



前言
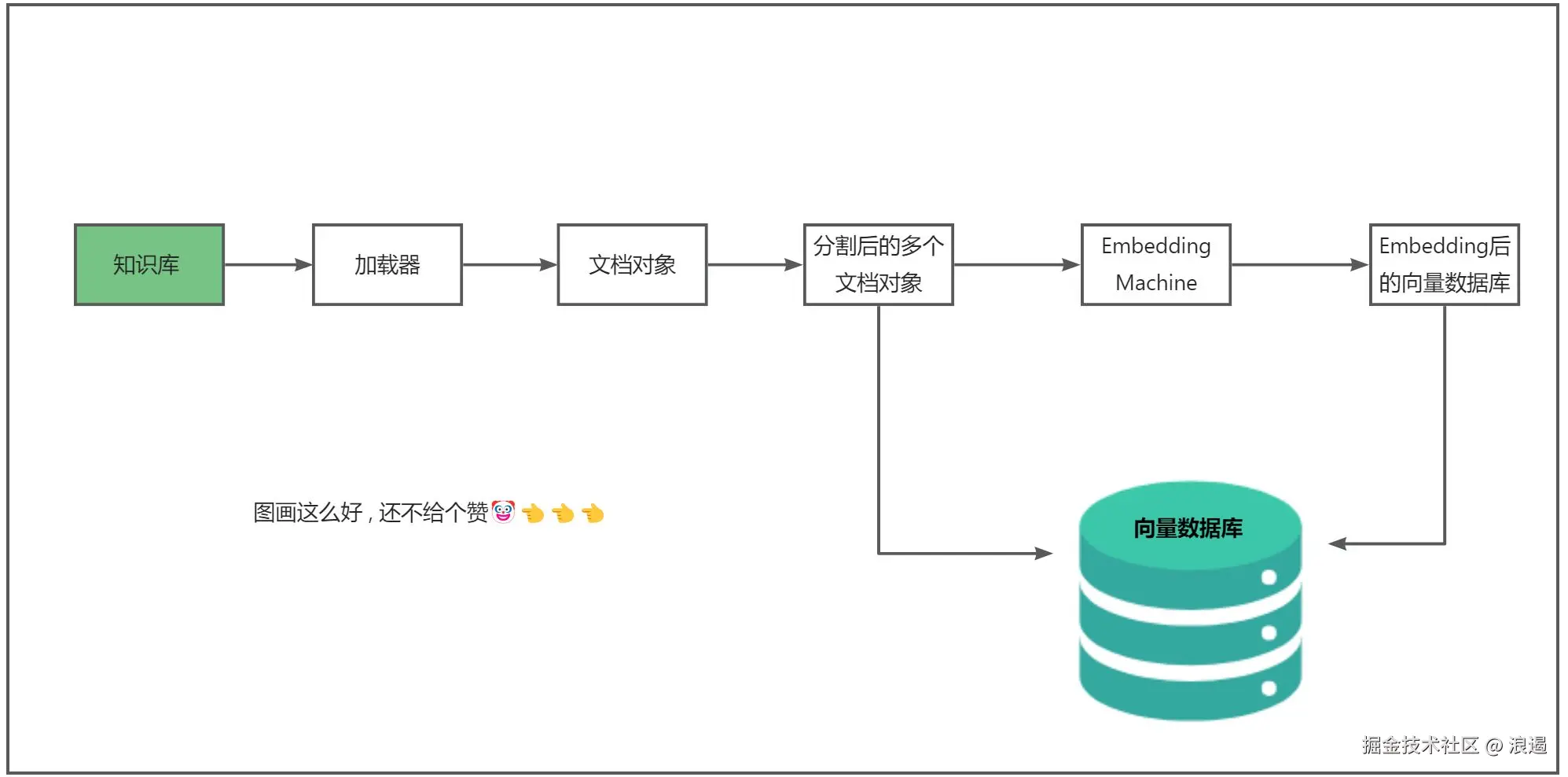
学习了 Memory 机制 , 回顾所学 RAG , 总结起来还是下面这张图 ,
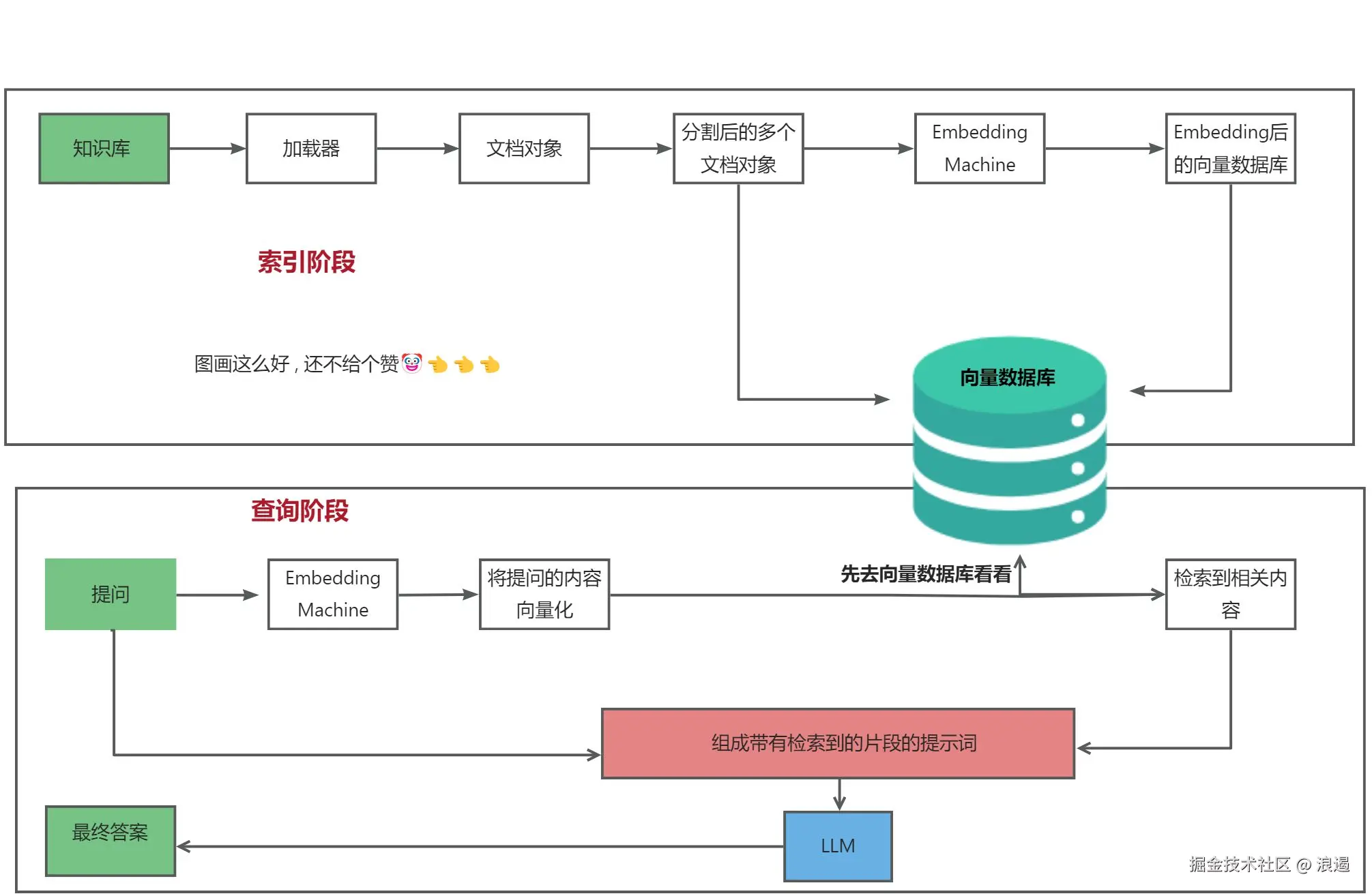
现在可以初步实现一个小型的 ,基于 RAG 的全栈项目 , 由于我在家无聊 , 和上小学的妹妹一起玩耍🤡👈 , 突发奇想做了一个只能根据知识库回答的 AI 助手 我做了一下限制 :
以下是知识库中跟用户回答相关的内容: {context}
你是一个把小学所有故事都背完了的小学生,精通根据故事原文详细解释和回答问题,你在回答时会引用知识库中的作品原文。 并且回答时仅根据原文,尽可能回答用户问题, 请仔细阅读知识库,时间很充足,你必须做到精准把握知识库中的内容 , 之后根据下面规则
1.如果用户的问题${question}与{context}有关,但是知识库中没有相关的内容,你就回答“原文中没有相关内容,我是小学生,知识有限”。
2.如果用户的问题${question}与{context}无关,但是知识库中没有相关的内容,你就回答“我是小学生,知识有限,你的问题超出了我的想象”。
3.如果用户的问题 q u e s t i o n 与 c o n t e x t 有关 , 并且知识库中有相关的内容,根据用户问题 {question}与{context}有关,并且知识库中有相关的内容,根据用户问题 question与context有关,并且知识库中有相关的内容,根据用户问题{question}引用{context}回答。
所以出现以下“我是小学生,知识有限,你的问题超出了我的想象”回复
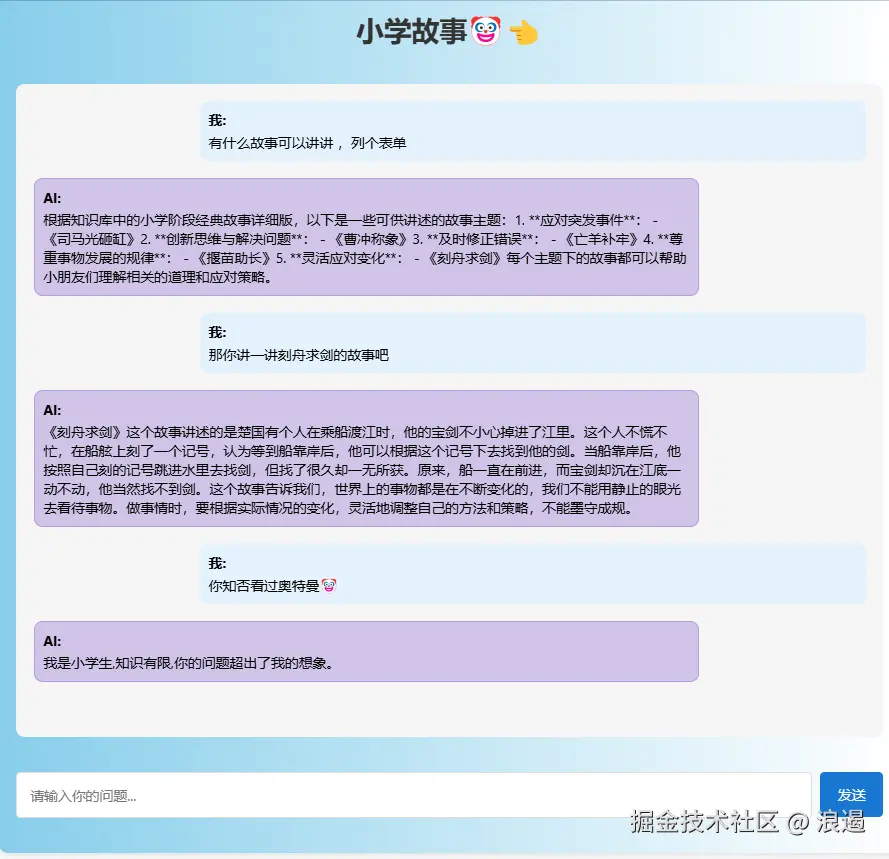
上述的"只能"看起来很鸡肋 , 为什么要限制呢 ? AI 助手越知识渊博不是跟好吗 ?
这个场景下 , 确实很鸡肋 , 我只是想以该场景为载体 , 将 RAG 理论初步变为现实 .
再实际生产中 , 我们有必要对 LLM 进行限制 , 比如不能让 LLM 说出令人“道德沦丧”的话 ;基于公司私有数据回答问题 (由于 LLM 不可能对私有数据训练 ,问它不知道的东西 ,就会胡言乱语 ,即出现幻觉) 。。。
好吧 ,开始实战如下效果 ~
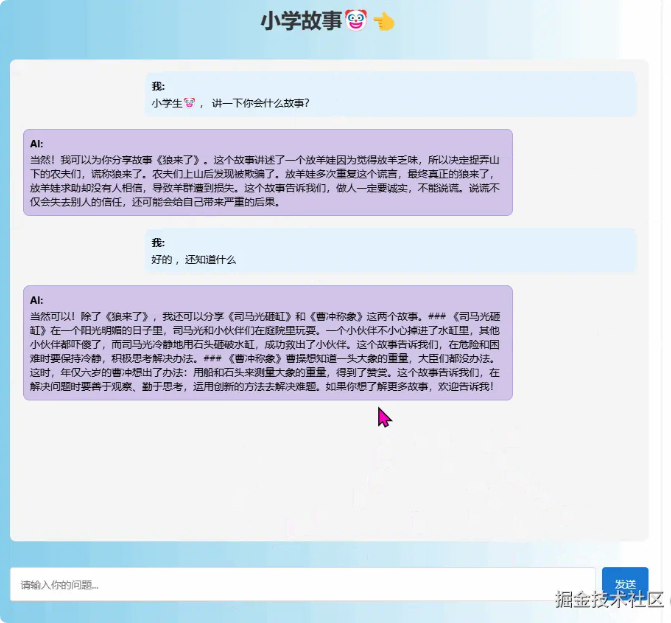
定位
项目主要实现 RAG 私有数据问答, 只回答我提供的数据 , 这是项目的核心 , 重点在于如何实现 RAG 流程 。
思路
开发时先写后端 , 在写前端 , 而我的文章从前端到后端展现
前端
- 切图
- 数据驱动
- 创建支持
EventSource对象SSE 实现流式响应
package.json
html体验AI代码助手代码解读复制代码{
"name": "frontend",
"private": true,
"version": "0.0.0",
"type": "module",
"scripts": {
"dev": "vite",
"build": "vite build",
"preview": "vite preview"
},
"dependencies": {
"axios": "^1.7.9",
"vue": "^3.5.13",
"vue-router": "^4.5.0"
},
"devDependencies": {
"@vitejs/plugin-vue": "^5.2.1",
"vite": "^6.0.5"
}
}
后端
基于 node.js 、express、Langchain.js 实现
- 文档加载 、切割、向量化、持久化
- 写 prompt 、检索、Outputparser、chain
- 解决跨域问题、实现 SSE 流式输出
package.json
html体验AI代码助手代码解读复制代码{
"name": "test-app-node",
"private": true,
"version": "0.0.0",
"scripts": {
"prepare-data": "node ./rag/prepare-data.mjs",
"rag-2": "node ./rag/index.mjs",
"rag-server": "node ./server.mjs",
"rag-client": "node ./client.mjs"
},
"type": "module",
"dependencies": {
"axios": "^1.7.9",
"cors": "^2.8.5",
"dotenv": "^16.4.7",
"express": "^4.21.2",
"faiss-node": "^0.5.1",
