






大型语言模型 (LLM)(如 GPT-4)实际上并“不知道”任何东西,它们根据旧的训练数据预测单词。检索增强生成 (RAG) 改变了这一点,它让 AI 在回答问题之前提取新鲜的、真实世界的知识。
RAG 通过使 LLM 能够在生成响应之前从外部来源检索相关信息来增强 LLM。由于 LLM 依赖于静态训练数据并且不会自动更新,因此 RAG 使它们能够访问新鲜的、特定领域的或私有知识,而无需进行代价高昂的再训练。
让我们探讨一下 RAG 的工作原理、它的作用以及它与传统 LLM 提示有何不同。
什么是 AI 中的检索增强生成(RAG)?
检索增强生成 (RAG) 帮助 AI 模型在生成响应之前检索外部信息。但这个过程究竟是如何工作的,为什么它很重要呢?
大型语言模型在许多任务中表现出色。它们可以编写代码、起草电子邮件、幻觉出制作完美三明治的配料,甚至可以撰写文章,尽管我仍然更喜欢自己做。然而,它们有一个主要限制。它们缺乏实时知识。由于训练 LLM 是一个耗时的过程,因此它们并*“不知道”*最近发生的事件。如果你问它们上周发生了什么,它们要么显示免责声明,要么提供过时的答案,要么生成完全不准确的内容。
“一些 LLM 通过在响应之前检索最新信息来克服其陈旧训练数据的最大限制。”
RAG 在生成答案之前提取相关信息,从而使 AI 的响应更准确并减少幻觉。
简单来说 RAG
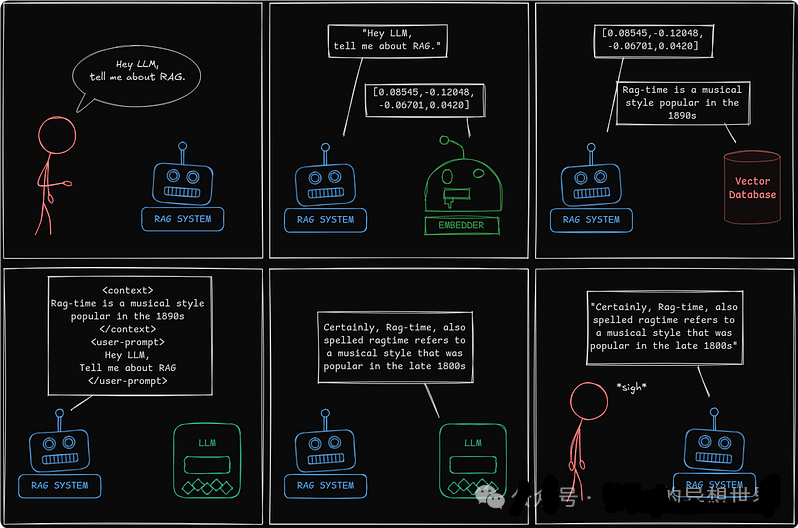
但 RAG 实际上是如何工作的呢?与其自己查找,不如问问我们最喜欢的 LLM:

来源:作者的图片。
这与我们希望的有点不一样。没问题,我们可以问 Bob。

来源:作者的图片。
令人惊讶的是,Bob 也不知道答案,但他能够检索到它。以下是发生的情况:
- \1. 我们问 Bob 关于 RAG 的问题。
- \2. Bob 去了图书馆,向图书管理员索要信息。
- \3. 图书管理员指引他到正确的通道。
