 基于Dify的企业级大模型落地实践
基于Dify的企业级大模型落地实践




本文详细介绍了基于Dify平台实现企业级大模型应用落地的完整方案,重点讲解了RAG架构解决大模型知识冻结与幻觉问题,以及Agent架构的规划、记忆与工具调用能力。文章提供了从Dify私有化部署到大模型私有化部署的实操案例,帮助开发者快速搭建企业级AI应用。下文将基于此架构展开RAG与Agent的实际应用案例。
1、企业级大模型应用场景
1.1 场景1:基于RAG架构的开发
⛳️背景:
- 大模型的知识冻结
- 大模型幻觉
随着 LLM 规模扩大,训练成本与周期相应增加。因此,包含最新信息的数据难以融入模型训练过程,无法及时反映最新的信息或动态变化。导致 LLM 在应对诸如“请推荐当前热门影片”等时间敏感性问题。
1.1.1 举例
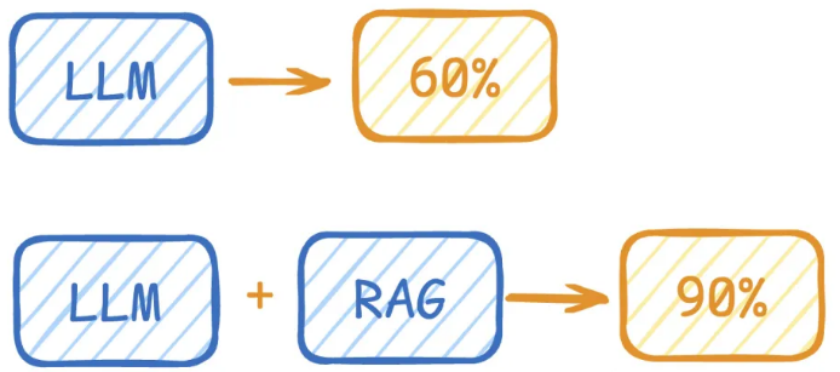
LLM在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了,而此时RAG给了一些提示和思路,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%到了90%!
1.1.2 何为RAG?
Retrieval-Augmented Generation(检索增强生成)
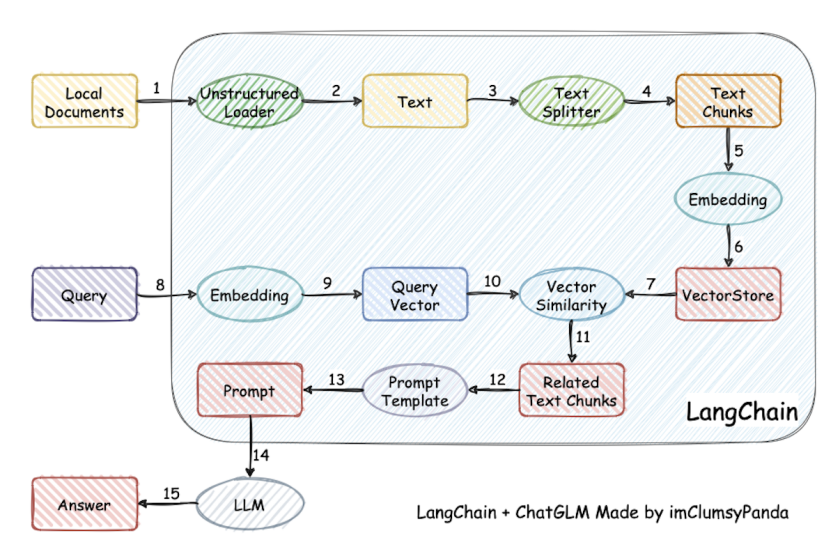
检索-增强-生成过程:检索可以理解为第10步,增强理解为第13步(这里的提示词包含检索到的数据),生成理解为第15步。
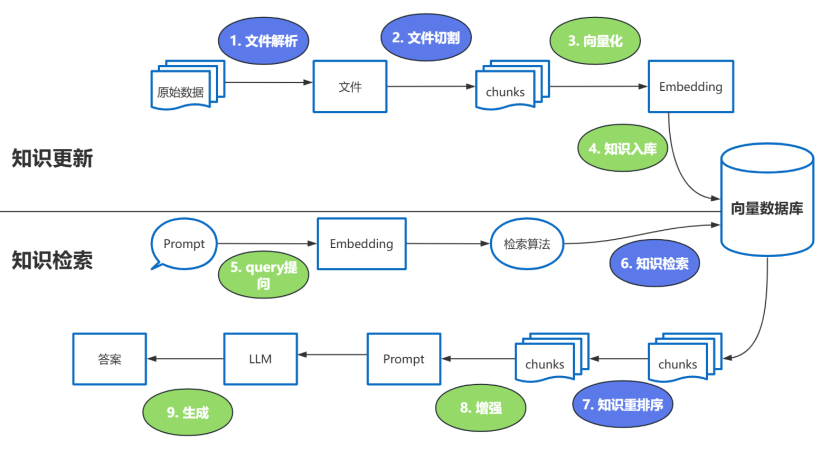
这里有三个位置涉及到大模型的使用:
- 第3步向量化时,需要使用
EmbeddingModels - 第7步重排序时,需要使用
RerankModels。可对初步召回的较多chunk(如 top 20 或 top 50)进行精排,提高召回准确率,防止LLM 处理无关信息,减少时间和成本。 - 第9步生成答案时,需要使用
LLM。
关于这些模型怎么部署,在后文有讲解,前面先看原理,一步一步学~
1.1.3 Reranker的使用场景
适合:追求回答高精度和高相关性的场景中特别适合使用Reranker,例如专业知识库或者客服系统等应用。
不适合:Reranker相较于RAG的成本更高。此外,引入reranker会增加召回时间,增加检索延迟。服务对响应时间要求高时,使用reranker可能不合适。
1.2 场景2:基于Agent架构的开发
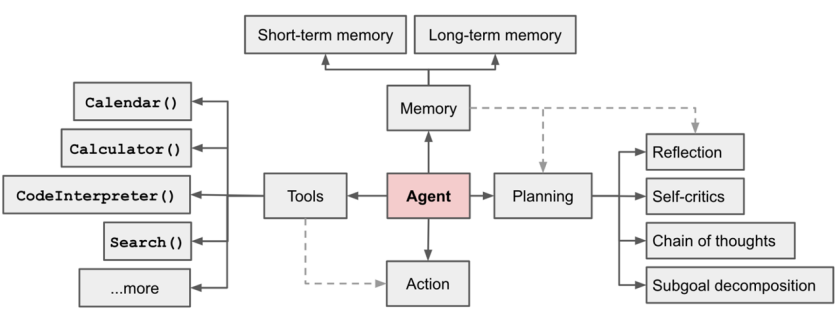
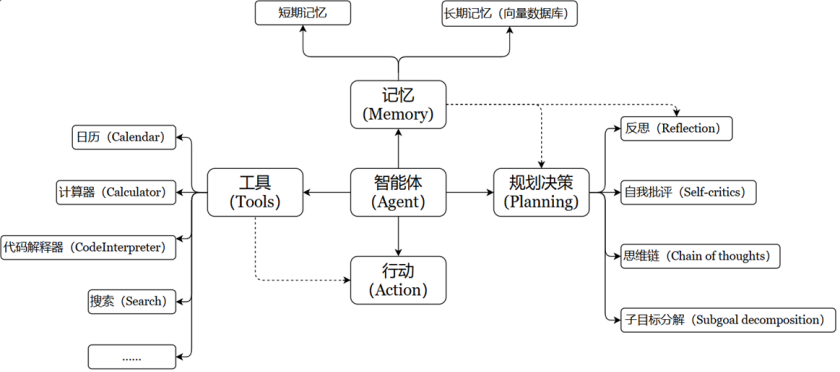
充分利用 LLM 的推理决策能力,通过增加规划、记忆和工具调用的能力,构造一个能够独立思考、逐步完成给定目标的智能体。
OpenAI的元老翁丽莲于2023年6月在个人博客首次提出了现代AI Agent架构。
一个数学公式来表示:
✍️ Agent = LLM + Memory + Tools + Planning + Action
📌智能体核心要素被细化为以下模块:
🎯大模型(LLM):
作为“大脑”:提供推理、规划和知识理解能力,是AI Agent的决策中枢。
大脑主要由一个大型语言模型 LLM 组成,承担着信息处理和决策等功能, 并可以呈现推理和规划的过程,能很好地应对未知任务。
🎯记忆(Memory)
智能体像人类一样,能留存学到的知识以及交互习惯等,这样的机制能让智能体在处理重复工作时调用以前的经验,从而避免用户进行大量重复交互。
- 短期记忆:存储单次对话周期的上下文信息,属于临时信息存储机制。受限于模型的上下文窗口长度。
- 长期记忆:可以横跨多个任务或时间周期,可存储并调用核心知识,非即时任务。
- 长期记忆,可以通过模型参数微调(固化知识)、知识图谱(结构化语义网络)或向量数据库(相似性检索)方式实现。
以人作类比:
- 短期记忆:在进行心算时临时记住几个数字
- 长期记忆:学会骑自行车后,多年后再次骑起来时仍能掌握这项技能
🎯工具使用(Tool Use)
调用外部工具(如API、数据库)扩展能力边界。
🎯规划决策(Planning)
通过任务分解、反思与自省框架实现复杂任务处理。例如,利用思维链(Chain of Thought)将目标拆解为子任务,并通过反馈优化策略。
🎯行动(Action):
- 实际执行决策的模块,涵盖软件接口操作(如自动订票)和物理交互(如机器人执行搬运)。比如:检索、推理、编程等。
- 智能体会形成完整的计划流程。例如先读取以前工作的经验和记忆,之后规划子目标并使用相应工具去处理问题,最后输出给用户并完成反思。
2、企业级大模型应用部署实操案例
🎯 企业要想保证数据的安全,就需要实现私有化的部署。包括大语言模型、Embedding嵌入模型、ReRank重排序模型、多模态模型等。
2.1 整体部署方案
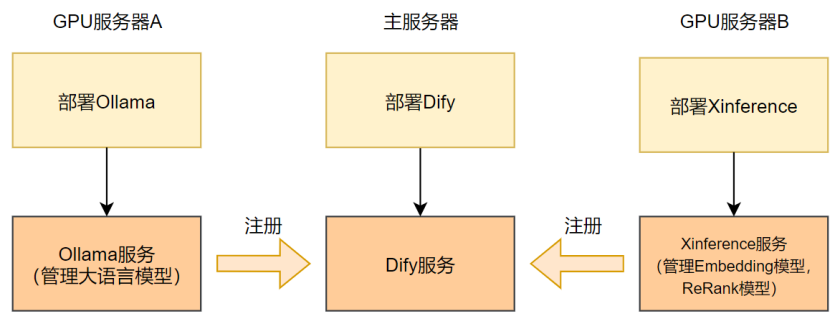
⛳️说明:
- 在Dify的私有化部署中,我们会结合不同的模型服务平台来满足多样的需求,例如Ollama和Xinference。
- 我们将这两个平台分别部署在不同的服务器上,以便展示Dify管理多个外部模型服务的能力。
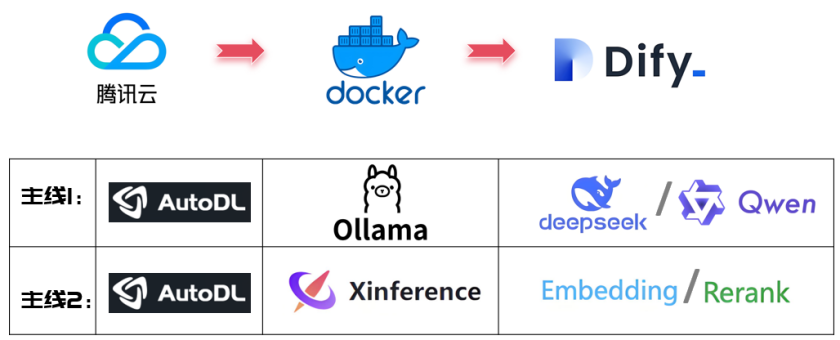
针对上图,这里有几个问题。
- 问题1:这个项目中只把Dify安装在了Docker中。Ollama、Xinference直接部署在GPU服务器,没有在Docker中。为什么?
首先说,Ollama、Xinference是可以部署到Docker中的。但是Ollama、Xinference中模型使用,需要消耗大量GPU,而Docker中默认是使用CPU,而不能使用GPU的。所以:
- 方案1:Ollama、Xinference不安装在Docker中
- 方案2:Ollama、Xinference安装Docker中,但是需要额外安装其他的软件,支持GPU的调用。
这里使用方案1,只将Dify安装到docker中,Ollama和Xinference不安装到docker中。
- 问题2:为什么不在Ollama平台安装嵌入模型(Embedding Models)和重排序模型(ReRank Models)?
Ollama专注于简化大语言模型(LLM)的本地部署和管理,其核心优势在于LLM的易用性和快速上手。对嵌入模型(Embedding Models)和重排序模型(ReRank Models)的直接支持相对有限,可用的模型也较少甚至直接没有。
- 问题3:Xinference不了解,简单介绍一下?
Xinference是一个功能更全面的模型服务框架,它不仅支持部署和管理大语言模型,还对嵌入模型和重排序模型提供了广泛且灵活的支持。
- 问题4:为何考虑多服务器部署?
虽然将Ollama、Xinference与Dify部署在同一台服务器上是可行的,但采用分离部署(即将Ollama和Xinference分别部署在独立的服务器上)通常能带来以下好处:
- 好处1:分散计算压力,优化资源利用
大语言模型及相关AI模型的运算(尤其是推理过程)对GPU等计算资源消耗较大。通过将不同的模型服务部署在不同的服务器上,可以将计算负载分摊开,避免单一服务器资源瓶颈,确保Dify平台及各个模型服务的稳定高效运行。当特定模型被调用时,其计算压力将主要集中在承载该模型的服务器上。
- 好处2:提高可扩展性和灵活性
随着Dify平台上接管的应用增多或特定模型调用频率增加,可能需要独立扩展某个模型服务(如增加更多GPU资源给Xinference服务器)。多服务器架构为此类精细化的资源扩展和管理提供了便利。
- 好处3:演示Dify的分布式模型管理能力
此架构清晰地演示了Dify平台如何有效地集成和管理部署在不同服务器上的Ollama和Xinference所提供的模型服务,以满足不同AI应用场景下的需求。这对于构建复杂的、分布式的AI应用基础设施具有实际参考意义。
2.2 Dify平台私有化部署
2.2.1 Dify平台的介绍
Dify 作为一个综合性的LLM应用开发平台,内置了构建现代生成式AI应用所需的几乎所有关键技术栈。
🎯Dify 具体功能如下:
- 基于Agent构建智能体
- 基于RAG构建私有知识库
- 基于Workflow构建智能应用
Dify 是当今最优雅、门槛最低、最受欢迎、效果最好的大模型开发平台之一。
无论是经验丰富的程序员还是初涉AI领域的团队(如产品经理、运营人员),都能够快速、高效地搭建并运营生产级别的生成式 AI 应用。
-
官网
https://dify.ai/zh
-
文档说明
https://github.com/langgenius/dify/blob/main/README_CN.md
说明:访问Dify官网需要魔法
Dify 同时提供了⼀套易用的图形用户界面 (GUI)和完善的 API 接口。这为开发者节省了大量重复"造轮子"(例如,与不同模型 API 对接、管理对话状态、实现 RAG 流程等)的时间,使其可以将更多精力专注在业务逻辑的创新和满足特定用户需求上。
2.2.2 租赁Dify服务器:腾讯云为例
企业用户可以选择租用云服务器,或者在本地的服务器中部署Dify。因为Dify所需的资源很小,一个轻量级的服务器足以支持运行。
我们需要租赁一个云服务器去运行Dify服务:腾讯云。
-
官网
https://cloud.tencent.com/
2.2.2.1 基础配置
https://buy.cloud.tencent.com/cvm
如果是企业中使用或者个人资金充裕且业务稳定的话,可以选择长租使用。期望优惠的话,可以选择竞价实例。竞价实例,在性能和稳定性上,与按量计费模式没有差别。
竞价实例,只要有人租长期的服务器就有可能把你的服务器踢掉,实例被竞价释放也是有解决办法的,后续会去讲。
地域选择:没有要求,自己根据需要选即可。
实例配置:根据自己需求选择,无具体要求。这里我选择4核8GB【官方要求最低:2核4G】。
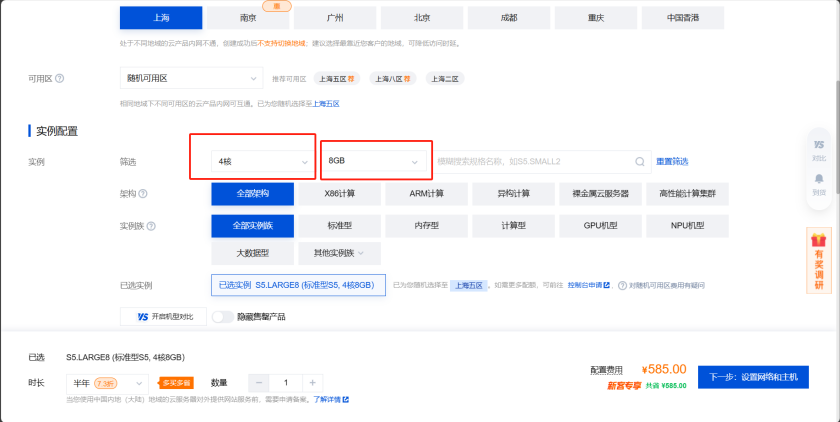
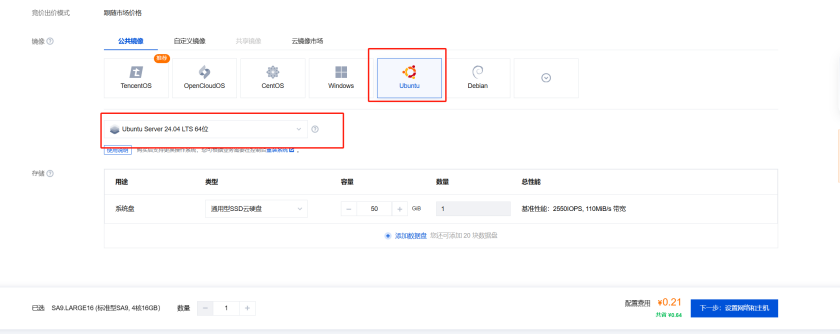
镜像:选择CentOS、Ubuntu都可以,这里使用了Ubuntu。选择后点击下一步。