"langchain": "^0.1.30",
"multer": "^1.4.5-lts.1"
},
"main": "index.js",
"keywords": [],
"author": "",
"license": "ISC",
"description": ""
}
实战
切图
- App 中开始切图(只有一个页面🤡) :
创建一个容器
html体验AI代码助手代码解读复制代码<template>
<div class="chat-container">
</div>
</template>
切头部
html体验AI代码助手代码解读复制代码<!-- 聊天头部 -->
<div class="chat-header">
<h1>小学故事🤡👈</h1>
</div>
切聊天区
html体验AI代码助手代码解读复制代码<!-- 聊天消息显示区域 -->
<div class="chat-messages" ref="messageContainer">
<!-- 循环显示每条消息 -->
<div v-for="(message, index) in messages" :key="index" :class="['message', message.type]">
<div class="message-content">
<!-- 显示消息类型和内容 -->
<strong>{{ message.type === 'human' ? '我' : 'AI' }}:</strong>
<p>{{ message.content }}</p>
</div>
</div>
<!-- 如果正在流式传输,则显示当前AI响应 -->
<div v-if="streaming" class="message ai">
<div class="message-content">
<strong>AI:</strong>
<p>{{ currentResponse }}</p>
</div>
</div>
</div>
切表单
html体验AI代码助手代码解读复制代码<!-- 用户发送问题的输入表单 -->
<div class="chat-input">
<form @submit.prevent="sendQuestion" class="input-form">
<!-- 用户问题的输入框 -->
<input v-model="question" placeholder="请输入你的问题..." :disabled="streaming" required />
<!-- 提交按钮 -->
<button type="submit" :disabled="streaming">
{{ streaming ? '等待回答中...' : '发送' }}
</button>
</form>
</div>
- 添加样式
javascript体验AI代码助手代码解读复制代码.chat-container {
max-width: 1000px;
margin: 0 auto;
padding: 20px;
height: 100vh;
display: flex;
flex-direction: column;
background: linear-gradient(to right, #87ceeb, #ffffff); /* 天蓝色背景 */
border-radius: 10px;
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
}
.chat-header {
text-align: center;
padding: 20px 0;
color: #333;
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
}
.chat-messages {
flex: 1;
overflow-y: auto;
padding: 20px;
background: #f5f5f5;
border-radius: 10px;
margin-bottom: 20px;
}
.message {
margin-bottom: 20px;
padding: 10px;
border-radius: 10px;
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
}
.message.human {
background: #e3f2fd;
margin-left: 20%;
}
.message.ai {
background: #d1c4e9;
margin-right: 20%;
