



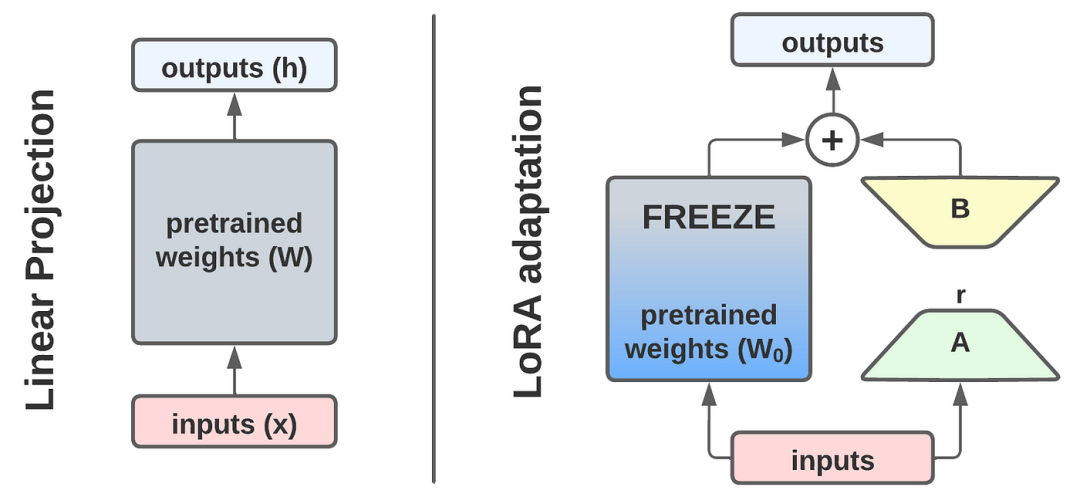
本文介绍传统大模型微调的高成本问题,以及LoRA技术如何通过低秩分解原理大幅降低微调成本。LoRA冻结原始模型,只训练两个小矩阵近似表示权重变化,降低显存占用和计算量。其三大技术创新包括梯度流动"开关设计"、缩放因子α和即插即拔"乐高积木"设计,使微调成本降低99%,部署更灵活,为企业节省大量资源。
(1)传统微调为什么让90%的团队直接放弃?
某创业公司想微调70B模型做客服,一算账直接懵了:
- 存储成本:每个任务存一份完整模型,280GB × 10个任务 = 2.8TB
- 训练成本:8张A100跑一周,2万美元起步
- 部署噩梦:切换任务要重新加载模型,用户等30秒
最终选择:放弃微调,直接用通用模型凑合。
(2)LoRA如何让微调成本暴降99%?
专业解释:模型微调时,权重变化矩阵通常是低秩的。
说人话:一个巨大的矩阵更新,其实可以用两个小矩阵相乘近似替代。
LoRA微调具体做法如下:
- 冻结原模型(175B参数一个不动)
- 只训练两个小矩阵 A 和 B(加起来几百万参数)
- 推理时:
输出 = 原权重 × 输入 + A × B × 输入
数学表达:rank r = 8时,参数量从 d×k 降到 (d+k)×8
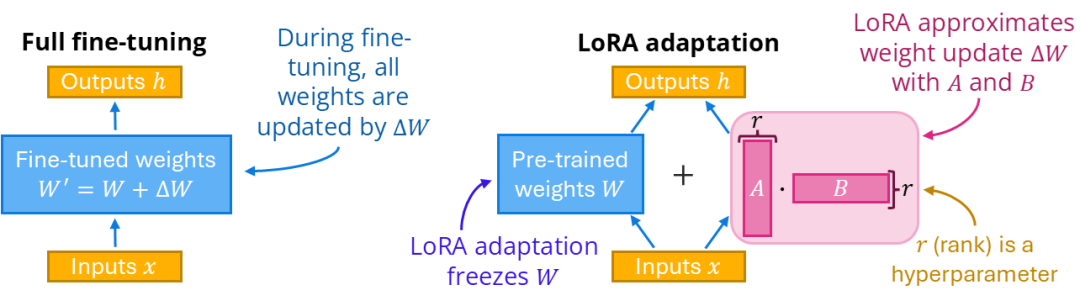
一、LoRA的低秩分解
核心数学原理是什么?什么是低秩分解?