2.2.2.2 设置网络和主机
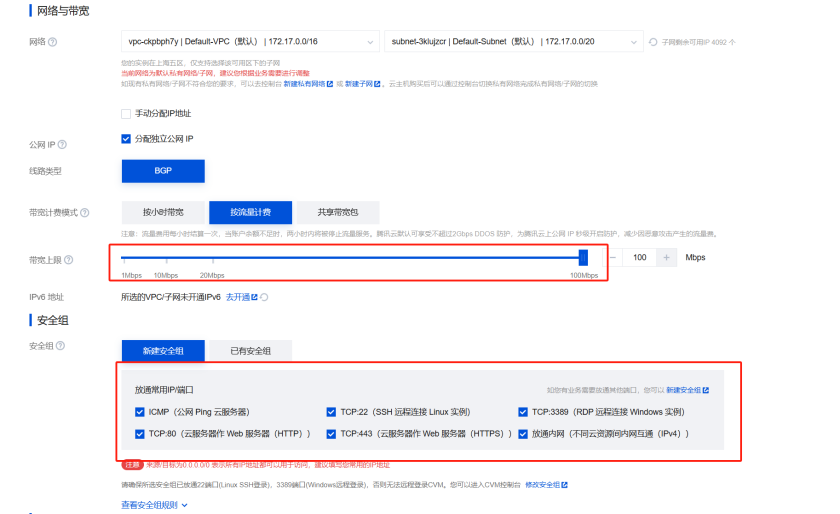
拉满带宽上限,新建安全组,把常用的端口都开启
命名实例,设置密码atguigu_123,进行下一步
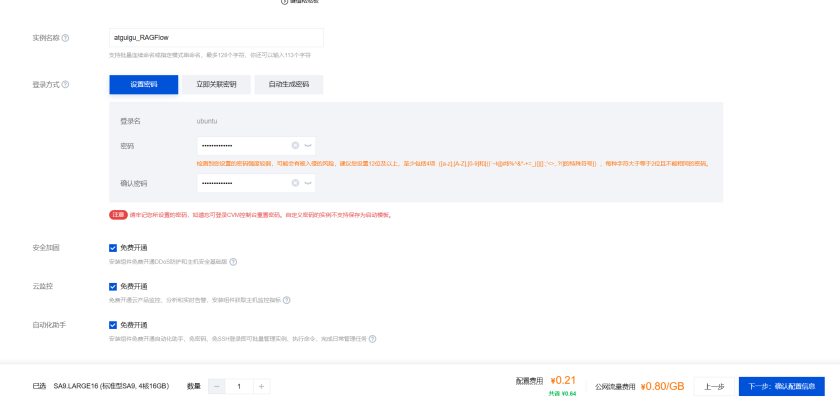
开通
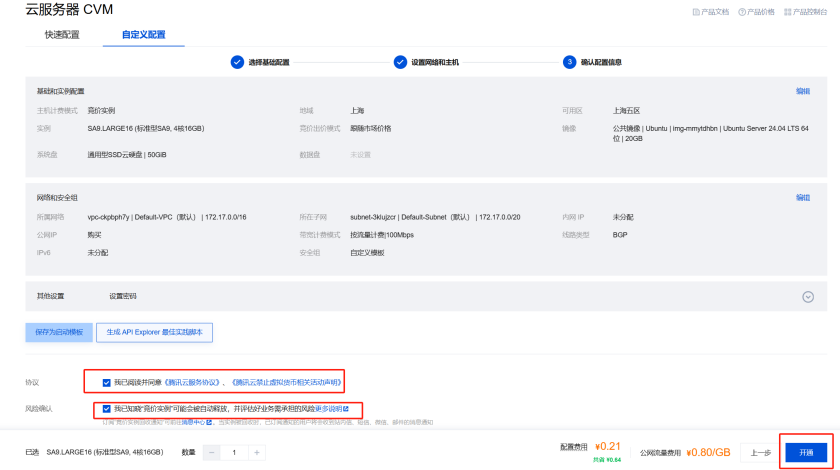
2.2.2.3 远程登录服务器
这里使用任何一款 SSH 工具均可以
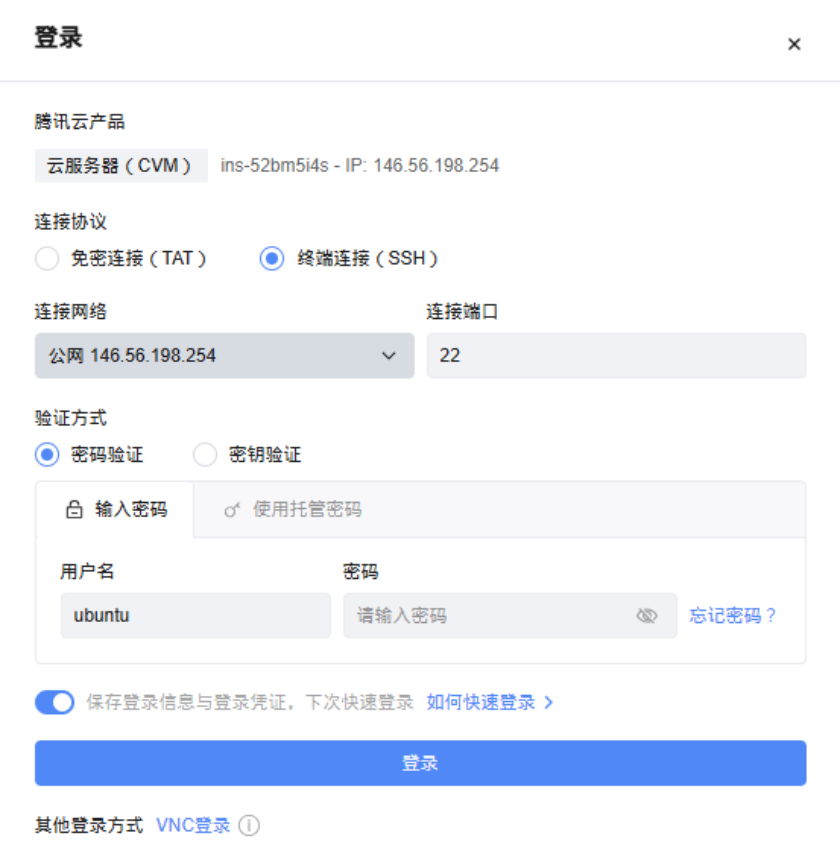
创建好了,通过这个公网IP,端口使用22,账号ubuntu,密码使用你设置的密码。使用你的远程连接工具XShell或 final shell 连接即可。
XShell界面如下:
Final Shell界面如下:
2.2.3 部署Docker
部署dify平台,需要基于docker环境,而腾讯云新建的云平台上默认是没有docker的。接着,需要在腾讯云租用的服务器中部署Docker。

🎯什么是Docker?
- Docker是一种容器化技术,相较于传统的通过虚拟机技术实现的虚拟化方案来说,Docker是⼀种更加轻量级的虚拟化解决方案。
- 它可以将应用程序及其依赖项打包成一个独立的容器,并在不同的环境中运行。通过Docker容器, 开发者可以轻松地构建、部署和运行应用程序,而无需担心环境配置和依赖问题。
按照下面的指令一步一步进行操作
#更新软件包
sudo apt update
sudo apt upgrade
#安装docker依赖
sudo apt install software-properties-common
sudo apt-get install ca-certificates curl gnupg lsb-releasesudo
sudo apt-get install ca-certificates curl gnupg lsb-release
#添加Docker官方GPG密钥
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
#添加Docker软件源(输入后根据提示按Enter)
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
#安装docker(输入后根据提示输入 y )
sudo apt-get install docker-ce docker-ce-cli containerd.io
执行sudo apt upgrade的时候会出现这个界面,按回车即可
之后如果在这个界面卡住,按几下回车即可