border: 1px solid #b39ddb;
}
.message-content {
word-wrap: break-word;
}
.message-content strong {
display: block;
margin-bottom: 5px;
}
.message-content p {
margin: 0;
}
.chat-input {
padding: 20px 0;
}
.input-form {
display: flex;
align-items: center;
gap: 10px;
}
input {
flex: 1;
padding: 15px; /* 增加输入框高度 */
border: 1px solid #ddd;
border-radius: 5px;
font-size: 16px;
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
}
.upload-icon {
cursor: pointer;
font-size: 24px;
margin-left: -30px;
}
input[type="file"] {
display: none;
}
button {
padding: 15px 20px; /* 增加按钮高度 */
background: #1976d2;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
}
button:disabled {
background: #ccc;
cursor: not-allowed;
}
button:hover:not(:disabled) {
background: #1565c0;
}
.progress-bar {
width: 100%;
background-color: #f3f3f3;
border-radius: 5px;
overflow: hidden;
margin-top: 10px;
}
.progress {
height: 10px;
background-color: #4caf50;
width: 0;
transition: width 0.4s ease;
}
.upload-message {
margin-top: 10px;
font-size: 14px;
color: #333;
text-align: center;
}
数据驱动
使用 vue 3 组合式 api
javascript体验AI代码助手代码解读复制代码<script setup>
</script>
- 定义响应式数据
javascript体验AI代码助手代码解读复制代码import { ref } from 'vue';
// 用于管理状态的响应式引用
const question = ref(''); // 用户的问题
const messages = ref([]); // 存储聊天消息的数组
const streaming = ref(false); // 标志AI是否正在流式传输响应
const currentResponse = ref(''); // 当前AI响应的流式传输内容
const sessionId = 'chat-' + Date.now(); // 聊天的唯一会话ID
const messageContainer = ref(null); // 消息容器的引用,用于滚动
- 实现滚动消息容器到底部的函数
typescript体验AI代码助手代码解读复制代码// 滚动消息容器到底部的函数
const scrollToBottom = () => {
const container = messageContainer.value;
container.scrollTop = container.scrollHeight;
};
- 向服务器发送问题,并流式响应
typescript体验AI代码助手代码解读复制代码
// 向服务器发送问题的函数
const sendQuestion = () => {
// 检查问题是否为空
if (!question.value.trim()) return;
// 将用户的问题添加到消息数组中
messages.value.push({
type: 'human',
content: question.value
});
// 设置流式传输为true并清除当前响应
streaming.value = true;
currentResponse.value = '';
// 创建一个新的EventSource用于服务器发送事件