想象你要搬家,有一堆大箱子要搬运。传统微调就像把每个箱子里的东西全倒出来重新整理,费时费力。而LoRA的做法更聪明:它发现大部分箱子其实不需要动,只需要在上面贴几张标签就够了。
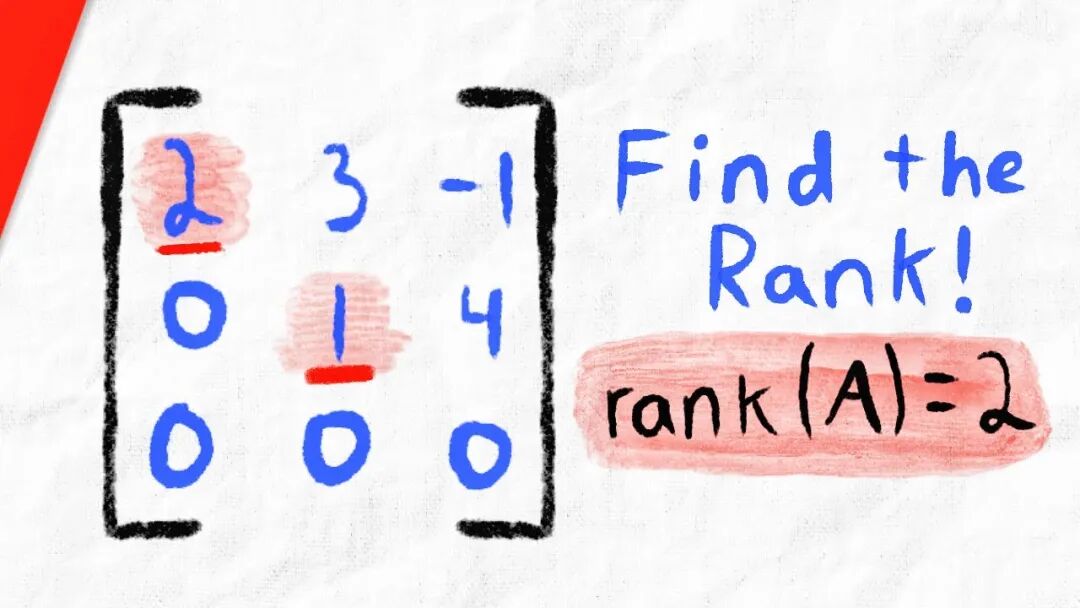
矩阵的秩是什么?
矩阵的秩(rank)是线性代数中的一个重要概念。简单来说,矩阵的秩是矩阵中线性无关的行(或列)的最大数目。假如你是一个老师,你的学生是一个团队。矩阵的秩,相当于这个团队的 “独立意见” 或 “独特技能” 的数量。
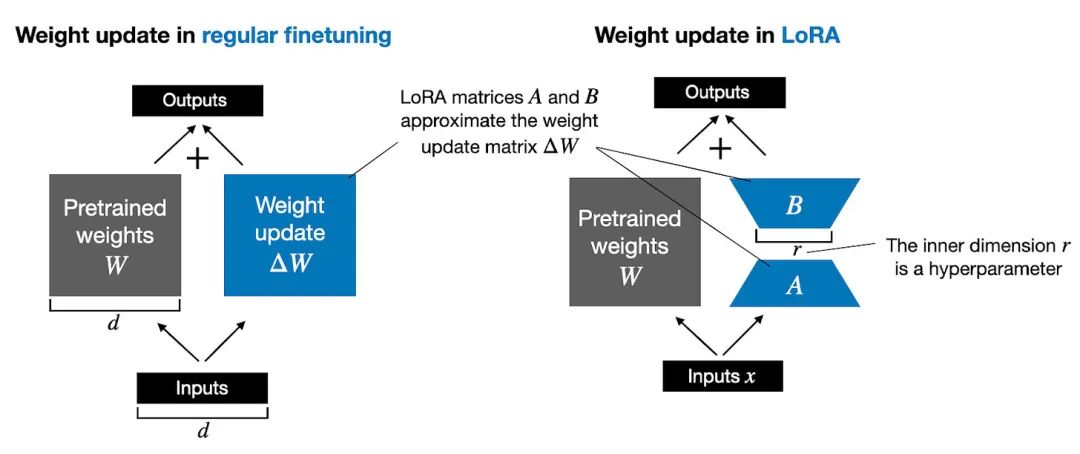
为什么低秩分解是信息的"压缩密码"?
在深度学习中,模型的每一层都是一个巨大的权重矩阵 W。比如一个典型的注意力层,W 可能是 4096×4096,包含1600万个参数。全量微调意味着要更新这1600万个数字。
但LoRA团队发现了一个惊人的事实:微调时,这个矩阵的变化量 ΔW 其实非常"规整"——用数学语言说,它是低秩的。
这样原本需要的更新:ΔW (4096×4096 = 16,777,216个参数),实际可以表示为:ΔW = A × B,其中A是4096×8的矩阵,B是8×4096的矩阵,参数总量:32,768 + 32,768 = 65,536个参数,LoRA低秩分解压缩比为256倍!
为什么微调的变化是低秩的?
(1)预训练已经打好了基础:就像一个学会了开车的人,再学开卡车,只需要掌握"方向盘更重"、"刹车距离更长"等几个关键差异,不需要重新学习什么是油门、刹车。
