inputs = processor(images=image, return_tensors="pt")
model.eval()
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
print(f"Image: {img}, Embedding shape: {embeddings.shape}")
if embeddings.size(0) > 0:
image_embedding = embeddings.mean(dim=1).squeeze().cpu().numpy()
image_embeddings.append(image_embedding)
else:
print(f"Skipping image {img} due to empty embeddings.")
except Exception as e:
print(f"Error processing {img}: {e}")
#setting image embedding model length:
image_embeddings_size=len(image_embeddings[0])
关键注意事项:
- • 工具的灵活性:虽然这里使用了 Nomic 模型,但可以替换为 Sentence Transformers 或自定义模型以满足特定需求。
- • 元数据的重要性:添加相关的元数据,如唯一标识符,可以确保可追溯性并提高检索准确性。
在文本和图像嵌入准备就绪后,下一步是将它们整合到统一的检索管道中。这将使系统能够在不同模态之间无缝地检索和生成响应。
设置 Qdrant 以进行多模态检索
在文本和图像嵌入准备就绪后,下一步是初始化 Qdrant client 并将其配置为多模态检索。Qdrant 作为向量数据库,允许在文本和图像嵌入之间进行高效的相似性搜索。
初始化 Qdrant 客户端
在这里,我们使用 Qdrant 的内存配置进行测试。对于生产环境,请将 :memory: 替换为持久数据库路径,以确保可扩展性。
from qdrant_client import QdrantClient, models
client = QdrantClient(":memory:")
为文本和图像创建单独的集合
我们创建两个单独的集合:一个用于文本,另一个用于图像。每个集合都根据所使用的嵌入模型配置了向量参数(size 和 distance)。
### Check if the collection exists, and create it if not
ifnot client.collection_exists("images"): #creating a Collection
client.create_collection(
collection_name="images",
vectors_config=models.VectorParams(
size=image_embeddings_size, # Vector size is defined by model being used for embedding
distance=models.Distance.COSINE,
),
)
ifnot client.collection_exists("text"):
client.create_collection(
collection_name ="text",
vectors_config=models.VectorParams(
size=text_embeddings_size, # Vector size is defined by model being used for embedding
distance=models.Distance.COSINE,
),
)
将嵌入上传到 Qdrant
在创建集合后,我们用嵌入和元数据填充它们。元数据确保在检索过程中保持上下文和可追溯性。
上传文本嵌入
我们通过上传文本嵌入及其相关元数据(例如内容和唯一标识符)来填充文本集合。
client.upload_points(
collection_name="text",
points=[
models.PointStruct(
id=doc.metadata['uuid'],
vector=np.array(texts_embeded[idx]),
payload={ #save meta data and content as payload
"metadata": doc.metadata,
"content": doc.page_content
}
)
for idx, doc in enumerate(doc_texts)
]
)
上传图像嵌入
对于图像,每个嵌入都与其对应的图像路径在负载元数据中关联。我们存储图像路径,以便在多模态 LLM 检索时重新加载图像。这种有组织的方法允许在集合中高效搜索图像。
#for image embeddings
### Ensure that image_embeddings are not empty
iflen(image_embeddings) > 0:
# Upload points to Qdrant
client.upload_points(
collection_name="images",
points=[
models.PointStruct(
id=str(uuid.uuid4()), # unique id of a point
vector= np.array(image_embeddings[idx]) ,
payload={"image_path": output_directory+'/'+str(image_files[idx])} # Image path as metadata
)
for idx inrange(len(image_files))
)
else:
print("No valid embeddings found, nothing to upload.")
第 3 部分:创建检索器
最后,我们通过设置多模态检索器将所有内容整合在一起,使我们能够检索与用户查询匹配的文本块和图像。检索器配置为根据相似性得分从每个集合中返回前 3 个结果,文本和图像。
为什么要分开集合?