const eventSource = new EventSource(`http://localhost:8080/sse?question=${encodeURIComponent(question.value)}&session_id=${sessionId}`);
// 在接收到数据时将其附加到currentResponse
eventSource.onmessage = (event) => {
currentResponse.value += event.data;
};
// 处理接收SSE时的错误
eventSource.onerror = () => {
console.error('Error receiving SSE');
messages.value.push({
type: 'ai',
content: '抱歉,发生错误,请稍后重试。'
});
streaming.value = false;
eventSource.close();
};
// 处理AI响应结束
eventSource.addEventListener('end', () => {
// 将AI的响应添加到消息数组中
messages.value.push({
type: 'ai',
content: currentResponse.value
});
// 重置流式传输和问题状态
streaming.value = false;
question.value = '';
currentResponse.value = '';
// 滚动到消息容器的底部
scrollToBottom();
eventSource.close();
});
};
再上述函数中 ,创建EventSource 对象实现 SSE 流式返回文字(即一个字一个字蹦出来)
处理文档
实现思路
我使用 Markdown 文档 ,取名 gushi.md

现在使用 LangChain 库对文本文件进行处理,将其分割成文档块,生成向量表示,并使用 Faiss 向量存储库将这些向量保存到本地的功能。具体步骤如下:
- 加载文本文件。
- 将文本分割成较小的文档块。
- 使用 OpenAI 的嵌入模型将文档块转换为向量。
- 将这些向量存储到 Faiss 向量存储库中。
- 把 Faiss 向量存储库保存到本地文件系统。
1. 导入必要的模块
javascript体验AI代码助手代码解读复制代码import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import "dotenv/config";
import { FaissStore } from "@langchain/community/vectorstores/faiss";
import { OpenAIEmbeddings } from "@langchain/openai";
import path from "path";
import { fileURLToPath } from 'url';
import { dirname } from 'path';
TextLoader:用于从文件系统中加载文本文件。RecursiveCharacterTextSplitter:用于将文本分割成较小的文档块。dotenv/config:加载环境变量,通常用于存储 API 密钥等敏感信息。FaissStore:Faiss 是一种高效的向量存储和搜索库,这里用于存储文档的向量表示。OpenAIEmbeddings:使用 OpenAI 的嵌入模型将文本转换为向量。path、fileURLToPath和dirname:用于处理文件路径,确保在不同环境中都能正确定位文件。
2. 获取当前文件所在目录
javascript体验AI代码助手代码解读复制代码const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
在 ES 模块中,__filename 和 __dirname 不是全局变量,需要手动获取。
3. 定义异步函数 run
javascript体验AI代码助手代码解读复制代码const run = async () => {
const baseDir = __dirname;
const loader = new TextLoader(path.join(baseDir, "./data/gushi.md"));
const docs = await loader.load();
baseDir:当前文件所在目录。TextLoader:加载./data/gushi.md文件内容。loader.load():异步加载文件内容并返回文档对象。
4. 分割文档