(2)微调任务的本质是少量调整:把通用语言模型改造成客服助手,本质上只是学会"更礼貌的表达"+“更结构化的回答”,这些改变都只用少量调整模型参数。
(3)丰富的实验数据支撑:研究人员测试了从 r=1 到 r=64 的不同秩值,发现 r=8 时就能恢复全量微调95%的效果。
这说明微调的有效信息确实集中在一个很小的子空间里。
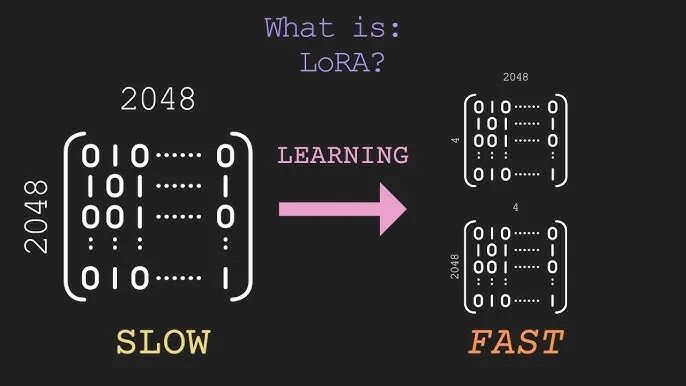
二、LoRA的技术创新
LoRA的技术创新是什么?
光有数学原理还不够,LoRA真正的工程价值在于三个技术创新。
创新1:梯度流动的"开关设计"——显存占用降低80%
传统微调像装修房子要把所有房间重新粉刷一遍,LoRA更聪明:只在墙上挂几幅画,原墙面一点不动。
具体来说,LoRA把原始权重W₀完全冻结,只让梯度流经新增的小矩阵B和A。反向传播时,原本需要为1600万个参数存储梯度,现在只需要为6.5万个参数存储,显存占用直接降低256倍。
这带来三个直接好处:(1)显存暴降让硬件成本大幅下降,(2)计算量减少让训练速度提升数倍,(3)小矩阵更稳定不易梯度爆炸。
某创业公司的案例:原本需要8张A100(12万美元)才能训练的70B模型,用LoRA后2张就够,硬件成本省75%。
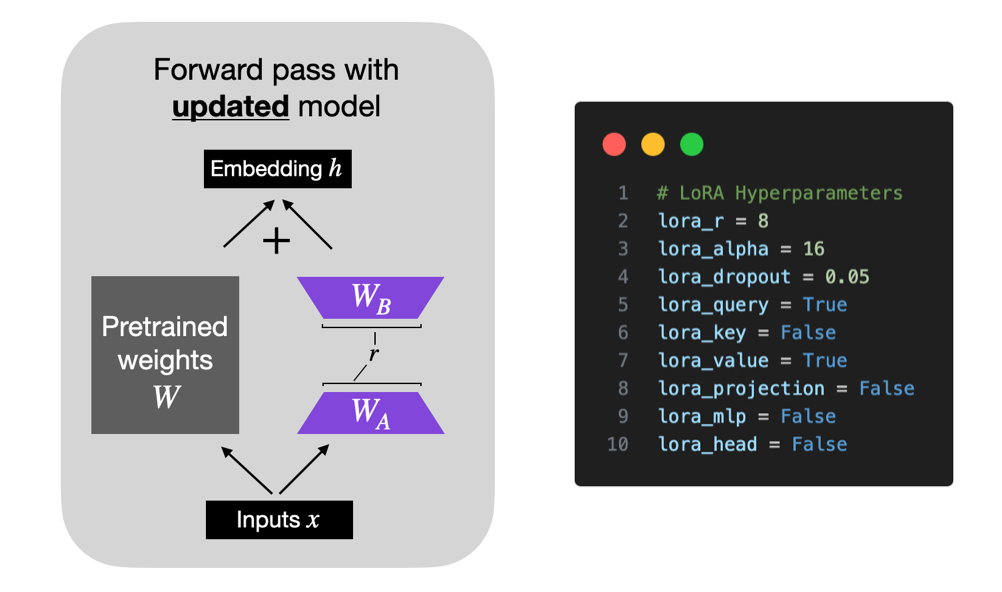
创新2:缩放因子α——让不同配置可以公平对比
LoRA在计算时会用缩放因子α除以秩r,形成最终更新量。
为什么需要这个?假设你用秩8训练效果刚好,现在想试试秩16会不会更好。
这时候问题来了:秩越大矩阵越大,同样学习率下更新力度越强,就像换了更大马力的发动机。这样不同秩的结果就没法公平对比了。α除以r就是为了归一化这个力度。