安装完毕,启动docker,并查看状态
sudo systemctl start docker
sudo systemctl status docker
如图所示即为启动成功
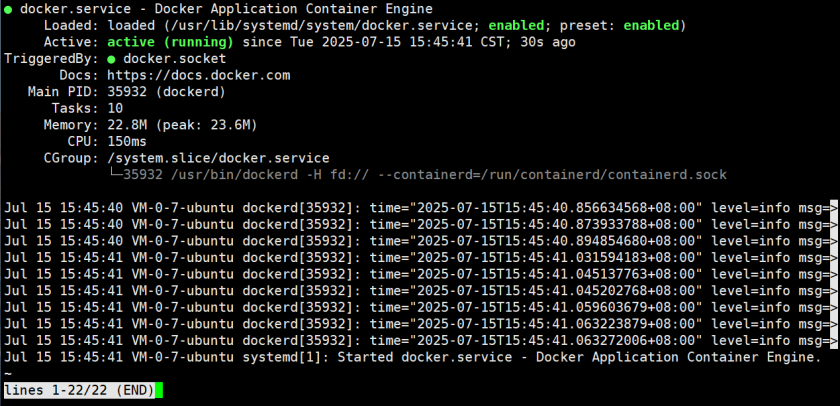
看到 **active(running)**状态说明docker已经正常启动
2.2.4 部署Dify
-
官网
https://github.com/langgenius/dify
这里我们可以参考Github官网的几个步骤
2.2.4.1 下载源码
# 在/opt下创建一个dify目录
cd /opt
sudo mkdir dify
然后在其Github主页进行复制
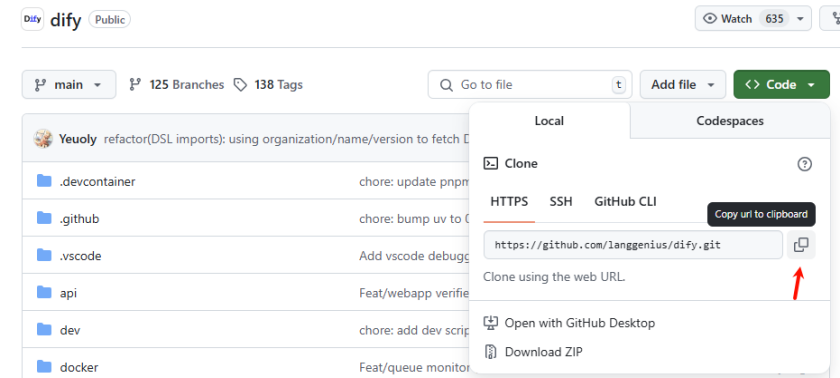
# 在/opt目录下执行git clone命令,这里我们可以通过镜像站进行下载
git clone https://github.com/langgenius/dify.git
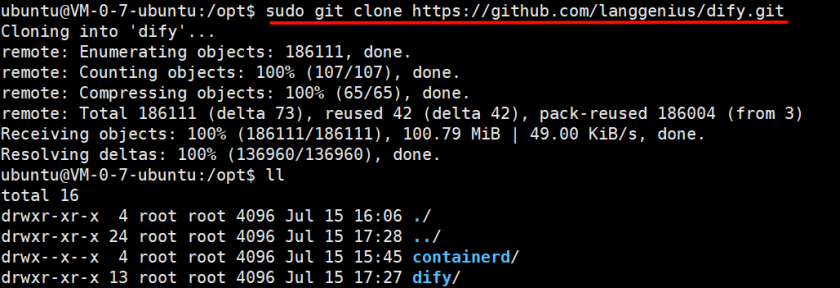
# 如果提示权限不足,可以使用如下指令,临时提权
sudo git clone https://github.com/langgenius/dify.git
如图即为下载完成
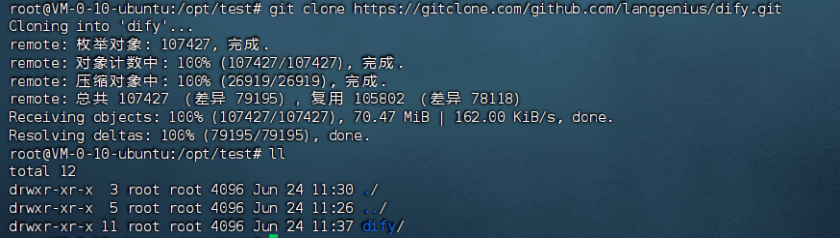
注意:如果使用github下载过慢,还可以使用码云(Gitee)或镜像网站替代 GitHub 直接下载,利用国内服务器加速。
⛳️****操作步骤:
1)注册码云账号(https://gitee.com)。
2)在码云新建仓库,选择「导入GitHub仓库」,粘贴https://github.com/langgenius/dify.git的链接。
3)导入完成后,使用码云生成的仓库地址克隆:
sudo git clone https://gitee.com/你的用户名/dify.git
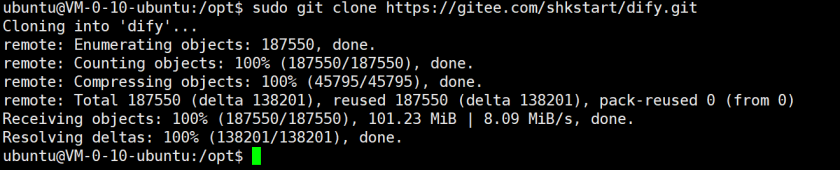
这里大家也可以直接使用我的链接:
sudo git clone https://gitee.com/fxf666888/dify.git
2.2.4.2 使用docker启动Dify
首先进入dify路径中的docker文件夹中
sudo docker compose up -d
执行失败,大概率会由于网络问题或镜像缺失问题发生报错。


进行镜像源的配置
sudo vi /etc/docker/daemon.json
添加下面的配置
{
"registry-mirrors": [
"https://docker.unsee.tech",
"https://dockerpull.org",
"https://docker.1panel.live",
"https://dockerhub.icu",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://5tqw56kt.mirror.aliyuncs.com",
"https://docker.hpcloud.cloud",
"http://mirrors.ustc.edu.cn",
"https://docker.chenby.cn",
"https://docker.ckyl.me",
"http://mirror.azure.cn",
"https://hub.rat.dev"
]
}
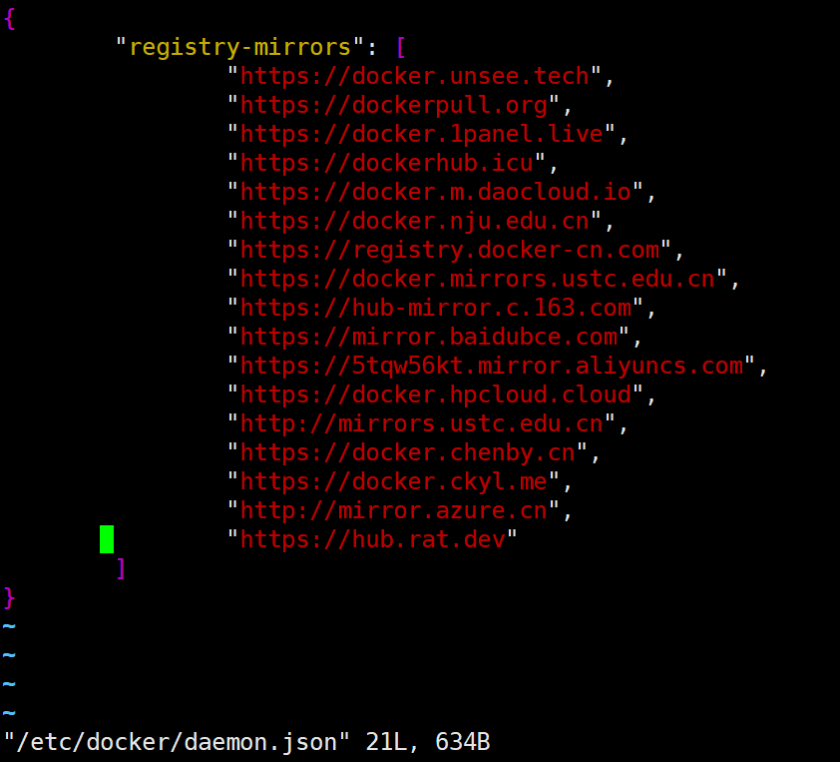
保存,然后在终端重新启动一下docker
# 重新登陆,需要输入密码
systemctl daemon-reload
systemctl restart docker
# 重新执行
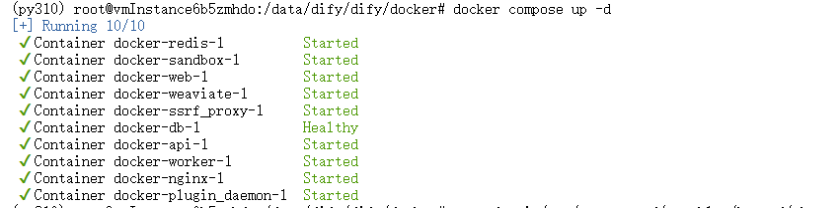
sudo docker compose up -d
开始正常下载了