javascript体验AI代码助手代码解读复制代码const splitter = new RecursiveCharacterTextSplitter("markdown",{
chunkSize: 390,
chunkOverlap: 30,
});
const splitDocs = await splitter.splitDocuments(docs);
RecursiveCharacterTextSplitter:以 Markdown 格式将文档分割成块,每个块大小为 390 个字符,块之间有 30 个字符的重叠。splitter.splitDocuments(docs):异步分割文档并返回分割后的文档块数组。
chunkSize 、chunkOverlap 这样设置的原因其实是我后面测出来的 , 因为文档切割会影响向量化 , 进而影响切割检索 ,最终影响回复的质量
于是我使用ChunkViz v0.1
大体可以保证每一个文件块内容较为独立 , 实践证明 : 这样有利于解决 ,需要检索全文的问题 , 比如 : 你会什么故事 ? 这就需要检索全局

5. 生成向量并存储
javascript体验AI代码助手代码解读复制代码const embeddings = new OpenAIEmbeddings();
const vectorStore = await FaissStore.fromDocuments(splitDocs, embeddings);
OpenAIEmbeddings:使用 OpenAI 的嵌入模型将文档块转换为向量。FaissStore.fromDocuments(splitDocs, embeddings):根据分割后的文档块和嵌入模型创建 Faiss 向量存储库。
6. 保存向量存储库
javascript体验AI代码助手代码解读复制代码await vectorStore.save(path.join(baseDir, "./db/gushi"));
};
5,6 步骤后实现向量持久化
将 Faiss 向量存储库保存到 ./db/gushi 目录。
7. 调用 run 函数
javascript体验AI代码助手代码解读复制代码run();
检索数据
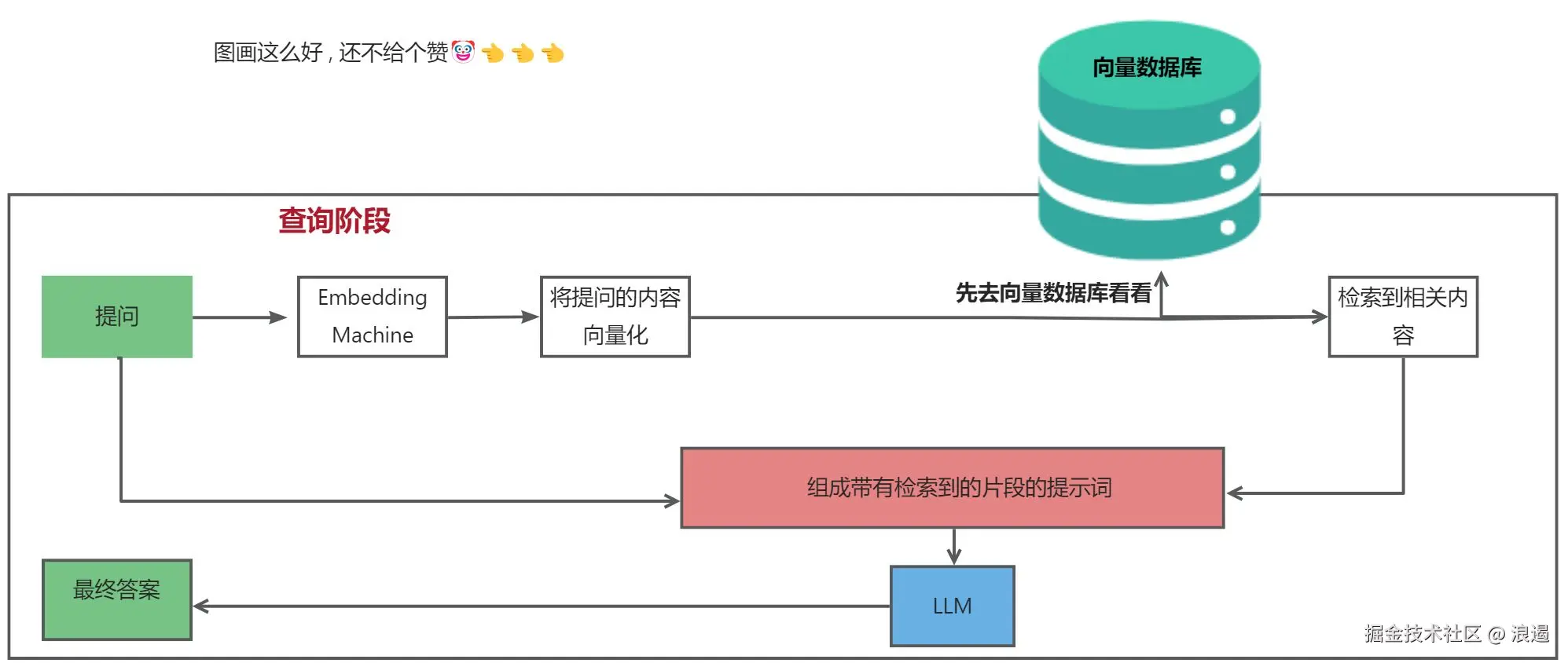
实现的思路大体如下 , 再这个基础上 ,我们还实现了 Memory 机制
我么主要的思路是构建两条**主要 **chain 来实现
- 一条是 chain
- 借助 llm 负责重塑用户提问 , 使用gpt-3.5-turbo 节约成本
- 另一条也是 chain🤡
- 设置 prompt , 从向量数据库检索数据 、结合 Memory 上下文实现 RAG
- 再这条 chain 中 , 创建多条 chain
llm 重塑用户提问
javascript体验AI代码助手代码解读复制代码
// llm 重塑用户提问
async function getRephraseChain() {
const rephraseChainPrompt = ChatPromptTemplate.fromMessages([
[
"system",
"给定以下对话和一个后续问题,请将后续问题重述为一个独立的问题。请注意,重述的问题应该包含足够的信息,使得没有看过对话历史的人也能理解。",
],
new MessagesPlaceholder("history"),
["human", "将以下问题重述为一个独立的问题:\n{question}"],
]);
const rephraseChain = RunnableSequence.from([
rephraseChainPrompt,
new ChatOpenAI({
temperature: 0.1,
model: "gpt-3.5-turbo"
}),
new StringOutputParser(),
]);
return rephraseChain;
}
RAG chain
javascript体验AI代码助手代码解读复制代码// 加载向量库
async function loadVectorStore() {
const directory = "./db/gushi";
const embeddings = new OpenAIEmbeddings();
const vectorStore = await FaissStore.load(directory, embeddings);
return vectorStore;
}
export async function getRagChain() {
const vectorStore = await loadVectorStore();