实战价值很直接:从秩8切换到秩16时不需要重新调参,不同配置的实验结果可以科学对比,小模型上的配置可以直接用到大模型。经验上α设为16或32最优。
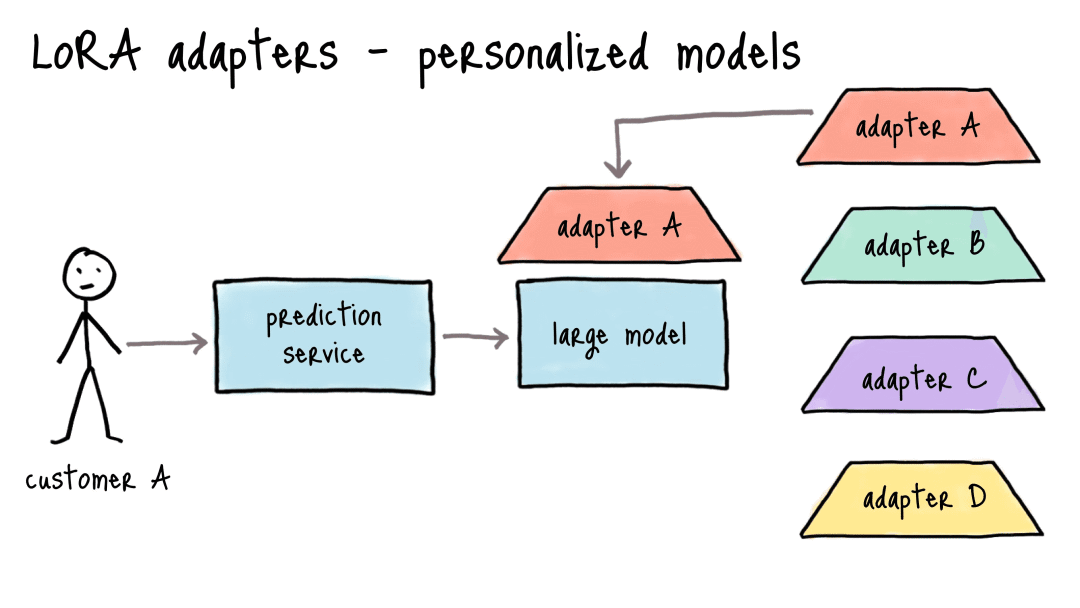
创新3:即插即拔的"乐高积木"设计——部署成本降低90%
这是LoRA最具商业价值的特性。看一个电商公司的真实案例:
需要为10个商品类目(服装、数码、美妆等)分别定制描述生成模型。传统方案下,每个类目存一个280GB完整模型,10个类目2.8TB存储,10个GPU实例部署,月成本28000美元。
改用LoRA后,只需一个280GB共享基座模型,加10个50MB小适配器。总存储280.5GB,1个GPU实例动态加载适配器,月成本2800美元,节省90%。
响应速度也有质的飞跃:传统方案切换类目要重新加载280GB模型,用户等30秒;LoRA只需换50MB适配器,等0.5秒。
回到最初的问题:为什么大厂都在用LoRA?
因为它用一个优雅的数学原理(低秩分解),解决了三个工程痛点:
(1)成本痛点:从"百万美元起步"到"千元也能玩"
(2)部署痛点:从"一个任务一个模型"到"一个基座配万千适配器"
(3)风险痛点:从"微调即遗忘"到"增量不覆盖"
日拱一卒,让大脑不断构建深度学习和大模型的神经网络连接。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


大模型入门到实战全套学习大礼包
1、大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

2、大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

3、AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

4、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

5、大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