注意:可能出现报错,报错如下

于是根据报错信息检查
sudo vi /etc/apparmor.d/tunables/home.d/ubuntu
删除掉报错信息中第七行的多余字符即可

重新运行,成功
2.2.4.3 设置镜像
为避免案例中的竞价实例被释放,可以在控制台中的快照中设置快照策略,即使被释放了也能保存快照,从而快速恢复
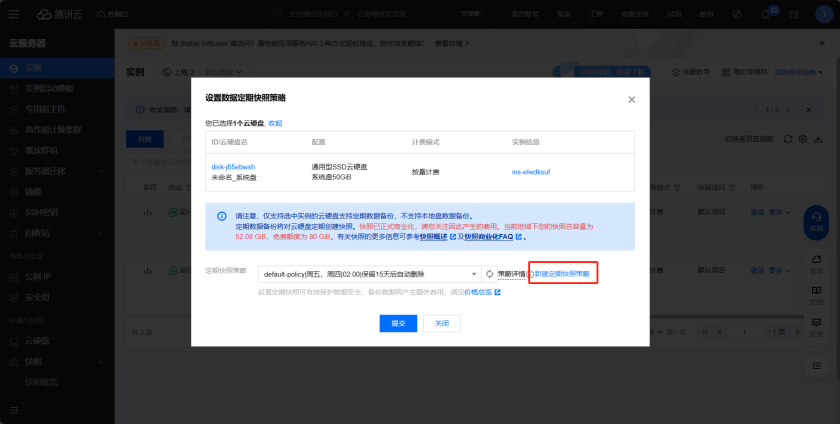
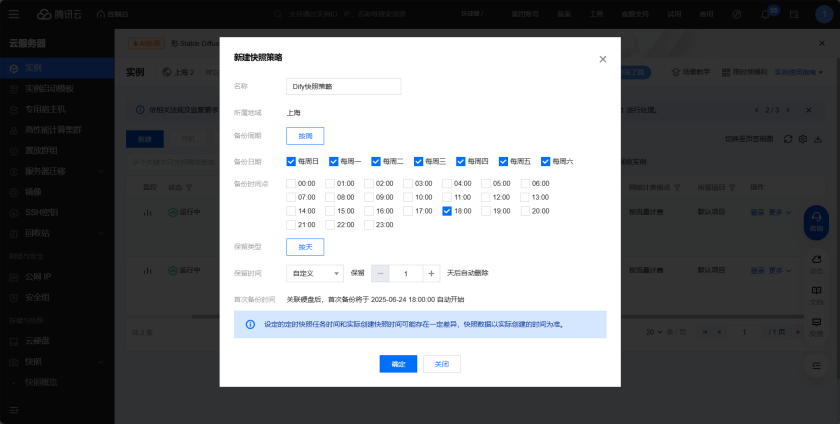
再次进入定期快照策略可发现已设置成功
如果要和其它人共享镜像,参考
https://cloud.tencent.com/document/product/213/4944
2.2.4.4 访问
根据自己的服务器进行地址的选择。比如说这里我的就是
http://146.56.221.168:80
如图所示为成功访问,进行注册、登陆即可【记好密码】
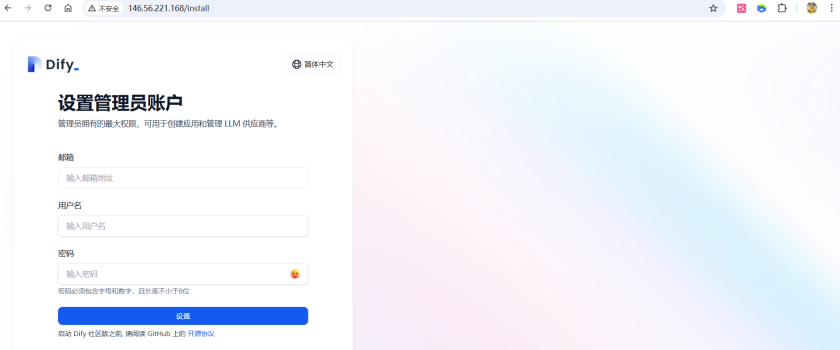
注意:如果一直无法加载进去,则需要重启docker再次尝试
在这里我们可以使用提供的在线大模型运营商,但是为了考虑到可能存在的数据安全问题,所以我们自己部署Ollama 和 Xinference,进而部署私有的大模型。
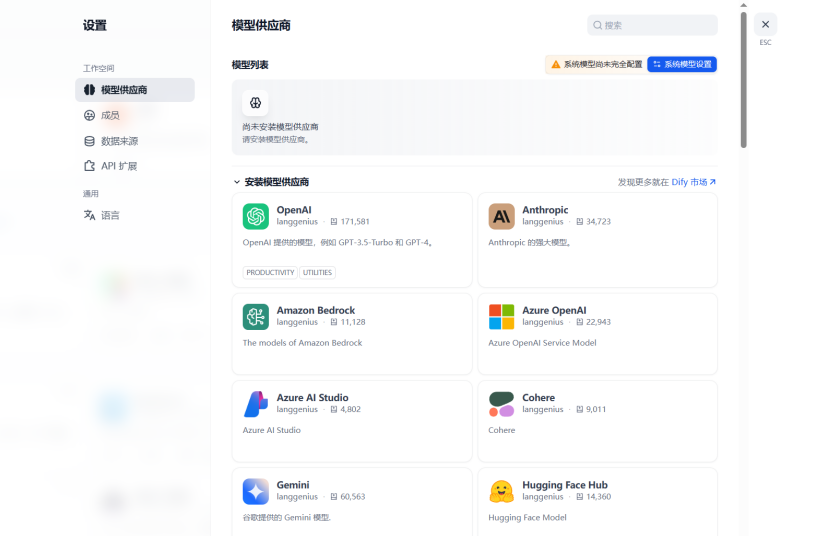
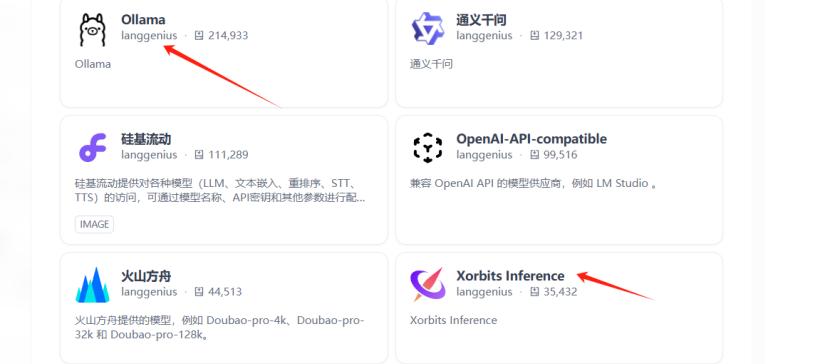
2.3 大模型私有化部署
2.3.1 租赁GPU服务器:AutoDL
这里我们选用AutoDL平台租赁服务器。这是一款面向开发者和企业的云计算平台,主要提供高性价比的GPU算力资源,支持AIGC、深度学习、云游戏、渲染测绘、元宇宙、HPC等应用。
- 平台地址
https://www.autodl.com/
注意:AutoDL服务器的资源比较紧俏,且比较贵
一台机器开机一个小时平均花费2元
建议:一般早上开始工作的时候开机,在结束一天工作的时候关机。
🎯 关于 AutoDL 的一些使用技巧,在我其他文章中也有介绍,感兴趣可以去看一看,比如👇
SSH 隧道,实现本地 Pycharm 调用远程云服务GPU训练大模型,开发者必学!
2.3.1.1 配置服务器+镜像
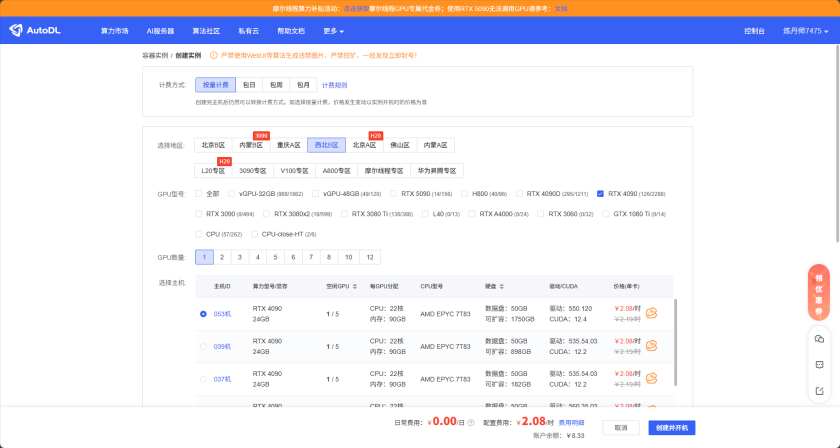
选择服务器:
这里可以选择西北B区的单卡4090作为我们的服务器,我们需要租赁两台服务器,一台部署Ollama,另一台部署Xinference。
注意:在AutoDL平台上,只提供了6006端口进行开放。
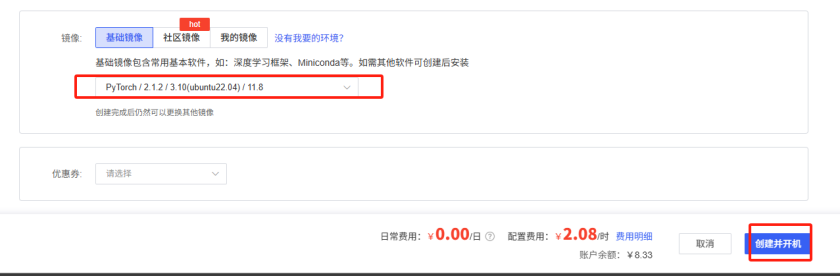
选择镜像版本:
2.3.1.2 XShell连接登录
复制该服务器的登录指令,通过远程连接工具进行登录
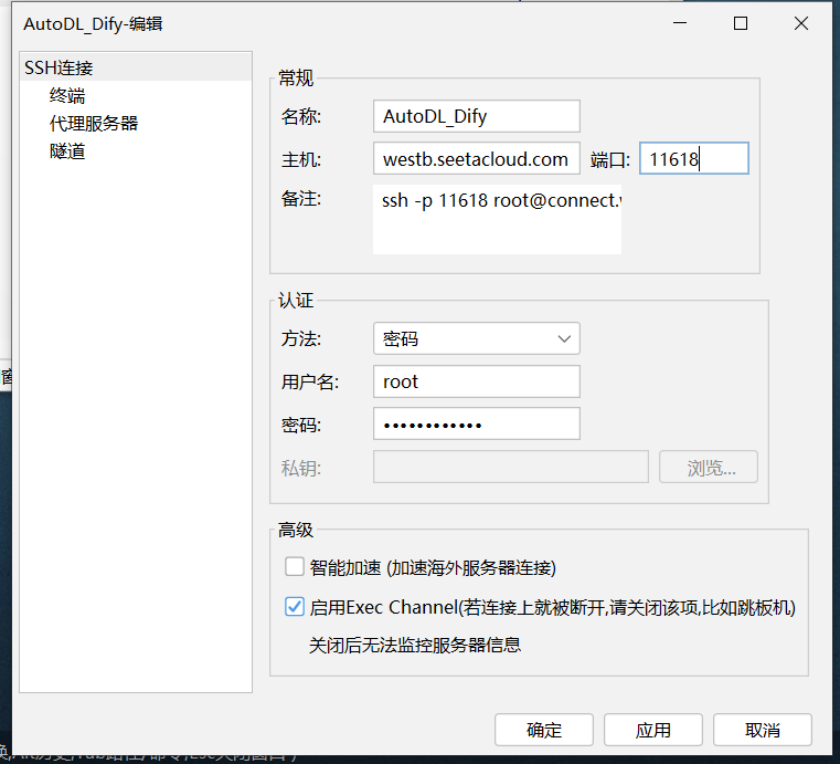
测试连接:
默认的用户名:root
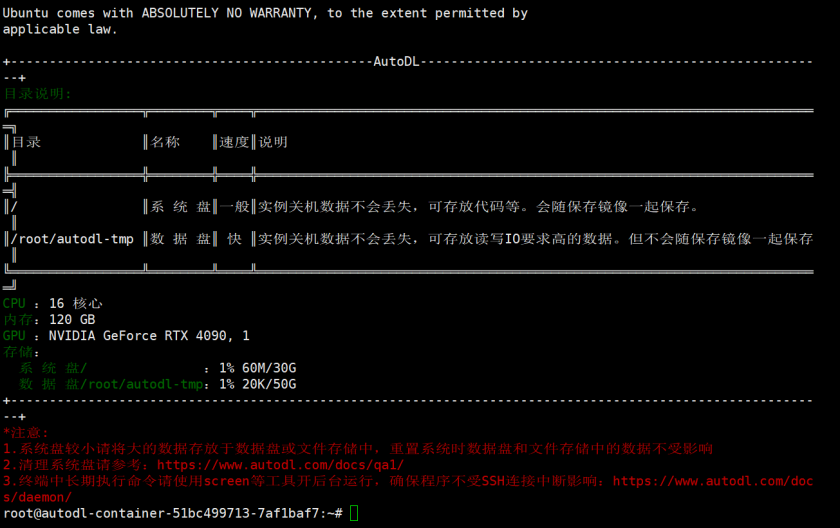
连接成功
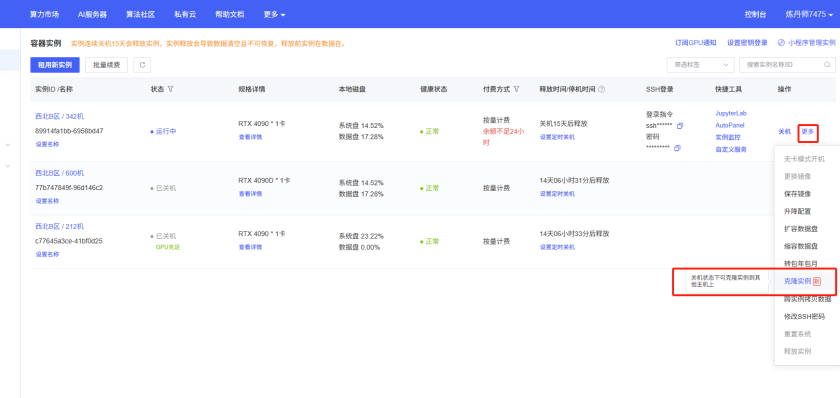
2.3.1.3 克隆实例
在关机状态下,进行实例克隆,创建出一个副本。
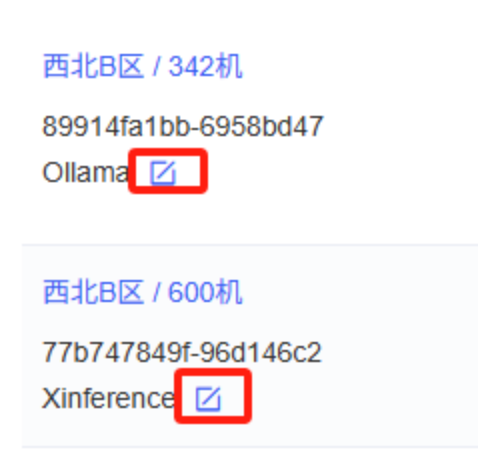
设置一下备注名称
2.3.1.4 开启学术资源加速
为下载一些外网的资源(比如Github、HuggingFace等),需要在当前终端中开启学术资源加速
免不了我们要在这个系统上安装一些软件。这些软件可能来自于如下的红框的位置。默认是下载不了的。那么就需要魔法或科学上网。这里我们称为:学术加速。
- https://www.autodl.com/docs/network_turbo/
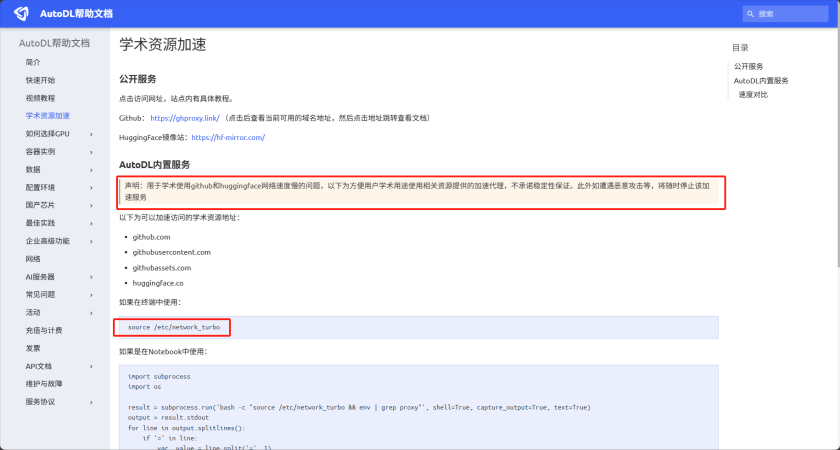
将框选住的一行复制到终端输入即可,简直不要太香!
source /etc/network_turbo