const retriever = vectorStore.asRetriever(2);
const convertDocsToString = (documents) => {
return documents.map((document) => document.pageContent).join("\n");
};
const contextRetrieverChain = RunnableSequence.from([
(input) => input.standalone_question,
retriever,
convertDocsToString,
]);
const SYSTEM_TEMPLATE =(question)=> `
以下是知识库中跟用户回答相关的内容:
{context}
你是一个把小学所有故事都背完了的小学生,精通根据故事原文详细解释和回答问题,你在回答时会引用知识库中的作品原文。
并且回答时仅根据原文,尽可能回答用户问题,
请仔细阅读知识库,时间很充足,你必须做到精准把握知识库中的内容 , 之后根据下面规则
1.如果用户的问题${question}与{context}有关,但是知识库中没有相关的内容,你就回答“原文中没有相关内容,我是小学生,知识有限”。
2.如果用户的问题${question}与{context}无关,但是知识库中没有相关的内容,你就回答“我是小学生,知识有限,你的问题超出了我的想象”。
3.如果用户的问题${question}与{context}有关,并且知识库中有相关的内容,根据用户问题${question}引用{context}回答。
`;
const prompt= (question) => ChatPromptTemplate.fromMessages([
["system", SYSTEM_TEMPLATE(question)],
new MessagesPlaceholder("history"),
["human", "现在,你需要基于原文,回答以下问题:\n{standalone_question}`"],
]);
const model = new ChatOpenAI({
temperature: 0.9,
model: "gpt-4o",
});
const rephraseChain = await getRephraseChain();
const ragChain = RunnableSequence.from([
RunnablePassthrough.assign({
standalone_question: rephraseChain,
}),
RunnablePassthrough.assign({
context: contextRetrieverChain,
}),
(input)=>prompt(input.standalone_question),
model,
new StringOutputParser(),
]);
const chatHistoryDir = "./chat_data";
const ragChainWithHistory = new RunnableWithMessageHistory({
runnable: ragChain,
getMessageHistory: (sessionId) => new JSONChatHistory({ sessionId, dir: chatHistoryDir }),
historyMessagesKey: "history",
inputMessagesKey: "question",
});
return ragChainWithHistory;
}
1. 加载向量库
javascript体验AI代码助手代码解读复制代码async function loadVectorStore() {
const directory = "./db/gushi";
const embeddings = new OpenAIEmbeddings();
const vectorStore = await FaissStore.load(directory, embeddings);
return vectorStore;
}
loadVectorStore是一个异步函数,用于加载本地存储的 Faiss 向量库。directory指定了向量库的存储目录。OpenAIEmbeddings用于将文本转换为向量表示。FaissStore.load方法从指定目录加载向量库。
2. 获取 RAG 链
javascript体验AI代码助手代码解读复制代码export async function getRagChain() {