- \4. Bob 检索了信息。
- \5. Bob 通过在生成答案之前获取信息来增强了他的理解。
- \6. 现在 Bob 听起来像个专家。谢谢,Bob。
这种分解表明 Bob 实际上充当了一个 RAG 代理。
有了这种见解,让我们确切地探讨一下 RAG 代理是如何运作的。
RAG — 简化
让我们将我们与 Bob 的互动转化为一个实际的 RAG 系统:
- • Bob 代表 RAG 系统。
- • 图书管理员充当 嵌入器。
- • 图书馆充当 向量数据库。
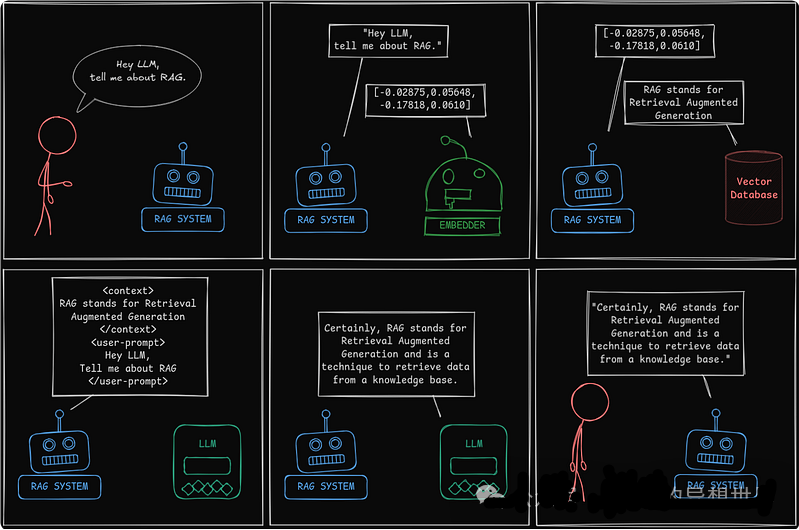
来源:作者的图片。
“RAG 系统不是直接提示 LLM,而是充当知识桥梁:检索、增强,然后生成响应。”
向量化输入
然后,RAG 系统 将提示转发给 嵌入器,嵌入器将其转换为一个 向量。这个 向量 是提示的数字表示。其想法是,具有相似含义的信息将具有相似的向量表示。
“向量释放了相关性。此向量允许系统从向量数据库中检索最有意义的信息。”
当用户提示的向量表示发送到数据库时,它会检索最相关的匹配项。
然后,RAG 系统 通过包含检索到的信息来增强用户提示:
<context>
the information returned from the database
</context>
<user-prompt>
the user's original prompt
</user-prompt>
这就是整个过程。检索、增强和生成。RAG。
添加到知识库
但是,如果系统中没有添加信息,则系统无法检索信息。我们如何存储新数据?这个过程很简单。系统不是使用向量来查找相关信息,而是存储数据及其向量表示。
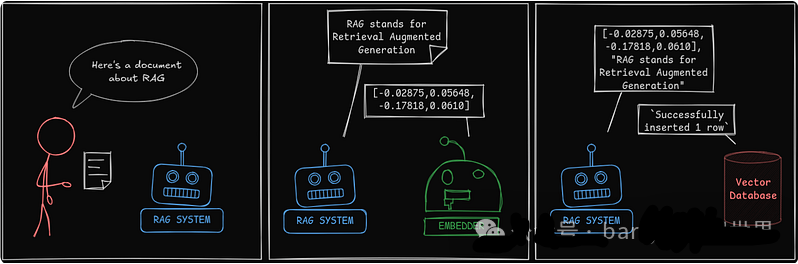
来源:作者的图片。
如果你只对大方向感兴趣,恭喜你。你现在理解了核心概念。但是,如果你也是一个“技术宅”,让我们再多谈谈向量和嵌入器。
什么是向量?