文本和图像嵌入在不同的特征空间中操作,它们的相似性得分不可直接比较。通过分开集合并运行独立查询,我们确保文本和图像结果都能以适当的权重和相关性被检索。这样可以避免某一种模态(例如,文本)因更高的相似性得分而主导结果,从而掩盖另一种模态的相关结果。
使用独立集合确保:
- • 文本块是根据与查询的语义相似性进行检索的。
- • 图像是根据其视觉相似性进行检索的,与文本得分无关。
这种分离对于多模态系统至关重要,因为这两种模态在满足用户意图方面同样重要。
检索器函数
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
defMultiModalRetriever(user_query):
"""
检索多模态结果(文本和图像)。
参数:
- user_query: 用户的查询字符串。
"""
query = get_text_embeddings(user_query)
# 检索文本结果
text_hits = client.query_points(
collection_name="text",
query=query,
limit=3, #根据需求设置自己的限制
).points
# 检索图像结果
Image_hits = client.query_points(
collection_name="images",
query=query,
limit=3, #根据需求设置自己的限制
).points
return text_hits, Image_hits
现在构建一个查看器以显示检索结果:
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#text_trunc_length: 显示文本结果时的最大字符数,超过部分将被截断。
defMultiModalRetrieverDisplay(text_hits,Image_hits, text_trunc_length=150):
"""
显示来自多模态检索器的文本和图像结果。
参数:
----------
text_hits :包含 `id`、`payload` 和 `score` 的文本结果列表。
Image_hits :包含 `id`、`payload` 和 `score` 的图像结果列表。
text_trunc_length : int, 显示文本内容的最大长度(默认值为150)。
显示:
--------
- 以粗体显示文本结果,包含 ID、截断内容和分数。
- 在 matplotlib 图中显示图像结果,标题中包含分数。
"""
print("\\033[1m文本结果:\\033[0m")
for i, hit inenumerate(text_hits, 1):
print("NODEID:",hit.id)
content = hit.payload['content']
truncated_content = content[:text_trunc_length] + "..."iflen(content) > text_trunc_length else content
bold_truncated_content = f"\\033[1m{truncated_content}"
print(f"{i}. {bold_truncated_content} | 分数: {hit.score}")
print("\\n图像结果:")
fig, axes = plt.subplots(1, len(Image_hits), figsize=(15, 5)) # 根据需要调整 figsize
for ax, hit inzip(axes, Image_hits):
image_path = hit.payload['image_path']
print(f"显示图像: {image_path} | 分数: {hit.score}")
img = mpimg.imread(image_path)
ax.imshow(img)
ax.axis('off')
ax.set_title(f"分数: {hit.score}", fontsize=10)
plt.suptitle("图像结果", fontsize=16)
plt.tight_layout()
plt.show()
测试多模态检索器和查看器功能
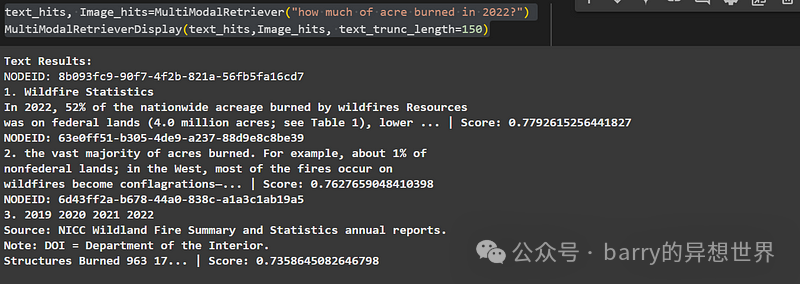
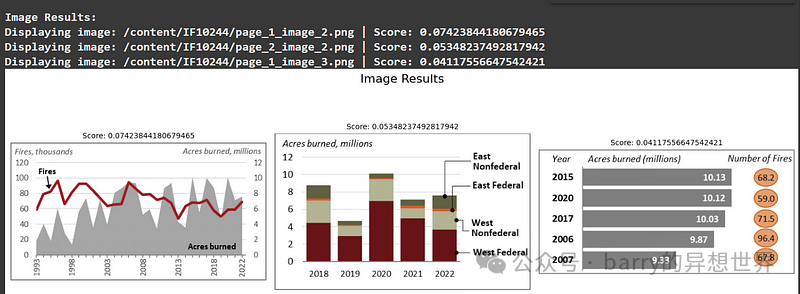
text_hits, Image_hits=MultiModalRetriever("how much of acre burned in 2022?")