const vectorStore = await loadVectorStore();
const retriever = vectorStore.asRetriever(2);
getRagChain是一个异步函数,用于构建 RAG 链并返回。- 调用
loadVectorStore函数加载向量库。 vectorStore.asRetriever(2)创建一个检索器,每次检索返回最多 2 个相关文档。
3. 文档转换函数
javascript体验AI代码助手代码解读复制代码const convertDocsToString = (documents) => {
return documents.map((document) => document.pageContent).join("\n");
};
convertDocsToString函数将检索到的文档数组转换为字符串,方便后续处理。
4. 上下文检索链
javascript体验AI代码助手代码解读复制代码const contextRetrieverChain = RunnableSequence.from([
(input) => input.standalone_question,
retriever,
convertDocsToString,
]);
-
RunnableSequence.from创建一个可运行的序列,依次执行三个步骤:
- 提取输入中的
standalone_question。 - 使用检索器检索相关文档。
- 将检索到的文档转换为字符串。
- 提取输入中的
5. 系统提示模板
javascript体验AI代码助手代码解读复制代码const SYSTEM_TEMPLATE =(question)=> `
以下是知识库中跟用户回答相关的内容:
{context}
你是一个把小学所有故事都背完了的小学生,精通根据故事原文详细解释和回答问题,你在回答时会引用知识库中的作品原文。
并且回答时仅根据原文,尽可能回答用户问题,
请仔细阅读知识库,时间很充足,你必须做到精准把握知识库中的内容 , 之后根据下面规则
1.如果用户的问题${question}与{context}有关,但是知识库中没有相关的内容,你就回答“原文中没有相关内容,我是小学生,知识有限”。
2.如果用户的问题${question}与{context}无关,但是知识库中没有相关的内容,你就回答“我是小学生,知识有限,你的问题超出了我的想象”。
3.如果用户的问题${question}与{context}有关,并且知识库中有相关的内容,根据用户问题${question}引用{context}回答。
`;
SYSTEM_TEMPLATE是一个函数,根据用户问题生成系统提示模板,指导语言模型如何回答问题。
6. 提示模板
javascript体验AI代码助手代码解读复制代码const prompt= (question) => ChatPromptTemplate.fromMessages([
["system", SYSTEM_TEMPLATE(question)],
new MessagesPlaceholder("history"),
["human", "现在,你需要基于原文,回答以下问题:\n{standalone_question}`"],
]);
prompt是一个函数,根据用户问题生成聊天提示模板,包含系统提示、聊天历史记录占位符和用户问题。
7. 语言模型实例
javascript体验AI代码助手代码解读复制代码const model = new ChatOpenAI({
temperature: 0.9,
model: "gpt-4o",
});
ChatOpenAI创建一个 OpenAI 聊天模型实例,temperature控制生成文本的随机性,model指定使用的模型名称。
8. 重述链
javascript体验AI代码助手代码解读复制代码const rephraseChain = await getRephraseChain();
getRephraseChain是一个未给出实现的异步函数,用于重述用户问题。
9. RAG 链
javascript体验AI代码助手代码解读复制代码const ragChain = RunnableSequence.from([
RunnablePassthrough.assign({
standalone_question: rephraseChain,
}),
RunnablePassthrough.assign({
context: contextRetrieverChain,
}),
(input)=>prompt(input.standalone_question),
model,
