



01、本地大模型越来越简单
经过了一年多时间的迭代,大模型种类繁多,使用也越来越简单了。
在本地跑大模型,个人认为目前最好的软件肯定是Ollama无疑了,
不管你是在PC上跑大模型,在Mac上跑大模型,还有在树莓派上跑大模型,
我们都可以用Ollama去跑各种大大小小的模型,而且它的扩展性非常强。
02、Ollama本地运行大模型
现在安装Ollama超级简单的,只需要进入Ollama官网下载安装包,然后安装即可。
以下是我个人安装为例(macOS系统):
- 1、下载

- 2、安装
直接点击Next:
- 3、命令查看

- 4、运行

- 其他说明
如果自己不确定模型名称可以去官网查看模型

每款大模型都有不同版本,根据自己的机器来选择,根据官网的文档也说明了,一般7B的模型至少需要8G的内存,13B的模型至少需要16G内存,70B的模型至少需要64G内存。

03、使用Web UI界面连接Ollama
ollama没有界面化的页面使用,它是在终端里交互的,所有我们要使用图形化的界面里去操作,这是我们可以使用Open WebUI。
Open WebUI是一个开源的Web UI界面,github地址:github.com/open-webui/…
- 1、下载和运行
使用Docker方式运行Open WebUI,直接一条命令解决下载和运行:

bash复制代码docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
命令解释:
-d:后台运行-p 3000:8080:将容器的8080端口映射到主机的3000端口--add-host=host.docker.internal:host-gateway:添加主机映射,用于访问主机的Docker容器-v open-webui:/app/backend/data:将主机的open-webui目录映射到容器的/app/backend/data目录--name open-webui:设置容器名称--restart always:设置容器总是重启ghcr.io/open-webui/open-webui:main:镜像地址
启动日志:

注意:open-webui启动时有点慢,需要等待一会。可以通过docker logs open-webui查看日志。红框的可以不用理会。
- 2、注册
第一次使用时需要进行注册,这个数据都是本地存储。

- 3、登录

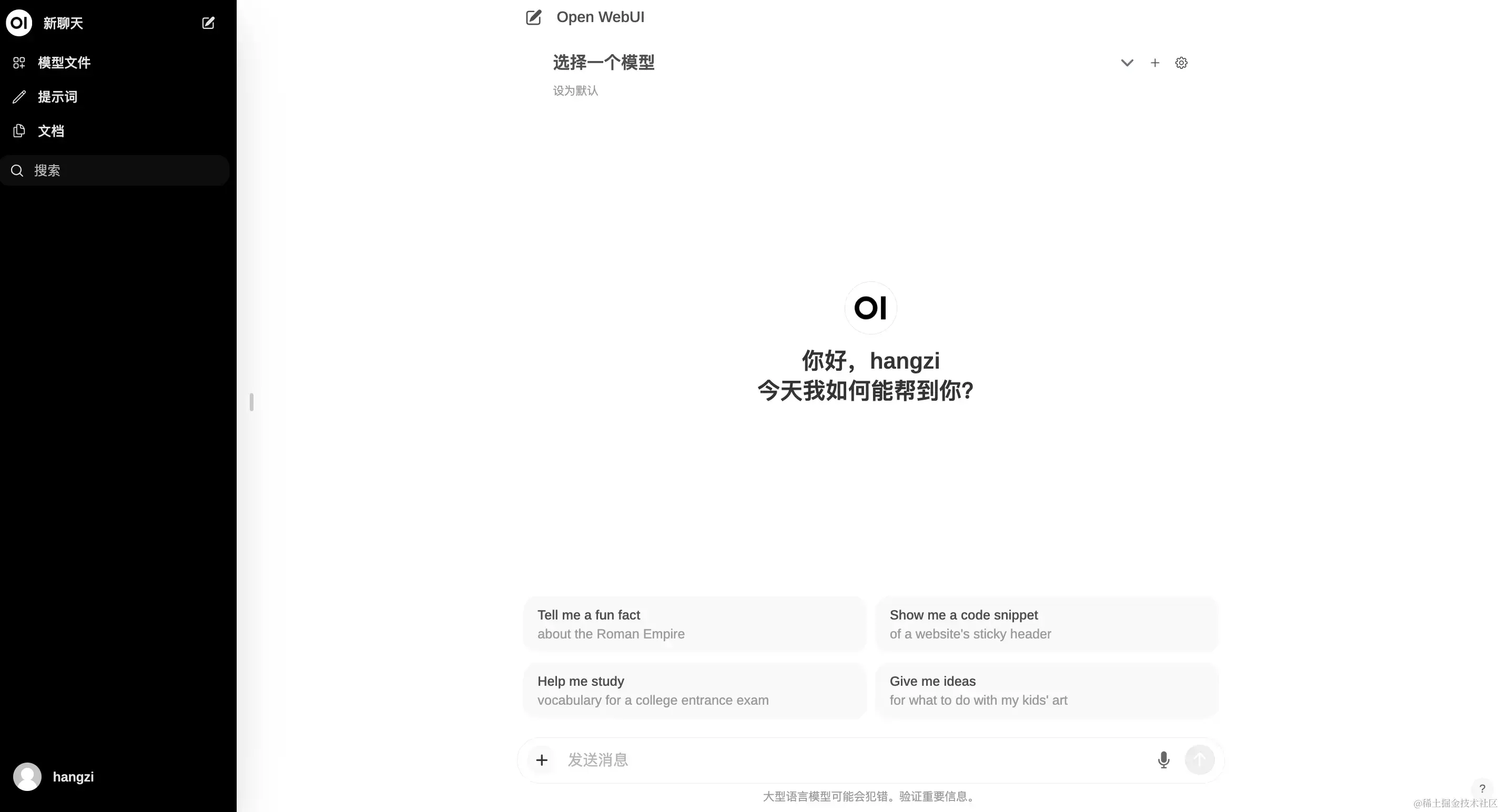
- 4、open-webui使用界面
- 4、设置

- 5、模型选择

04、本地化知识库
1、open-webui界面文档设置

2、加载网页或者文档
在对话窗口通过#+链接加载网页,通过对话框的+上传文件,也可以在文档中导入。

如果对知识库有更高的需求,可以使用AnythingLLM这个软件,github地址:github.com/Mintplex-La…

















 9119
9119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