简单来说,向量是一组坐标,描述了如何从 A 移动到 B。看看这张图:
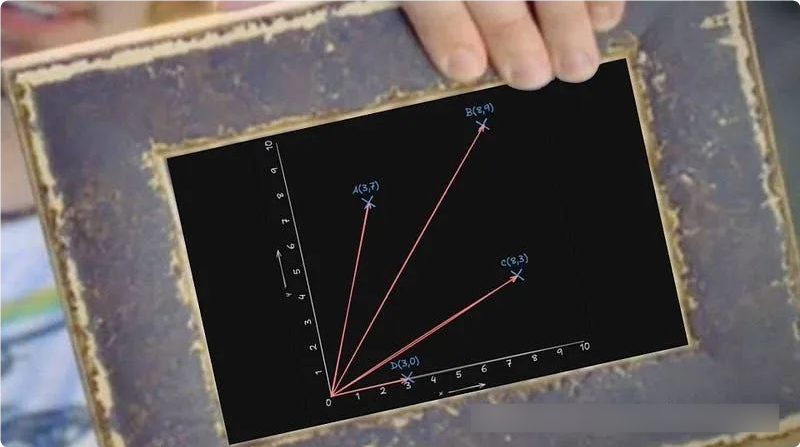
来源:Nickelback 音乐视频“Photograph”的静止画面,由作者使用自定义图表叠加编辑。
这张图有两个维度。每个点,A、B、C 和 D,都可以使用一个两位数的坐标系来描述。第一个数字告诉我们从原点 (0) 向右移动多远,而第二个数字告诉我们向上移动多远。要到达 A,向量为 [3, 7]。要到达 D,向量为 [3, 0]。
向量的维度
同样的原理也适用于三个维度。要从你的办公桌移动到咖啡机,你必须沿 x、y 和 z 轴移动一定的距离,形成一个三位数坐标系。
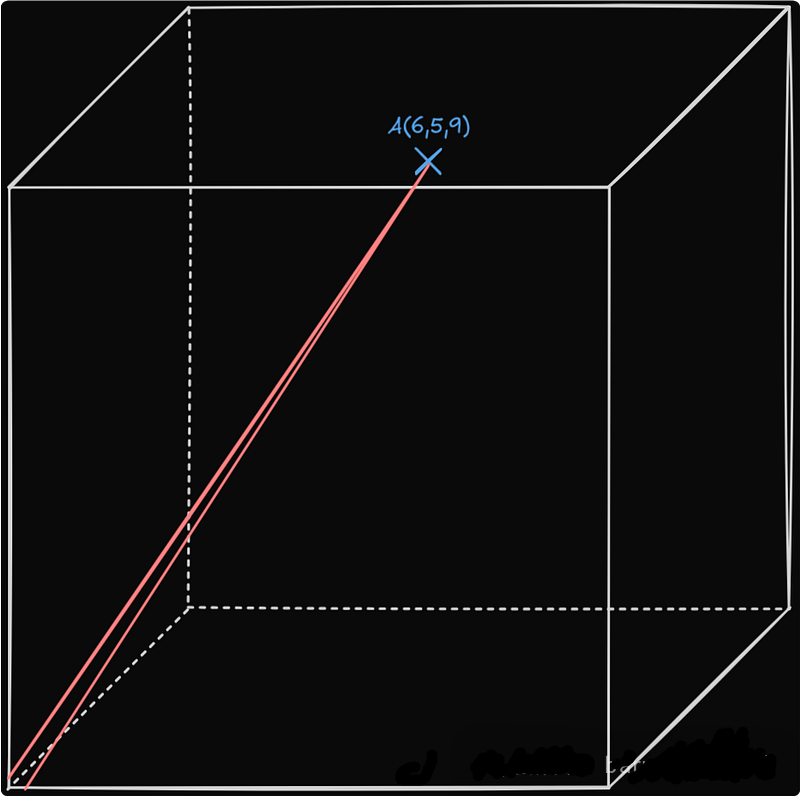
来源:作者的图片。
“人类难以想象超过三个维度。计算机在多维空间中蓬勃发展。”
数学保持不变。四个维度?这需要一个四位数坐标系。一百个维度?这需要一个100 位数的坐标系。

来源:Meme remix,结合了 KC Green 的“This is Fine”(原版)和作者的自定义艺术品。
“我使用的嵌入器在一个令人难以置信的 768 维坐标系中运行,远远超出了人类的感知。”
当你完成尝试可视化之后,我们可以回到更简单、易于绘制的二维图。
向量嵌入如何帮助 LLM 检索数据
向量本身只是代表n 维空间中点的n 维坐标。
“向量不仅仅是数字,它们编码了含义。它们真正的力量在于它们所代表的信息。”
同样,向量是坐标,但不是指向位置,而是指向信息。一个专门的 LLM,即一个嵌入器,在一个大型文本语料库上进行训练,以找出相似之处,并将这些信息放置在n 维空间的某个地方,以便将相似的主题分组在一起。