2.3.2 模型管理平台中部署Ollama
没有ollama之前,部署一个私有的大模型比较复杂。需要在主机上安装很多依赖的软件。但现在我们只需要安装Ollama,大模型相关的依赖,Ollama都提供好了。
当涉及到大语言模型(LLMs)的管理、部署和使用时,使用像 Ollama 、 XInference 和 LocalAI 这些模型管理工具可以显著提升模型的可管理性,提高工作效率。
Ollama是在Github上的一个开源项目,项目定位是:一个本地运行大模型的集成框架。通过将模型权重、配置文件和必要数据封装进由Modelfile定义的包中,从而实现大模型的下载、启动和本地运行的自动化部署及推理流程。
- Ollama官方地址:https://ollama.com
- Ollama Github开源地址:https://github.com/ollama/ollama
Ollama项目支持跨平台部署,目前已兼容Mac、Linux和Windows操作系统。无论使用哪个操作系统,Ollama项目的安装过程都设计得非常简单。
2.3.2.1 Ollama的部署(下载-启动)
使用连接工具打开我们用于部署AutoDL上的GPU服务器 Ollama
启动学术加速
source /etc/network_turbo
来到Linux如下目录
cd /data/dify/ #没有此目录,可以先创建。 sudo mkdir ./data 等
执行命令
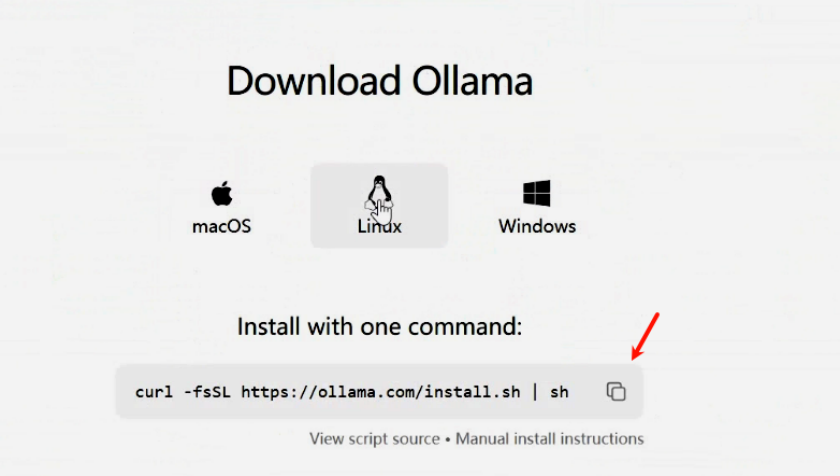
curl -fsSL https://ollama.com/install.sh | sh
上述指令来自于:
下载完毕
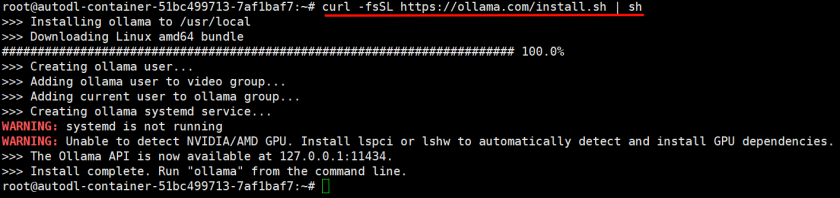
启动Ollama服务
OLLAMA_HOST=127.0.0.1:6006 ollama serve
2.3.2.2 Ollama中接入模型
地址:
https://ollama.com/library
查看可以部署哪些模型
https://ollama.com/library
举例:接入Qwen3:4b开源模型
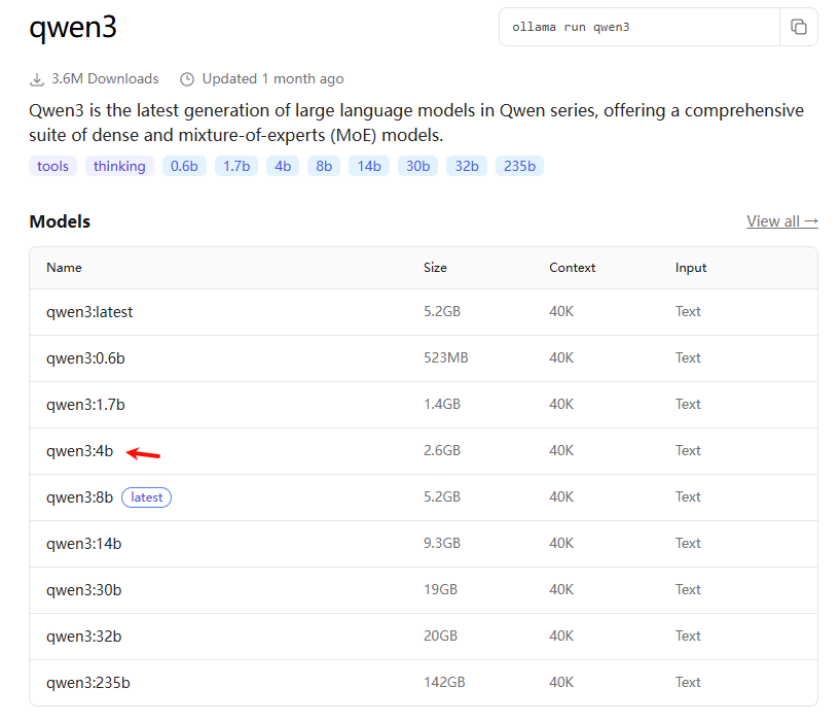
复制该指令
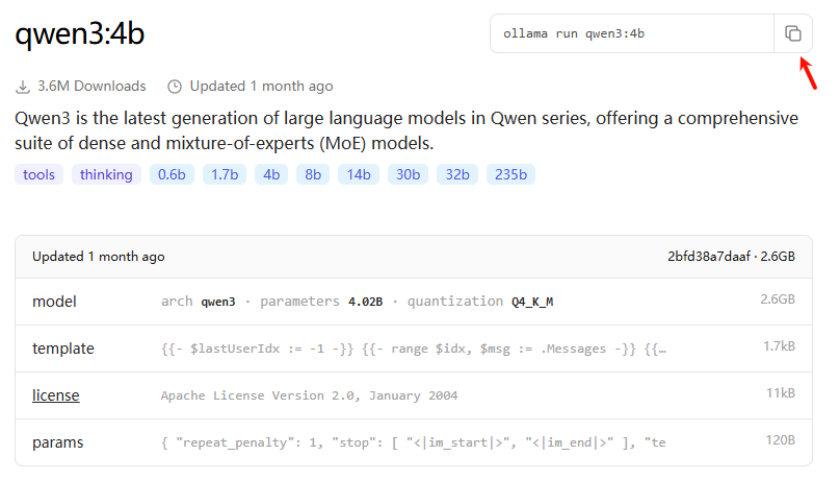
再开启一个终端,执行运行命令。会从网络下载该模型:
source /etc/network_turbo #先启动学术加速
OLLAMA_HOST=127.0.0.1:6006 ollama run qwen3:4b
#如果下载过慢,大家也可以下载较小的模型,比如:
OLLAMA_HOST=127.0.0.1:6006 ollama run qwen3:0.6b
安装成功后可以通过提问检验是否成功
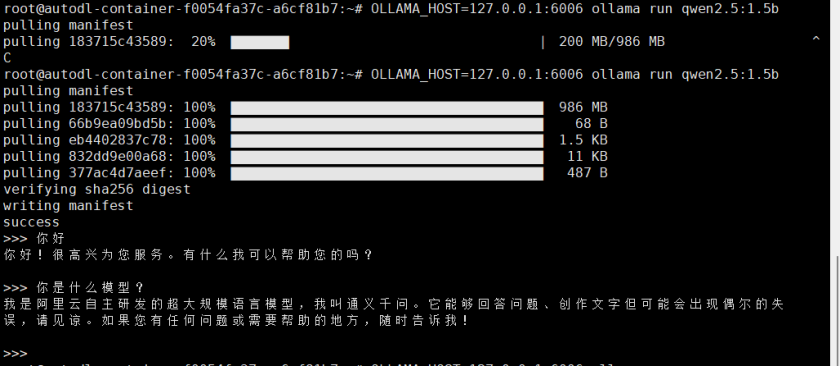
然后使用 Ctrl+d 退出该对话。
查看大模型的安装情况:
OLLAMA_HOST=127.0.0.1:6006 ollama list
如果下载较慢也可以将已经提供好的模型压缩包上传到~/.ollama/models/下,然后通过unzip命令解压后,将里面的内容移动到~/.ollama/models/下。
注意:这个目录需要启动ollama后才会出现,上传后,也需要重启****ollama
2.3.2.3 Dify配置大模型前打通隧道
需要在GPU服务器上的服务已启动的前提下,使用隧道工具在Dify所在的服务器打通隧道
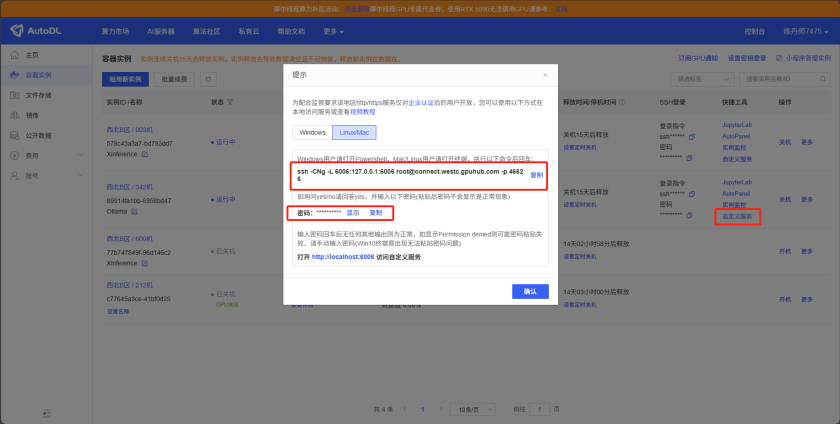
将第一行指令复制,另开一个腾讯云的dify的XShell会话终端,输入该指令。之后按照要求把代码复制粘贴进去,没有任何响应即为成功打通隧道。

2.3.2.4 Dify中接入Ollama中的大语言模型
在网页Dify页面进行操作:
设置-模型供应商-安装ollama服务
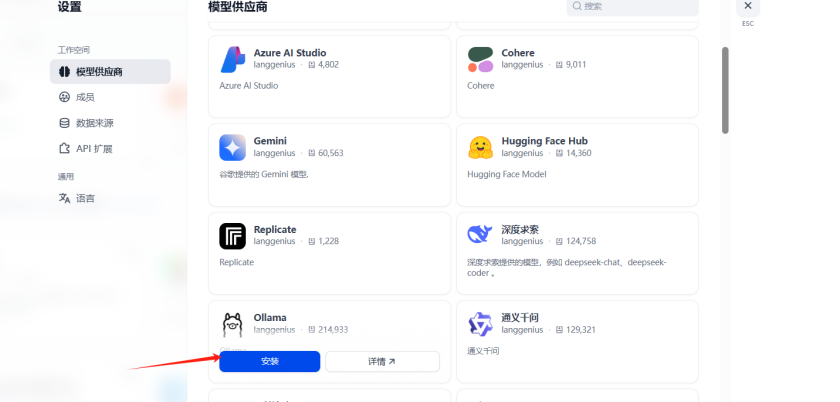
配置Ollama服务的模型
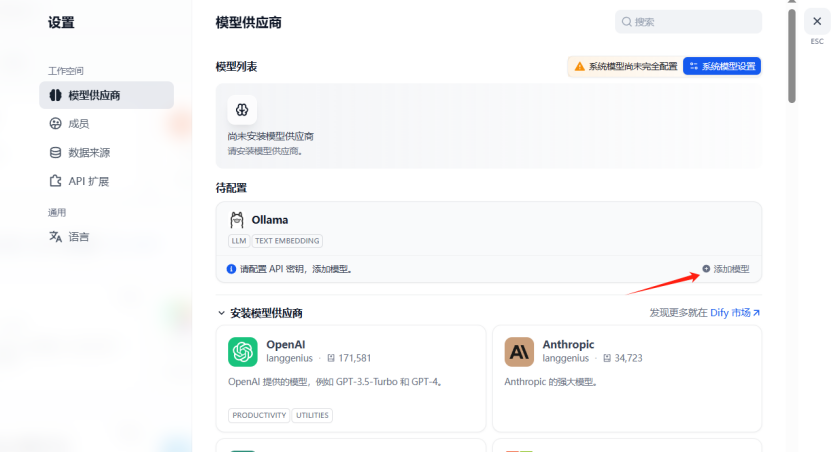
模型名称填写刚刚下载的qwen3:4b
URL中IP地址使用Dify服务器的内网IP****即可,端口号使用6006。点击保存
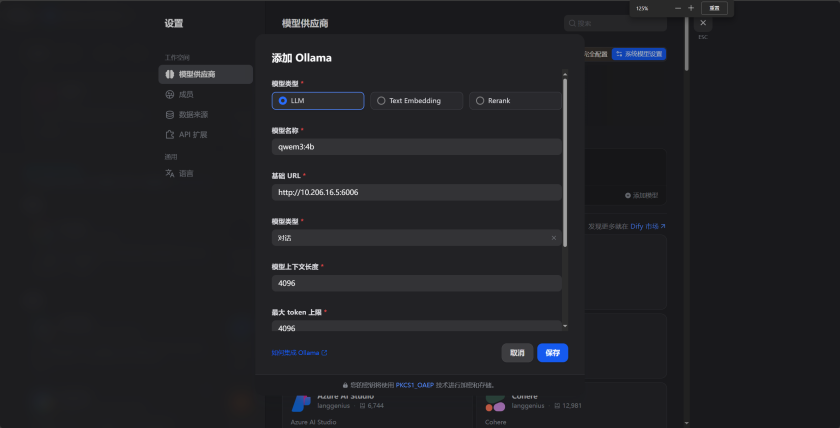
注:当显示添加成功后,但是没有模型的话,说明还未加载成功,并不是配置失败。需要等待一段时间即可刷新出来。配置失败是不会显示配置成功的。
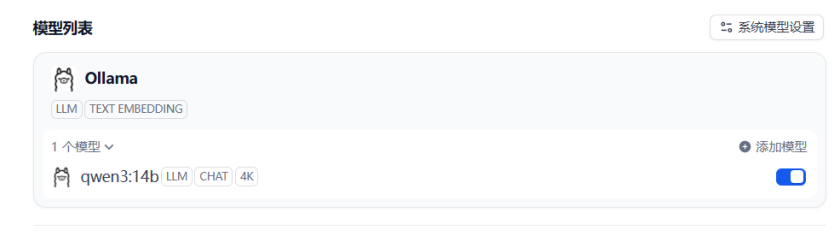
如图添加完毕
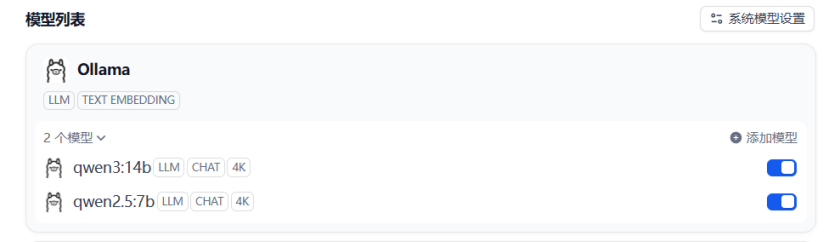
可以用相同的方法添加更多模型,比如这里可以在Ollama中下载一个qwen2.5:7b,用相同的方法接入到Dify中
2.3.3 模型管理平台中部署XInference
XInference 是⼀个强大且通用的分布式推理框架,也可以用于私有化部署和运行大语言模型,通过 XInference 可以简化各种AI模型的运行和集成,使开发者可以使用任何开源大语言模型、推理模型、多模态模型在云端或本地环境中运行、推理,创建强大的AI应用。
2.3.3.1 XShell登录服务器
地址参考如下:
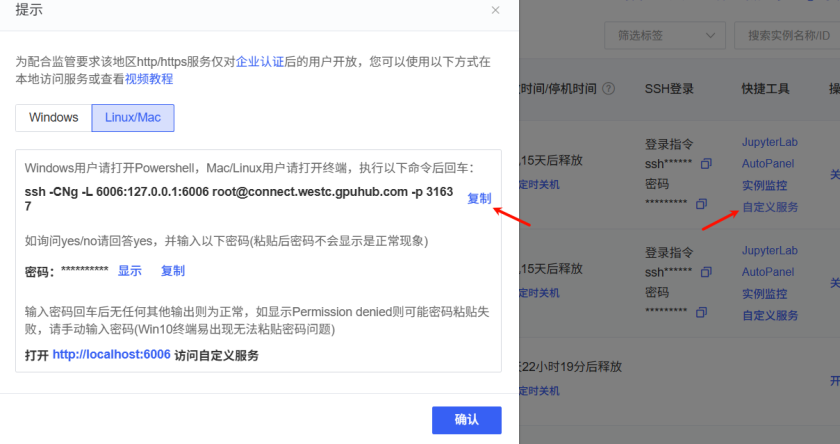
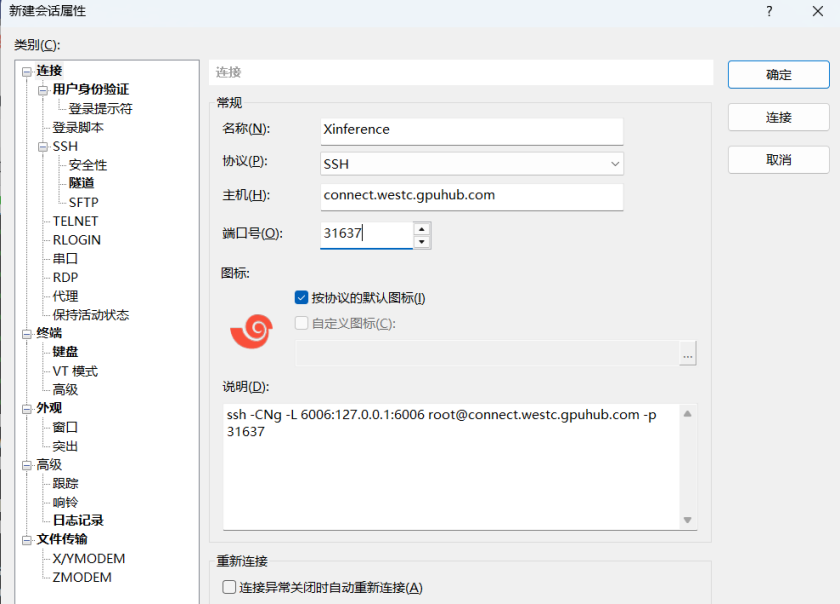
粘贴到XShell中进行登录:
用户名默认为root:
密码:

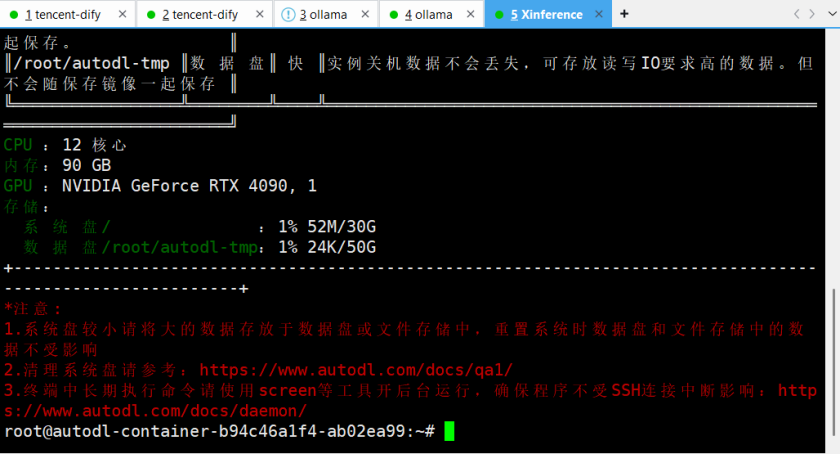
登录成功:
2.3.3.2 XInference的部署(下载)
开启学术加速
source /etc/network_turbo
依次输入如下指令,开始安装Xinference
注意:最新版本会有一些依赖上的冲突,所以下载如下这个版本
python -m pip install --upgrade pip
pip install 'xinference==1.5.0'
#安装torch
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch
#升级PyTorch
pip install --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
#启动服务
xinference-local --host 0.0.0.0 --port 6006
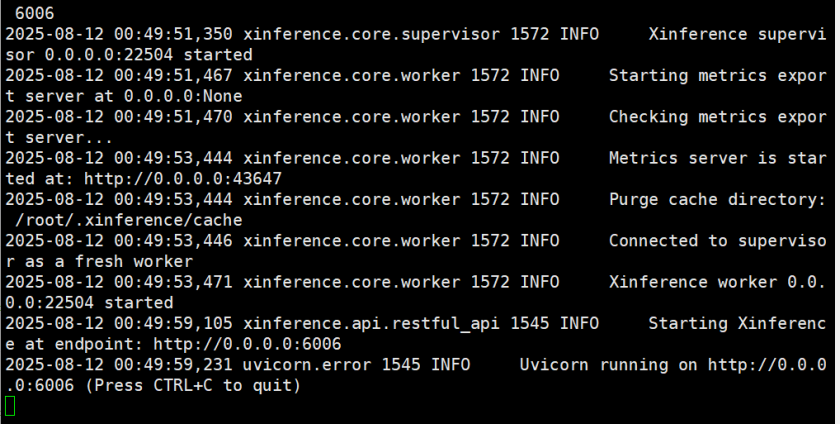
2.3.3.3 Windows平台访问
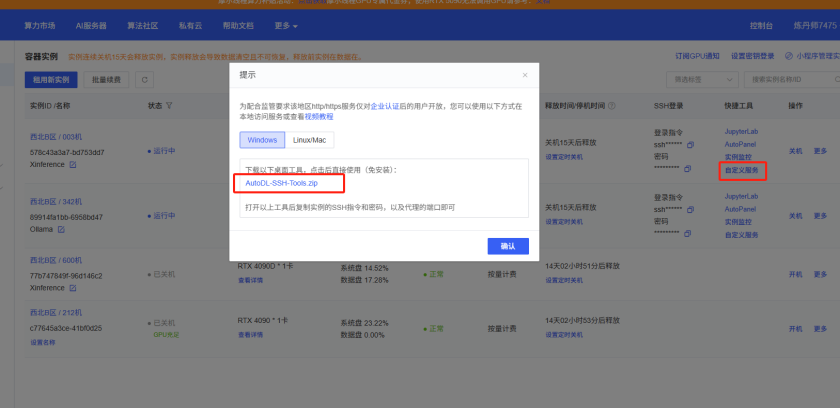
如此服务便启动了,我们可以通过使用Windows的AutoDL隧道工具对其进行访问。下载这个工具
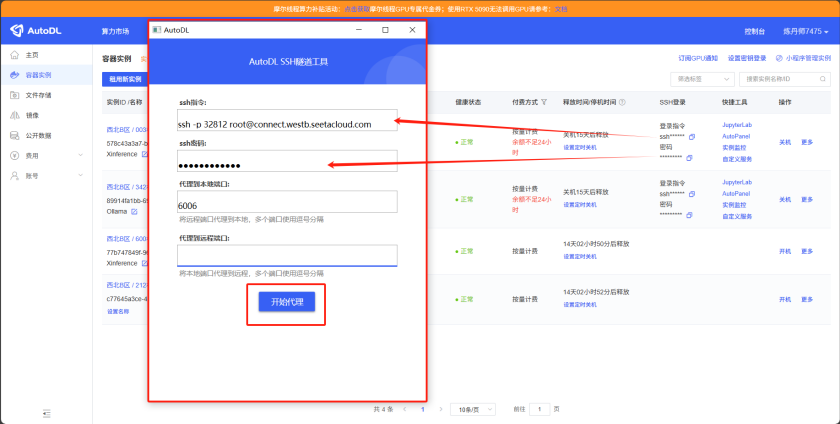
打开该工具,ssh指令和密码粘贴进去,代理到本地端口填写6006
访问 http://127.0.0.1:6006/
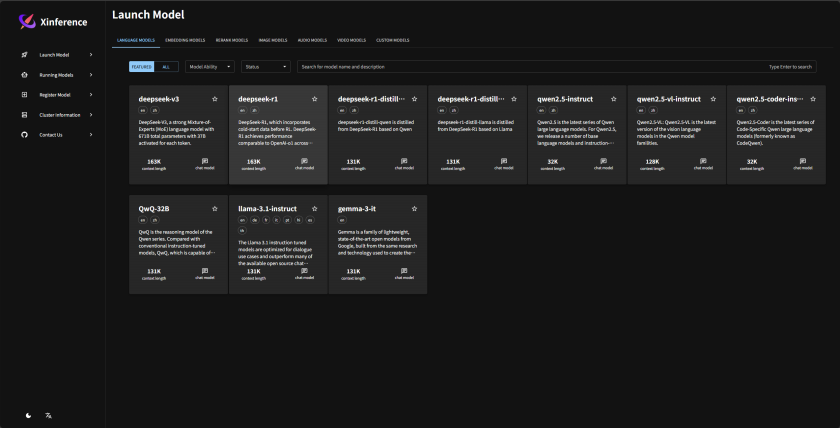
2.3.3.4 模型下载(嵌入+重排序模型)
选择嵌入模型,下载bge-large-zh-v1.5
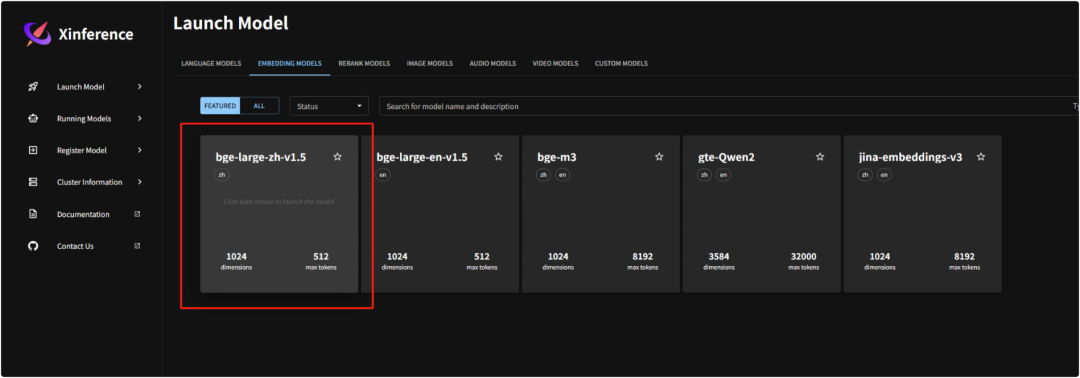
按照如下配置进行下载模型
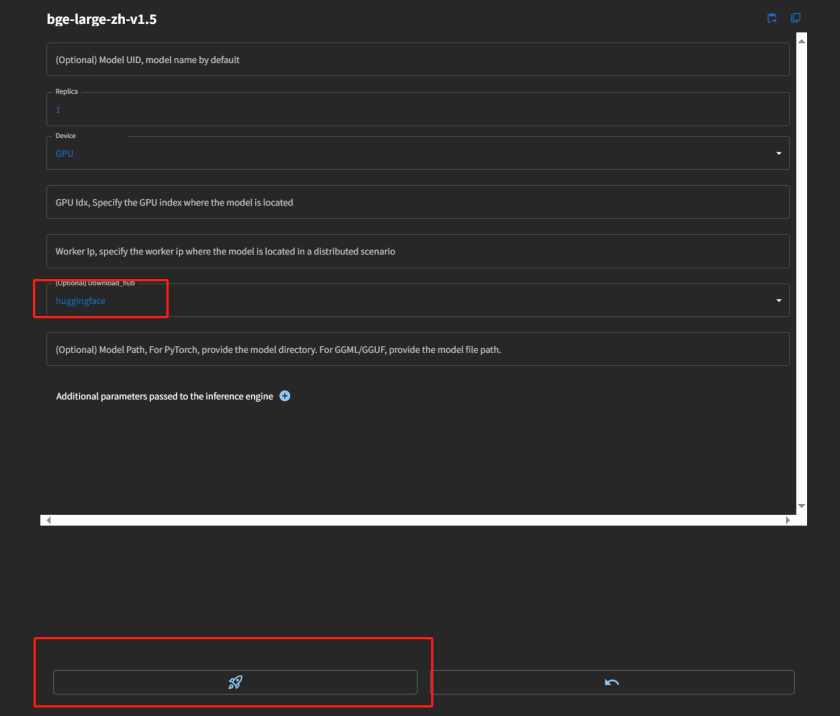
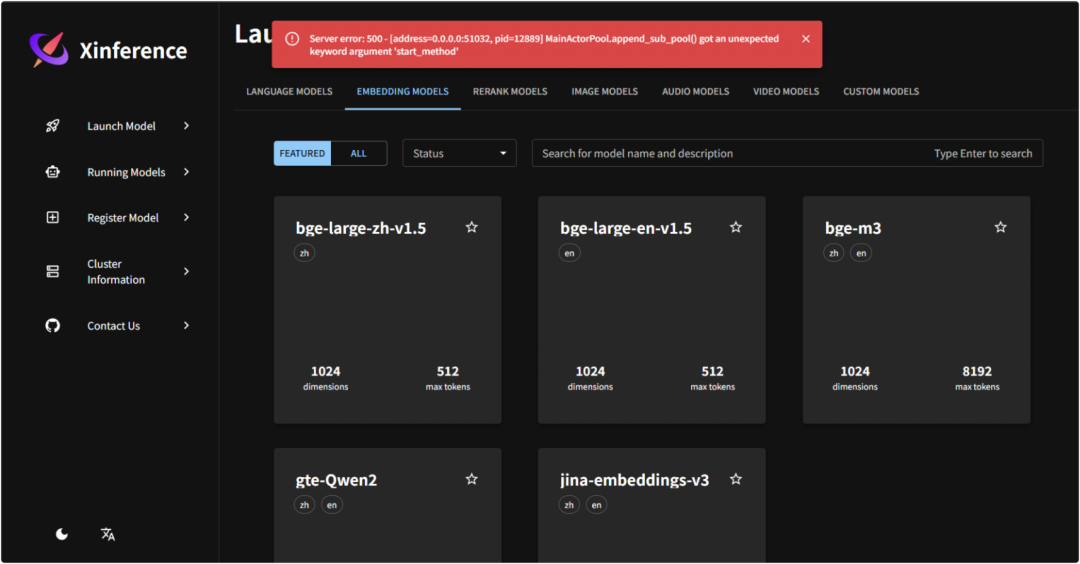
可能会出现兼容性问题报错,原因是 pip 默认安装的 xoscar v7.0+版本 api 与 xinference不兼容,降级到 xoscar v0.6.2 后可以正常启动。
