



Bert模型自2018年问世至今,在自然语言处理、多模态技术上显示出强大的实力,在金融领域中的文本理解、知识图谱等领域也显示出强大的应用前景。本文介绍如何在金融文本中微调自己的Bert模型,并进行精简,进而自动生成新闻因子,供下游预测任务使用。相关模型、数据集以及代码见文末分享。
金融新闻数据采集
推特、WSJ、联合早报、财联社等新闻具有较高的利用价值,这里主要介绍财联社的新闻数据获取方法。
打开网址:https://www.cls.cn/telegraph, 在chrome浏览器中按下F12键,点击Network,然后刷新一下网页,便能找到后端请求的资源:
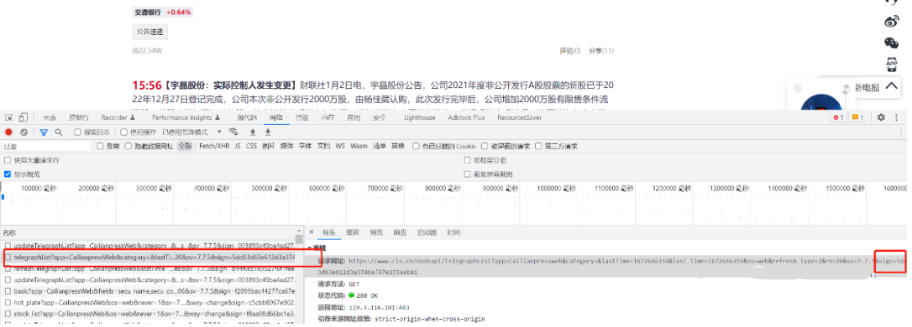
这里比较重要的是请求资源实际进行了简单加密,导致修改了时间参数后无法正常访问。以截图中的为例,需要使用hashlib进行sign签名的编码,具体代码如下:
import hashlib
def _md5(data):
return hashlib.md5(data.encode()).hexdigest()
def _sha1(data):
return hashlib.sha1(data.encode()).hexdigest()
def get_sign(data):
data = _sha1(data)
data = _md5(data)
return data
data = 'app=CailianpressWeb&category=&lastTime=1672646359&last_time=1672646359&os=web&refresh_type=1&rn=20&sv=7.7.5'
url = 'https://www.cls.cn/nodeapi/telegraphList?' + data + "&sign=" + get_sign(data)
assert(get_sign(data) == "5dd63d63e612d3a3746ef97e233aeb41")
解决上面的签名问题后,便可以按照普通爬虫的方式,填充header等字段,获取任意时间段内的20条新闻数据了,并传入时间参数补齐历史数据:
import requests, time, datetime
def get_cls_data(timestamp=None):
if timestamp is None:
timestamp = int(time.time())
else:
timestamp = int(timestamp)
headers = {"Content-Type": "application/json;charset=utf-8", "Referer": "https://www.cls.cn/telegraph", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"}
data = 'app=CailianpressWeb&category=&lastTime={}&last_time={}&os=web&refresh_type=1&rn=20&sv=7.7.5'.format(timestamp, timestamp)
url = 'https://www.cls.cn/nodeapi/telegraphList?' + data + "&sign=" + get_sign(data)
resp = requests.get(url, headers=headers)
return resp.json()
print(get_cls_data(timestamp=datetime.datetime.fromisoformat('2023-01-01 00:00:00').timestamp()))
Bert模型微调
目前开源出来的中文金融领域预训练模型有:
•熵简科技FinBERT: https://github.com/valuesimplex/FinBERT, 国内首个在金融领域大规模语料上训练的开源中文BERT预训练模型•澜舟科技Mengzi: https://github.com/Langboat/Mengzi, 金融领域的自然语言理解类任务
这里我们在Mengzi模型上进行进一步的微调:
•下载模型至本地:https://huggingface.co/Langboat/mengzi-bert-base-fin/tree/main ,加载到SentenceTransformer框架中,见代码load_model模块•载入金融文本数据集:每行一个新闻文本,见代码load_sentence模块•训练BERT模型:见代码train模块,TSDAE相比MLM、SimCSE等无监督任务效果更优(https://www.sbert.net/examples/unsupervised_learning/README.html)
# 载入预训练好的模型
def load_model(model_name='Langboat/mengzi-bert-base-fin', max_seq_length=128):
word_embedding_model = models.Transformer(model_name, max_seq_length=max_seq_length)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), 'mean')
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
return model
# 载入我们自己的数据集,每行一个文本
def load_sentence(filepath=''):
sentences = []
with open(filepath, encoding='utf8') as fIn:
for line in tqdm(fIn, desc='Read file'):
line = line.strip()
if len(line) >= 8:
sentences.append(line)
return sentences
# 训练TSDAE模型
def train(news_txt="news.txt", model_location="Langboat/mengzi-bert-base-fin", model_output_path= 'tsdae'):
model = load_model(model_name=model_location)
sentences = load_sentence(filepath=news_txt)
train_dataset = datasets.DenoisingAutoEncoderDataset(sentences)
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True, drop_last=True, num_workers=16)
train_loss = losses.DenoisingAutoEncoderLoss(model, decoder_name_or_path=model_location, tie_encoder_decoder=True)
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=10,
weight_decay=0,
scheduler='constantlr',
optimizer_params={'lr': 4e-5},
show_progress_bar=True,
checkpoint_path=model_output_path,
use_amp=True,
checkpoint_save_steps=5000
)
Bert模型降维
Bert原生的输出维度为768,复杂度略高,最新的研究表明,借助Bert-whitening思路,可以在少量精度损失的情况下,使用降维技术获得更精简的句向量表达。基本的思路是,对所要编码的句子文本,首先编码成bert句向量,然后使用PCA进行降维,获取转换权重,然后把这权重嫁接到原始Bert的输出层上,这样我们就能直接获取简化后的Bert输出了,代码如下:
def pca(file="cls.txt", new_dimension = 128):
sentences = load_sentence(filepath=file)
random.shuffle(sentences)
model = SentenceTransformer('./tsdae')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
embeddings = model.encode(sentences, convert_to_numpy=True, show_progress_bar=True)
pca = PCA(n_components=new_dimension)
pca.fit(embeddings)
pca_comp = np.asarray(pca.components_)
dense = models.Dense(in_features=model.get_sentence_embedding_dimension(), out_features=new_dimension, bias=False, activation_function=torch.nn.Identity())
dense.linear.weight = torch.nn.Parameter(torch.tensor(pca_comp))
model.add_module('dense', dense)
model.save('tsdae-pca-128')
下游任务应用
微调和降维后,我们便可以利用其理解能力对任意一段文本进行编码,输出固定维度的向量:
bert_encoder = SentenceTransformer(bert_dir, device=device)
titles = ['中国银行黑龙江省分行原党委委员、副行长陈枫接受纪律审查和监察调查', '银河电子:签署储能业务战略合作协议']
embeddings = bert_encoder.encode(titles, convert_to_numpy=True, show_progress_bar=True)
print(embeddings.shape)
进一步的,如果我们想对一批新闻建模,那么可以把这些句向量当做一个个单词,利用长序列transformer技术进行进一步的编码,然后取pooling层输出作为新闻因子。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 1651
1651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