new StringOutputParser(),
]);
-
RunnableSequence.from创建一个可运行的序列,依次执行以下步骤:
- 使用
RunnablePassthrough.assign将重述后的问题添加到输入中。 - 使用
RunnablePassthrough.assign将检索到的上下文添加到输入中。 - 根据输入的问题生成提示模板。
- 使用语言模型生成回答。
- 使用
StringOutputParser将模型输出转换为字符串。
- 使用
10. 支持聊天历史记录的 RAG 链
javascript体验AI代码助手代码解读复制代码const chatHistoryDir = "./chat_data";
const ragChainWithHistory = new RunnableWithMessageHistory({
runnable: ragChain,
getMessageHistory: (sessionId) => new JSONChatHistory({ sessionId, dir: chatHistoryDir }),
historyMessagesKey: "history",
inputMessagesKey: "question",
});
return ragChainWithHistory;
}
RunnableWithMessageHistory创建一个支持聊天历史记录的 RAG 链,将聊天历史记录存储在./chat_data目录下。
路由和 SSE 实现
javascript体验AI代码助手代码解读复制代码import express from "express";
import { getRagChain} from "./index.mjs";
import cors from "cors";
封装响应数据
javascript体验AI代码助手代码解读复制代码const Result = (code, data, msg) => {
return {
code,
data,
msg,
};
};
解决跨域问题
javascript体验AI代码助手代码解读复制代码const app = express();
const port = 8080;
app.use(cors({
origin: ['http://localhost:3000', 'http://localhost:5173'],
methods: ['GET', 'POST'],
allowedHeaders: ['Content-Type']
}));
设置路由
javascript体验AI代码助手代码解读复制代码
app.use(express.json());
// 处理 SSE 请求 , 实现流式响应对话
app.get("/sse", async (req, res) => {
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
const question = req.query.question;
const sessionId = req.query.session_id || 'default-session';
try {
const ragChain = await getRagChain();
const result = await ragChain.stream(
{
question: question,
},
{ configurable: { sessionId: sessionId } },
);
if (!result) {
res.write(`event: end\ndata: AI 响应生成失败\n\n`);
res.end();
return;
}
for await (const chunk of result) {
res.write(`data: ${chunk}\n\n`);
}
res.write(`event: end\ndata: \n\n`);
res.end();
} catch (error) {
console.error('Error:', error);
res.write(`event: end\ndata: 服务器错误: ${error.message}\n\n`);
res.end();
}
});
app.listen(port, () => {
console.log(`Server is running on port ${port}`);
});
总结
完成 RAG 实战 ~
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