就像,当你参加社交活动时,你可能会和你的朋友、同事,或者至少是一群志同道合的人在一起。
将相似的概念分组在一起
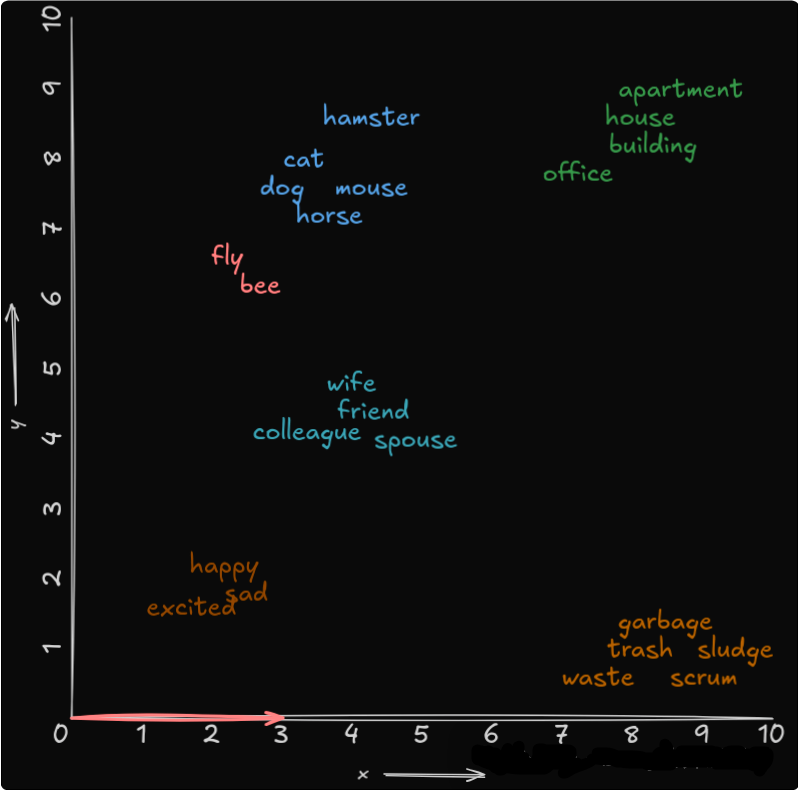
来源:作者的图片。
这张图显示了含义相似的单词是如何在这个 n 维空间中分组在一起的。现代嵌入器(如 BERT)不再使用单字嵌入,而是生成上下文嵌入。
在向量空间中对相似概念进行分组的能力使嵌入变得强大。然而,早期的嵌入模型(如Word2Vec)有一个显著的局限性,现代模型已经解决了这个问题。
快速技术切入
如果你像我一样一直在研究 AI 系统,你可能熟悉 Word2Vec。虽然它在 2013 年问世时具有开创性意义,但它有一个主要缺陷:它为每个单词分配一个单一向量,而不管上下文如何。
以单词 “bat” 为例。
- • 我们是在谈论飞行动物吗?那么它应该靠近*“mammal”、“cave”和“nocturnal”*。
- • 或者我们指的是棒球棒吗?那么它属于*“ball”、“pitch”和“base”附近(但什么base*?军事基地?)
- • 如果我们身处虚构的世界呢?那么*“bat”就与“vampire”和“transformation”*有关。
Word2Vec 无法区分。它选择一个并坚持下去。
我发现 Word2Vec 特别有趣的一点是,由于单词现在由数字表示,你实际上可以对它们进行算术运算。
你可以写出这样的方程式
“king - man + woman = queen- 一个关于 AI 模型如何在向量空间中映射关系的传奇例子。”
这很疯狂,但它有效(大多数时候)。
切入结束。
向量是如何使用的?