MultiModalRetrieverDisplay(text_hits,Image_hits, text_trunc_length=150)
RAG Pipeline with Multimodal LLM Integration
要构建一个 MultiModal RAG 系统管道,您可以集成任何多模态 LLM 来处理文本和图像。以下是工作原理:
- \1. 准备数据:将文本块(上下文列表)和图像分离成其文件路径的列表。
- \2. 处理图像:将图像文件路径转换为编码的图像数据。这些编码的图像将根据模型的要求以 URL 或编码对象的形式传递给模型。
- \3. 输入模型:将文本块和编码的图像组合成单一的输入格式。多模态 LLM 将使用文本块作为上下文,图像作为视觉数据来生成答案。
这种方法使模型能够无缝处理文本和视觉信息,提供全面而准确的响应。
构建 RAG 功能:
from openai import ChatCompletion
import openai
import base64
from base64 import b64decode
import os
defMultiModalRAG(
context: list,
images: list,
user_query: str,
client: client,
model: str = "yourMLLM"): # 您使用的多模态 LLM 的名称
generation_prompt = f"""
根据给定的上下文,回答用户查询:{user_query},
上下文可以是表格、文本或图像。从上下文中提供答案。
用户查询:{user_query}
上下文:{context}\\n
输出:
"""
# 辅助函数将图像编码为 base64 字符串
defencode_image(image_path):
if image_path:
withopen(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode()
returnNone
image_paths = images
messages = [
{
"role": "system",
"content": "您是一个乐于助人的助手。"
},
{
"role": "user",
"content": generation_prompt,
}
]
# 编码图像并在存在时将其添加到消息中
for image_path in image_paths:
img_base64 = encode_image(image_path)
if img_base64:
# 将图像的 base64 字符串作为文本内容的一部分添加
messages.append({
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{img_base64}"# 发送 base64 编码的图像
},
},
],
})
# 创建聊天完成
chat_completion = client.chat.completions.create(
messages=messages,
model=model,
temperature=0.5,
top_p=0.99,
)
return chat_completion.choices[0].message.content
我们的多模态 RAG 功能接受图像路径作为输入,打开并编码图像,然后将其传递给多模态 LLM 以回答用户查询。这些图像路径存储在有效负载中,如图像嵌入收集步骤中所讨论的。当检索器获取图像嵌入时,我们使用它们的有效负载来获取多模态 LLM 的图像路径。
def RAG(query):
text_hits, Image_hits=MultiModalRetriever(query)
retrieved_images=[i.payload['image_path'] for i in Image_hits]
answer=MultiModalRAG(text_hits,retrieved_images,query,openaiclient)
return(answer)
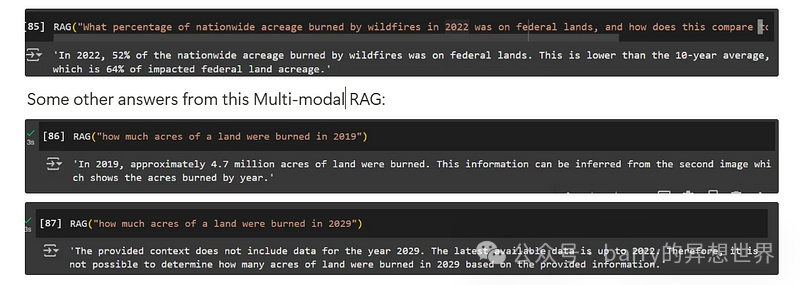
RAG("""2022 年全国因野火烧毁的土地面积中,有多少百分比是在联邦土地上,这与 10 年平均水平相比如何?""")
第4部分:结论:让多模态数据为您服务。
构建一个多模态RAG系统的关键在于将复杂、多样的数据转化为真正有用的东西。从使用像PyMuPDF这样的工具提取内容,到使用像Nomic Vision和Text这样的模型嵌入文本和图像,再到在Qdrant中组织所有内容,每一步都朝着一个无缝工作的系统迈进。最终添加一个多模态LLM将所有内容整合在一起,使系统能够提供不仅准确而且上下文丰富、全面的答案。
所述过程演示了如何:
- • 提取多模态数据。
- • 在Qdrant中嵌入和存储数据。
- • 为基于多模态LLM的处理检索数据。
这个过程展示了AI如何弥合不同类型的数据、文本和视觉之间的差距,以解决现实世界中的问题。通过正确的方法,RAG系统不仅仅是一个工具;它成为获取有意义见解和做出更明智决策的方式。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 4892
4892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