Server error: 500 - [address=0.0.0.0:51032, pid=12889] MainActorPool.appendsubpool() got an unexpected keyword argument 'start_method'
pip install xoscar==0.6.2
#同时安装一些重要的依赖
pip install sentence-transformers
pip install sentencepiece transformers torch
之后重启Xinference服务,即可正常下载
#启动服务
xinference-local --host 0.0.0.0 --port 6006
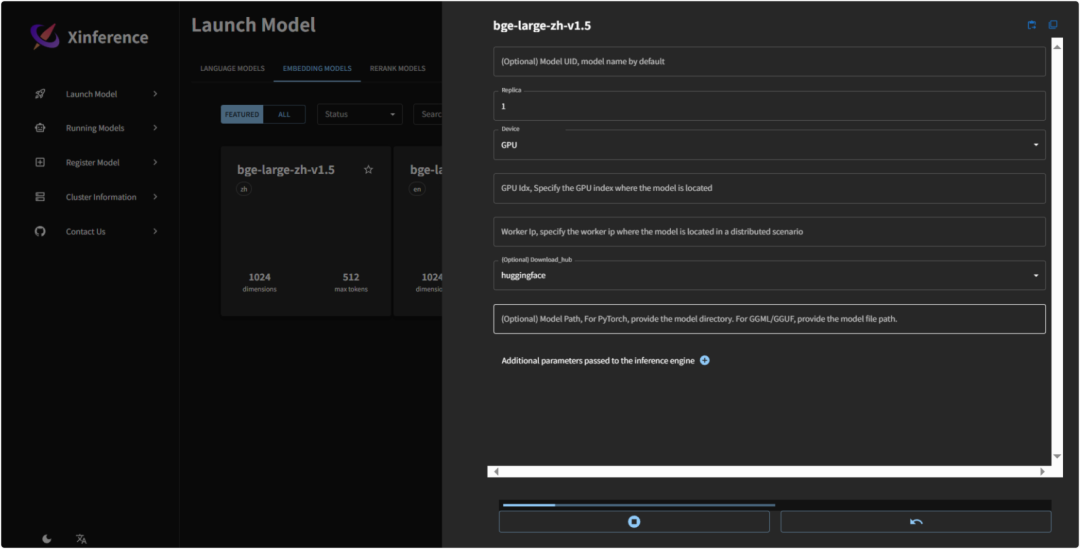
接着,再安装一个重排序模型:
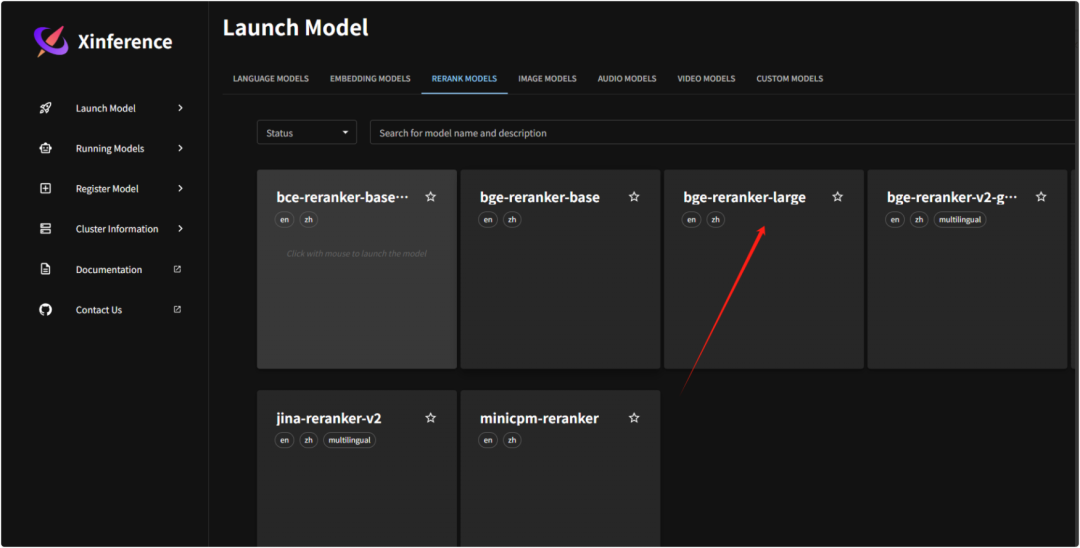
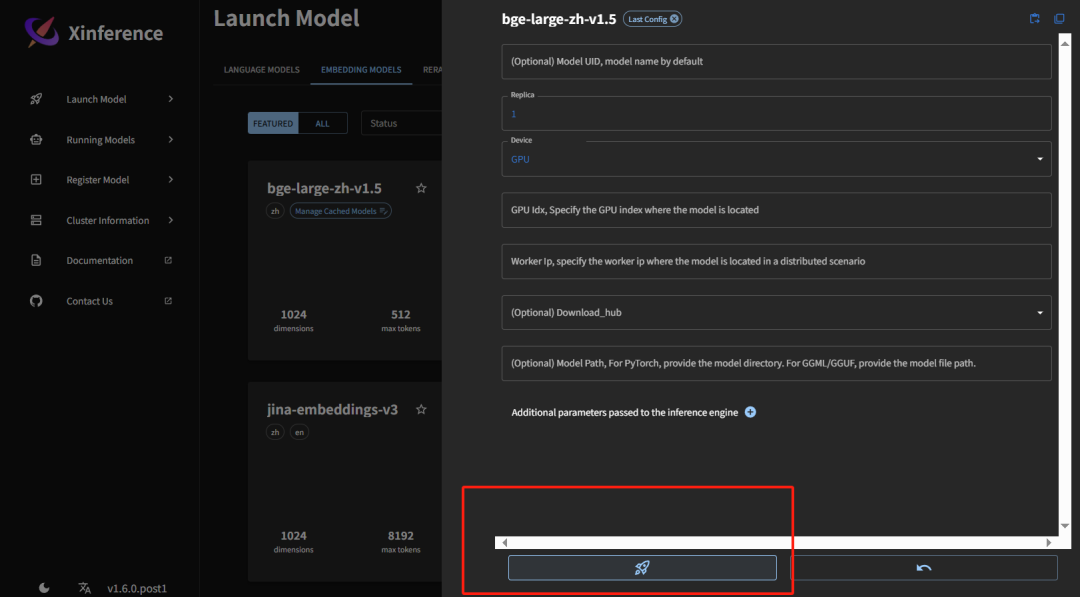
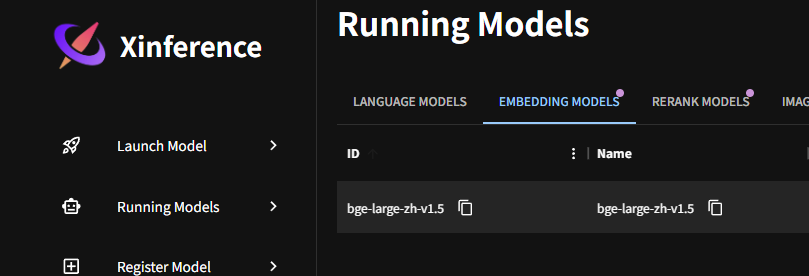
模型安装好了之后,通过launch运行,运行好的模型会在RunningModel中看到
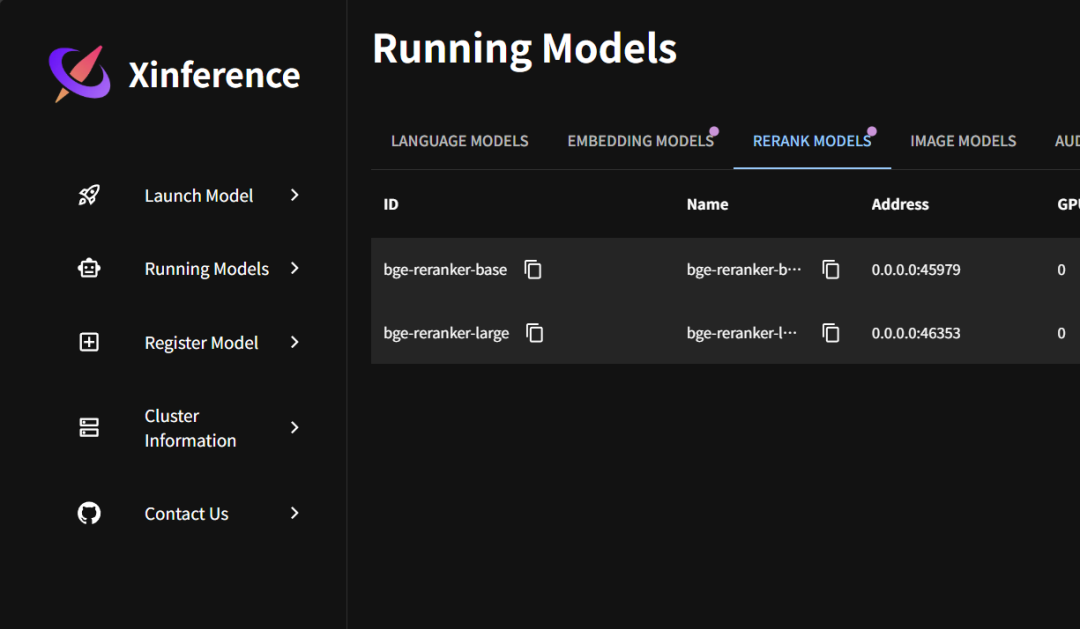
2.3.3.5 Dify配置大模型前打通隧道
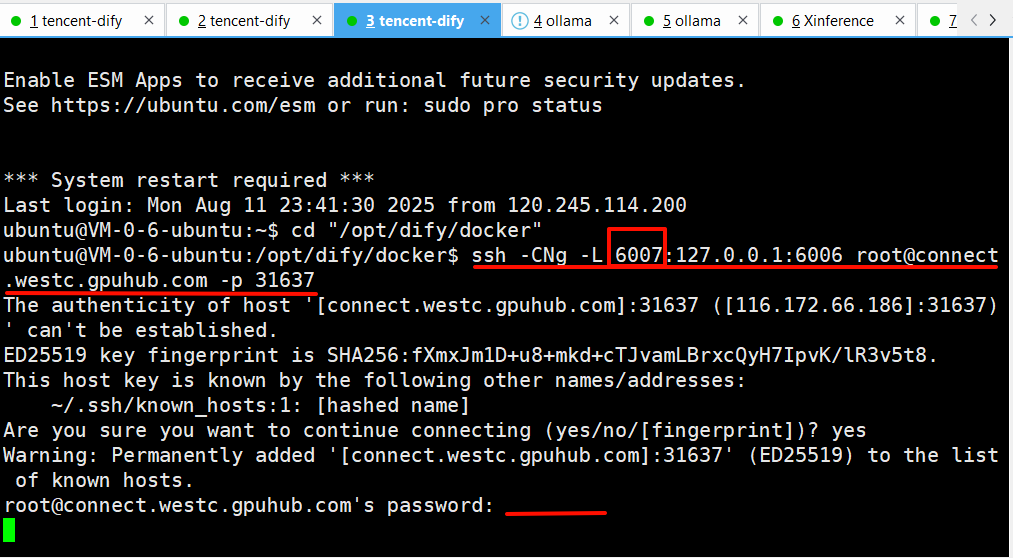
另起一个Dify服务器XShell会话,使用隧道工具,但是注意把本机端口号改为6007,因为6006被Ollama占用了,按照如下的示例去改造,把第一处的6006改为6007
ssh -CNg -L 6007:127.0.0.1:6006 root@connect.westc.gpuhub.com -p 31637
2.3.3.6 Dify接入Xinference中的模型
在网页Dify页面进行操作:
设置-模型供应商-连接Xinference
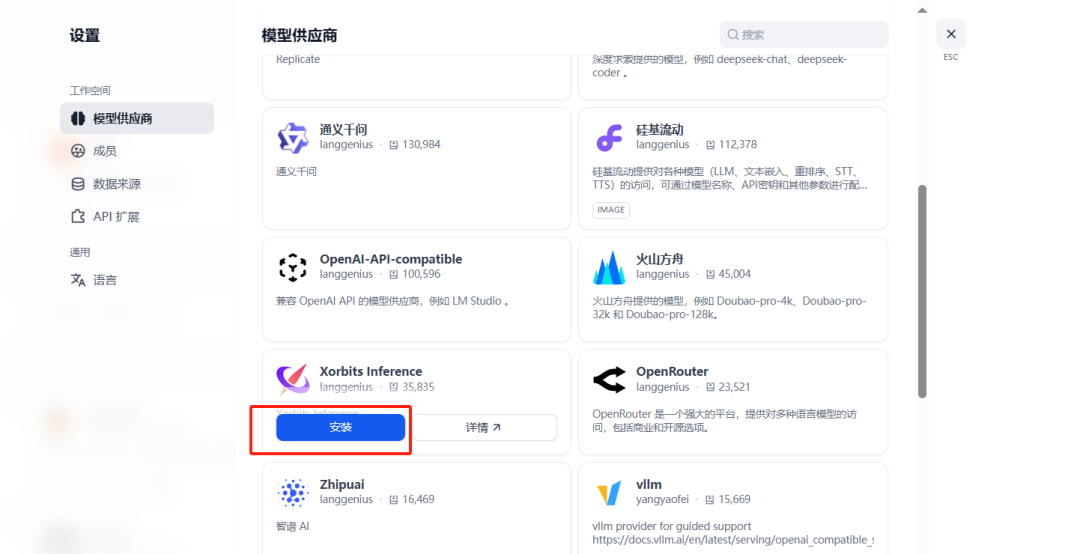
