 PyTorch训练模型及AI大模型学习资料分享
PyTorch训练模型及AI大模型学习资料分享




机器学习和深度学习的本质是从历史数据中发现一般模式,然后用发现的模式预测未来的数据。在本文中,我们将以一个学习直线方程的例子说明用 PyTorch 训练模型的工作流程。

我们将学习以下几个步骤:

准备和加载数据
机器学习中的数据含义很广泛:文本、图像、视频、音频、表格、甚至是蛋白质结构都是数据。

现在我来创建一个线性回归数据集:

我们的目的就是建立一个模型去寻找 X 和 y 之间的关系。
机器学习最重要的一步是将你的数据集分成训练集、验证集(有时不需要)和测试集。
- 训练集:占原始数据集的 60% ~ 80%,模型从训练集中学习一般模式。
- 验证集:占原始数据集的 10% ~ 20%,我们可以利用验证集调整模型超参数。
- 测试集:占原始数据集的 10% ~ 20%,模型训练完之后,最终测试模型的性能。
这里,我们仅将数据集分为训练集和测试集。在实际工作中,数据集在项目开始之前就被分好了,我们可以多次使用训练集,但是只能在最终训练完后,使用一次测试集测试模型的最终泛化性能。

现在我们得到了含有40个样本的训练集和含有10个样本的测试集。我们将从训练集中学习模式,并用测试集验证学习到的模式。
我们可视化一下数据集,好让你知道我们到底要干什么:


我们的目的就是要找出 X 和 y 之间的线性关系:w 和 b。
建立模型
现在我们要建立一个可以根据上图中的蓝色点预测绿色点的模型。
首先,用纯 PyTorch 来表示线性回归:

PyTorch 基础模块
我们首先看一下一些 PyTorch 基础模块,它们几乎都来自 torch.nn 模块:
- torch.nn:包含计算图(本质上是以特定方式执行的一系列计算)的所有构建模块。
- torch.nn.Parameter:存储可与 nn.Module 一起使用的张量参数。如果requires_grad=True (用于通过梯度下降方法更新模型参数)则自动计算梯度,这通常被称为 autograd。
- torch.nn.Module:所有神经网络模块的基类,神经网络的所有构建模块都是它的子类。如果你在 PyTorch 中构建神经网络,你的模型应该是 nn.Module 的子类。但是子类需要实现 forward() 方法。
- torch.optim:包含各种优化算法(这些算法告诉存储在 nn.Parameter 中的模型参数如何最好地改变以减少损失)。
- forward() 方法:所有 nn.Module 子类都需要一个 forward() 方法,这定义了对传递给特定 nn.Module 的数据进行的计算(例如上面的线性回归公式)。
torch.nn 中的 nn 是神经网络(neural network)的缩写。

通过子类化 nn.Module 创建 PyTorch 模型的基本构建模块。对于 nn.Module 子类的对象,必须定义 forward() 方法。
查看 PyTorch 模型的内容
我们首先需要创建一个模型实例,然后调用 .parameters() 方法查看模型参数:

我们也可以查看模型当前的状态:

由于我们使用了 torch.randn 初始化参数了,所以现在 weights 和 bias 都是随机张量。
使用 torch.inference_mode() 进行预测
我们将测试集 X_test 的数据通过 forward() 方法得到模型的预测结果 y_preds:

在旧版本的 PyTorch 中,我们使用的是 torch.no_grad()。无论是哪种,我们都抑制了 PyTorch 自动计算梯度的功能,这有助于加速 forward 流程。
由于我们模型参数都是随机初始化的,而且模型又没有经过训练,所以现在模型的预测性能显然很糟糕:


训练模型
训练模型的过程其实就是不断更新我们之前由 torch.randn 和 nn.Parameter 初始化的模型参数 weights 和 bias。
在 PyTorch 中创建损失函数和优化器
损失函数(loss function) 负责衡量模型的预测值(y_preds)和真实值(y_tests)之间的差异,通常越小越好。torch.nn 模块内置了很多损失函数。一般对于回归任务,使用平均绝对误差(torch.nn.L1Loss());对于二分类任务,使用二元交叉熵损失(torch.nn.BCELoss())。
优化器(optimizer) 负责告诉模型如何调整内部参数以最小化损失函数。torch.optim 模块实现了许多优化函数。常见的优化函数有随机梯度下降(torch.optim.SGD())和 Adam(torch.optim.Adam())。
我们需要根据不同的任务选择合适的损失函数和优化器。由于我们现在是在预测数值,所以我们选择 torch.nn.L1Loss()。

平均绝对误差(torch.nn.L1Loss)测量两点(预测和标签)之间的绝对差,
然后取所有样本的平均值。
我们将选择 torch.optim.SGD(params, lr):
- params 就是我们要更新的模型参数,在这里就是 weights 和 bias。
- lr 是学习率(learning rate)的缩写。它表示参数更新的幅度,lr 越大,则参数更新幅度越大,越可能错过最佳值;lr 越小,则参数更新幅度越小,模型训练速度就越慢。lr 也称为超参数(hyperparameter),选择合适的 lr 值是一名学问,具体可以去查阅官方文档:
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate

创建训练循环
现在我们可以创建训练循环(training loop)和测试循环(testing loop)。
模型在**训练循环(training loop)**中遍历训练集中的样本,学习样本的特征和标签之间的关系。

典型的训练循环如上图所示,首先我们需要设定模型训练的循环次数 epochs。然后在每个 epoch(也就是每次循环中):
- 通过模型的 forward() 方法计算模型对于训练集的预测 y_pred。
- 根据损失函数计算模型预测值 y_pred 和真实值 y_true 之间的损失 loss。
- 清零优化器的梯度,否则梯度会在每次循环中累积。
- 利用反向传播算法计算损失相对于模型参数的梯度:loss.backward()。
- 使用随机梯度下降算法用梯度更新模型参数:optimizer.step()。
模型在 测试循环(testing loop) 中遍历测试集中的样本,衡量模型学习到关系在未知数据集中的表现。