既然我们理解了向量,下一步就简单了。我们嵌入我们希望 LLM 访问的信息,当我们询问有关该信息的问题时,问题本身应该与向量空间中的相关内容接近。向量数据库检索 n 个最相关的内容,其中 n 是一个可配置的数字。
它还返回每个结果的 cosine similarity 分数,表明检索到的内容与查询的匹配程度。
余弦相似度
“余弦相似度不仅仅是比较数字,它通过计算两个向量之间的夹角来衡量 meaning 。”
较小的角度表示相似度更高,这意味着检索到的数据与提示更相关。
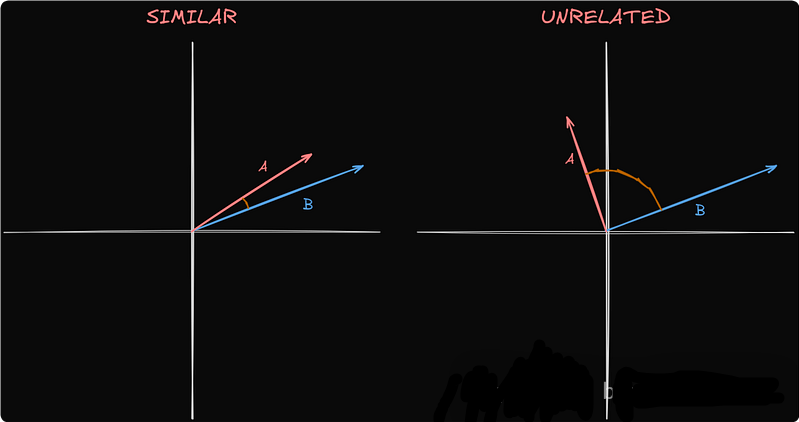
来源:作者的图片。
在我们的例子中,A和B分别代表短语*“RAG 代表检索增强生成”和“嘿 LLM,告诉我关于 RAG 的信息”。由于它们密切相关,它们的向量是相似的。如果我们改为询问“描述一次日食”,它的向量将与其他向量相距甚远,使其不相关。但是,如果“RAG 代表检索增强生成”*是数据库中的唯一条目,它仍然会被检索,即使它与查询不相关。
RAG 的局限性
通常,我们不会在向量数据库中存储和检索整个文档。如果这样做,单个大型文档很容易超过 LLM 的上下文窗口。如果系统配置为返回十个最相关的信息,并且每个信息的大小都相当于一整篇文章,那么你的计算机很快就会变成一个空间加热器。为了防止这种情况,我们将信息分成预定义大小的块,例如 1000 个字符,并尝试保持句子和段落的完整性。
然而,将信息分割成块会引入一个新问题。就像Word2Vec难以从单个单词中确定含义一样,RAG 经常无法理解单个块的完整上下文,尤其是在该块是从文档中间提取的时候。
来源:作者的图片。
这是我最近遇到的一个问题。我保留了一个详细的工作日记,我在其中记录了我所有的专业成就。这在绩效评估期间非常有用。但是,当我问我的 RAG 系统我在目前的公司取得了什么成就时,它自信地包含了我在以前的工作中所取得的成就。因为我用第一人称写这个日记,并且还包括了来自其他用第一人称写成的来源的信息,所以系统无法区分它们。因此,它开始将成就归功于我,而我与这些成就毫无关系。这就是我意识到出了问题的方式。我的系统突然告诉我所有我应该在电脑之外做的有趣的事情,这根本不可能,因为我从未离开过我的办公桌。
结论
RAG 通过让 LLM 检索它们无法访问的信息,使它们更有用。但它不是魔术。它有自己的挑战,从正确处理上下文到避免不相关的结果。
但正如我亲身体验的那样,获取信息与理解信息是不同的。这就是为什么使 RAG 系统具有上下文感知能力是下一个巨大的挑战。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