按照如下方法将Embedding模型和Reranker模型进行添加
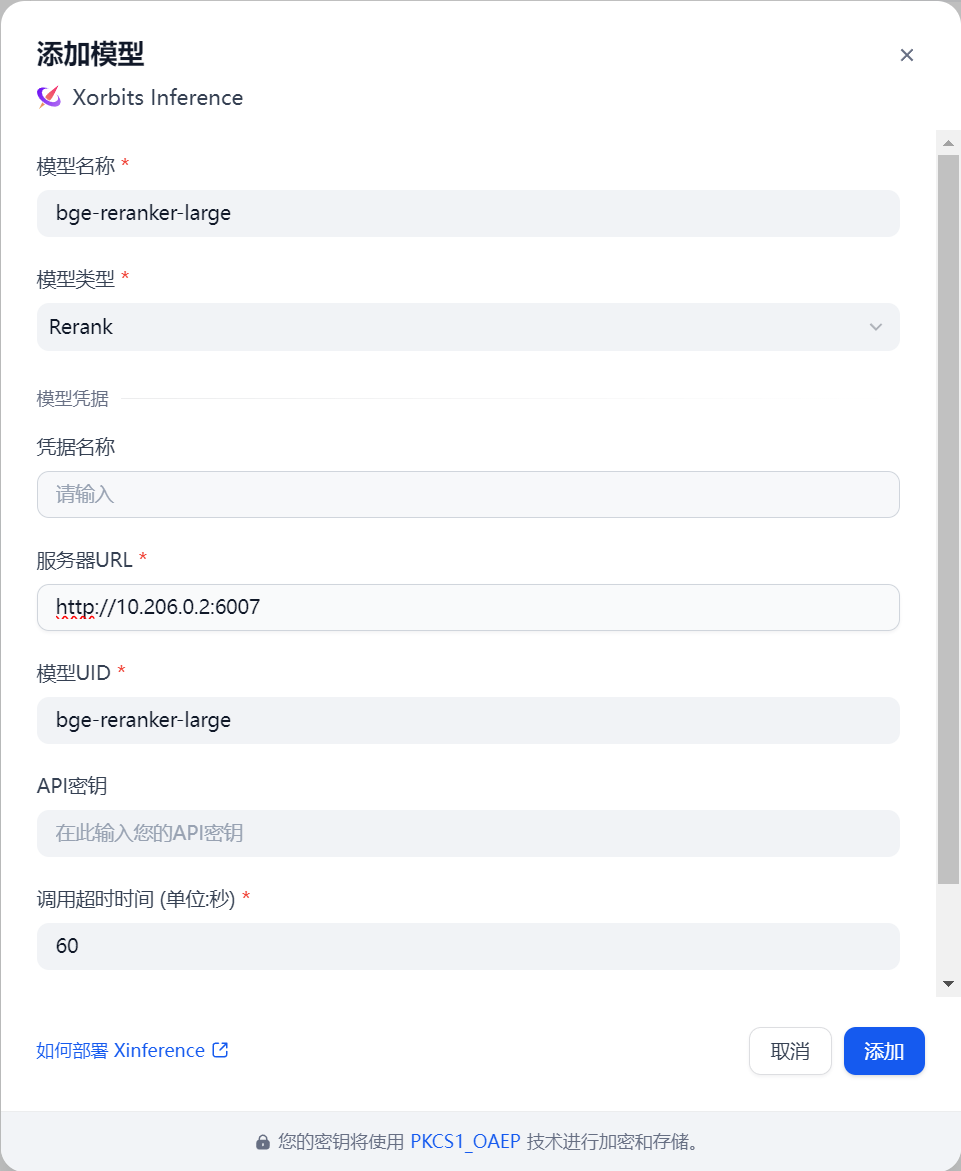
这里的名称和id要和Xinference平台的保持一致。地址使用http://[dify服务器的内网ip]:6007
添加成功:
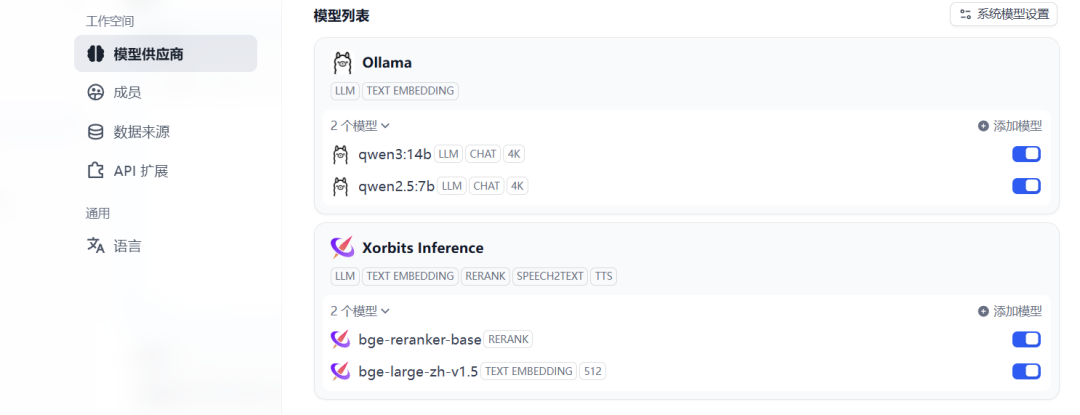
2.4 在线部署模式
截止目前,整体Dify就部署好了。如果是企业使用,需要按照我上面的逻辑操作。如果是个人使用,不考虑安全问题的话,使用Dify平台的在线LLM也可以。设置也可以使用在线的Dify平台。
如果想调用线上的LLM,则可以用Dify选择线上的模型运营商。比如说可以在模型运营商中选择Deepseek
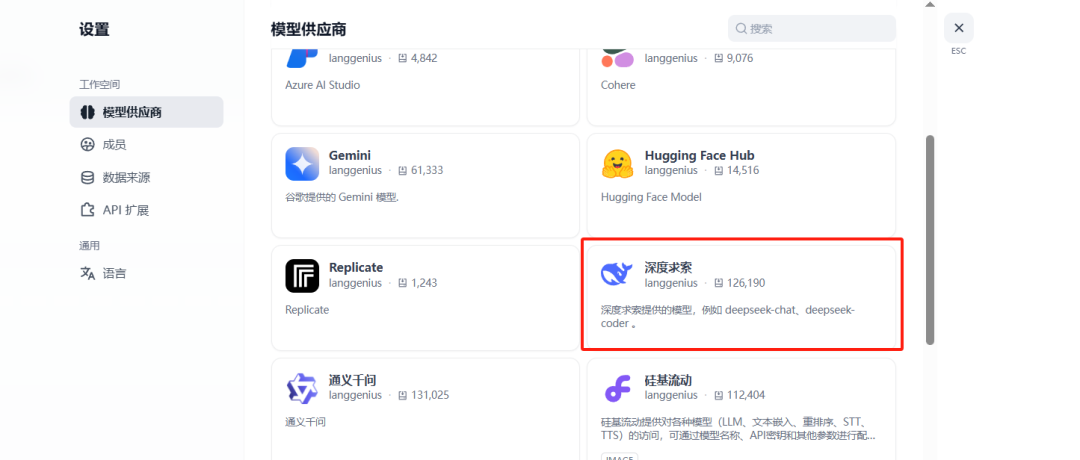
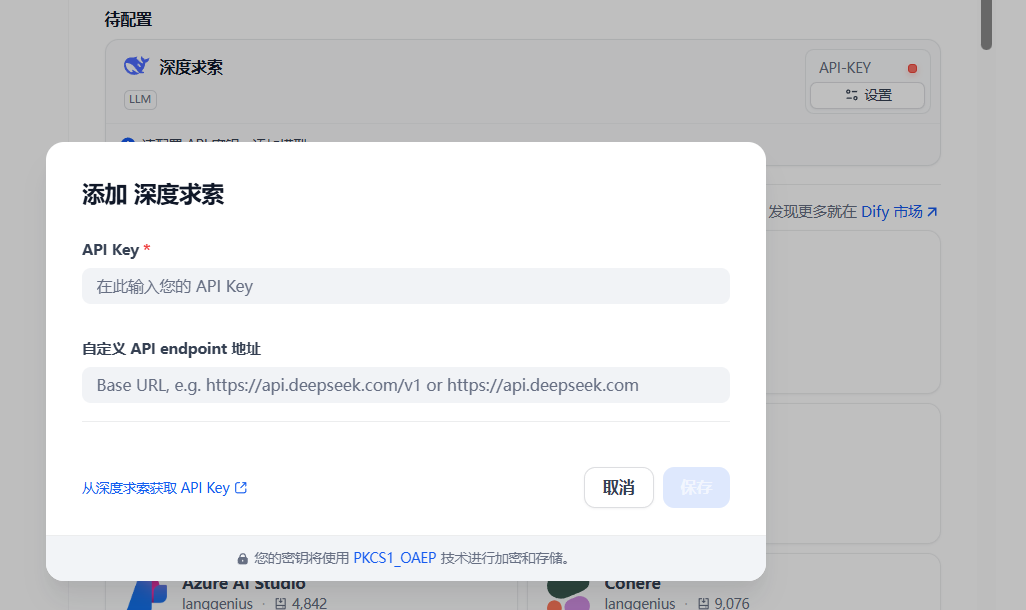
DeepSeek官网地址:
https://www.deepseek.com/
在官网获取自己的API即可配置后使用
如果是从CloseAI代理平台选择模型的话,选择这个插件

喘口气吧,有动手能力的,可以按照上面教程,自己动手实操一下
限时免费!优快云 大模型学习大礼包开放领取!
从入门到进阶,助你快速掌握核心技能!
资料目录
- AI大模型学习路线图
- 配套视频教程
- 大模型学习书籍
- AI大模型最新行业报告
- 大模型项目实战
- 面试题合集
👇👇扫码免费领取全部内容👇👇

📚 资源包核心内容一览:
1、 AI大模型学习路线图
- 成长路线图 & 学习规划: 科学系统的新手入门指南,避免走弯路,明确学习方向。

2、配套视频教程
- 根据学习路线配套的视频教程:涵盖核心知识板块,告别晦涩文字,快速理解重点难点。

课程精彩瞬间

3、大模型学习书籍

4、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

6、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