测试循环就简单了,还是在每个 epoch(也就是每次循环中):
-
通过 model.eval() 说明现在是在评估状态。
-
在 torch.inference_mode() 中:
-
- 利用 forward() 方法计算模型在测试集上预测 test_pred。
- 计算 test_pred 和真实值 y_test 之间的损失:test_loss。
-
隔几个 epoch(一般是10)输出一下平均损失。
我们现在训练100个 epoch:

然后我们看一下损失曲线随 epoch 的变化趋势:

我们可以看到训练损失和测试损失都在不断减小,这说明模型是“学”到了一些东西的。我们看一下模型学到的参数值和真实参数值差异:

已经相当接近了。
如果我们加大训练次数,可能会更接近。
用训练好的模型进行预测
模型训练好之后就可以用来预测了,有的地方也称为推理(inference)。但是在此之前,我们需要做好以下三件事:
- 设置评估模式:model.eval()。
- 在 with torch.inference_mode(): … 上下文管理器中进行预测。
- 模型和数据必须要在同一个设备上。

我们再次将模型预测值和真实值绘制在图上:

看起来结果已经是相当接近了。
保存和加载 PyTorch 模型
有三种主要的方法可以保存和加载 PyTorch 模型:
- torch.save:使用 Python 的 pickle 工具将对象序列化后保存到磁盘。模型、张量和其他 Python 对象都可以用这种方法保存。
- torch.load:将 torch.save 保存的文件反序列化之后加载到内存,我们还可以选择加载到 GPU 还是 CPU。
- torch.nn.Module.load_state_dict:加载保存在磁盘上的模型参数字典(用 model.state_dict() 方法可以获得)。
不过根据 pickle 的官方文档介绍,pickle 是不安全的,所以你必须要相信你要加载的对象是安全的。
保存和加载模型的推荐方式是通过模型的 state_dict() 方法。
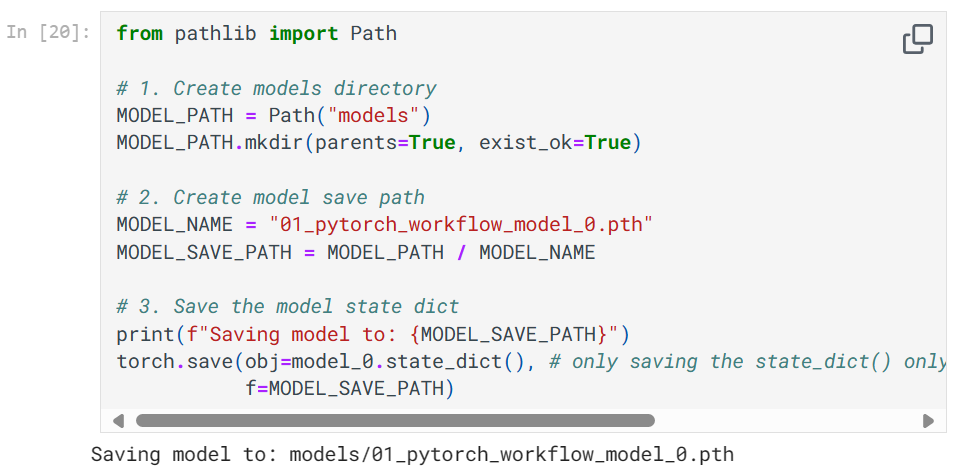
torch.save 的 obj 参数是模型的参数字典、f 参数是保存的路径。一般我们将 PyTorch 模型保存为以 .pt 或 .pth 这样的后缀。
不过以这种方式保存的模型仅仅是保存了模型训练之后的参数字典,而不是整个模型。所以我们首先需要初始化一个模型实例,然后用保存在磁盘上的模型参数字典更新这个初始化的模型参数:

看到上面的提示说明加载成功。
加载成功之后,我们再次用这个新加载的模型做预测:

并将预测结果和之前训练的模型进行比较:

结果显然是一致的。
根据官方文档,保存整个模型的缺点是序列化数据绑定到特定的类以及保存模型时使用的确切目录结构。这样做的原因是因为 pickle 不保存模型类本身。相反,它保存包含该类的文件的路径,该路径在加载时使用。因此,在其他项目中使用或重构后,您的代码可能会以各种方式损坏。
更多的保存和加载模型的资料可以去官方文档查询:
https://pytorch.org/tutorials/beginner/saving_loading_models.html
将前面所有的步骤放在一起
首先确定当前可用的设备:

然后我们创建数据集:y = weights * x + bias

接着按照80/20的比例将数据集切分成训练集和测试集,并可视化:


现在我们建立模型,但是这次我们使用 torch.nn.Linear(in_features, out_features) 建立模型。

in_features 表示输入的张量维度,out_features 表示输出的张量维度,在我们这个数据集中都是1。

可以看到代码简洁很多,而且参数也是随机初始化的。
默认情况下,模型是在 CPU 上的:

将模型移动到当前可用的设备上:

定义损失函数和优化器:

训练循环,这里我们还将数据移动到模型所在设备上:

当我们将训练 epochs 从100增加到1000之后,模型学到的参数很逼近真实参数值了:

现在使用模型对测试集进行预测,不过由于现在测试集和模型都在 GPU 上,所以预测结果也在 GPU 上:

但是我们要想可视化的话,还得首先将数据移动到 CPU 上:

现在红色点几乎和蓝色点重叠了,非常好!
保存模型:

加载模型:

使用加载后的模型预测:

如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









