



环境搭建
首先要在电脑上安装 Python,直接在官网下载安装包进行安装即可:www.python.org/downloads/
# 创建文件夹,可随意命名
mkdir chatgpt-pdf
cd chatgpt-pdf
# 创建虚拟环境(第二个venv为虚拟环境的名称,之所以使用venv是因为一般通用的.gitignore会默认忽略该文件夹,完全可以选择使用其它名称)
python3 -m venv venv
# 激活虚拟环境
source venv/bin/activate
# 安装依赖包
pip install langchain pdfplumber python-dotenv streamlit faiss-cpu openai tiktoken
langchain官网位于python.langchain.com/en/latest/i… ,它可以简化对各种大语言模型的使用,比如内置有OpenAI等。
pdfplumber顾名思义,是用于读取和处理PDF文件的,选择这库是因为今年还在更新,并且对中文的支持还不错。本次项目demo会导入自己的PDF文件,并将其作为知识库,回答你的提问。
python-dotenv用于读取.env文件,本例在该文件中放入Open AI平台的key。
streamlit用于绘制 UI界面,当前大多数ChatGPT应用都使用它,如大名鼎鼎的gpt4free,streamlit默认会收集信息进行分析,可通过配置文件关闭,macOS和Linux位于~/.streamlit/config.toml,Windows位于%userprofile%/.streamlit/config.toml,添加如下内容即可:
[browser]
gatherUsageStats = false
其它配置项可通过streamlit config show可查看。
faiss-cpu是facebook开源用于相似搜索的库,github.com/facebookres… ,GPU版本请使用faiss-gpu。
openai和tiktoken都是调用ChatGPT接口时使用的。
保留当前使用版本请使用pip freeze > requirements.txt。
OpenAI的注册方式这里就不介绍了,最常用的是在sms-activate.org/ 上购买服务获取短信验证码完成注册。
代码开发
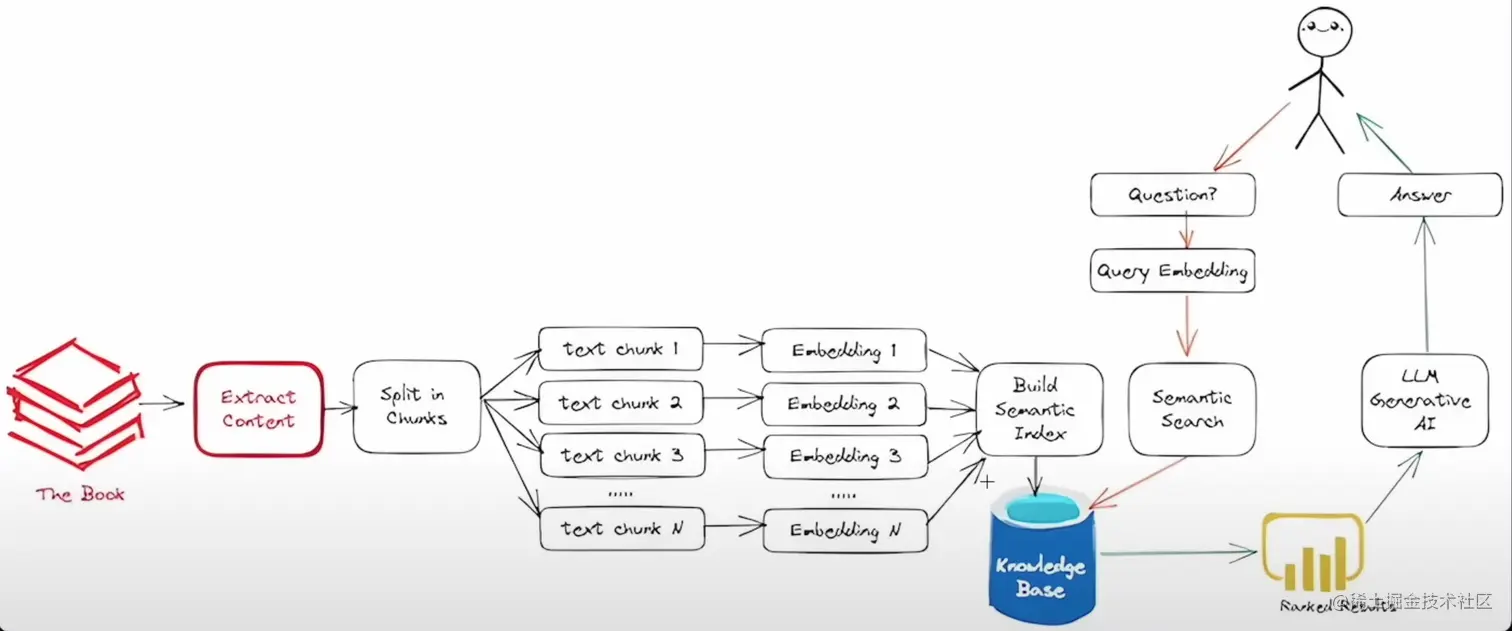
知识库搭建和使用流程图如下:
我们在根目录下创建.env文件:
OPENAI_API_KEY=你自己的key
这里的OPENAI_API_KEY名称固定,请不要修改。
然后创建app.py,先进行环境变量的读取(使用编辑器的小伙伴请注意选择刚刚创建的环境,PyCharm应该能自动识别,VScode 请按下快捷键 ctrl/cmd+shift+p进行选择),先测试读取环境变量是否正常
from dotenv import load_dotenv
import os
load_dotenv()
print(os.getenv('OPENAI_API_KEY'))
接着搭建页面框架:
import streamlit as st
st.set_page_config(page_title="专属PDF知识库")
st.header("专属PDF知识库💬")
# 上传文件
pdf = st.file_uploader("上传PDF文件", type="pdf")
运行streamlit run app.py效果如下:
提取文本:
import pdfplumber
# 提取文本
if pdf is not None:
text = ""
with pdfplumber.open(pdf) as pdf_reader:
for page in pdf_reader.pages:
text += page.extract_text()
接下对文本进行分片,这里每个分片长充为1000字符,为保留上下文选择了重叠200字符:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
接下来配置 embedding,也即将离散值转化为连续向量:
embeddings = OpenAIEmbeddings()
knowledge_base = FAISS.from_texts(chunks, embeddings)
为界面添加一个输入框:
user_question = st.text_input("来向我提问吧:")
最后完成回复的逻辑:
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
if user_question:
docs = knowledge_base.similarity_search(user_question)
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
response = chain.run(input_documents=docs, question=user_question)
st.write(response)
如需追踪花了多少钱,可增加:
from langchain.callbacks import get_openai_callback
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=user_question)
print(cb)
st.write(response)
完整代码:
from dotenv import load_dotenv
import streamlit as st
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
import pdfplumber
def main():
load_dotenv()
# locale.setlocale(locale.LC_ALL, 'zh_CN')
st.set_page_config(page_title="专属PDF知识库")
st.header("专属PDF知识库💬")
# 上传文件
pdf = st.file_uploader("上传PDF文件", type="pdf")
# 提取文本
if pdf is not None:
text = ""
with pdfplumber.open(pdf) as pdf_reader:
for page in pdf_reader.pages:
text += page.extract_text()
# 文本分片
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=50,
length_function=len
)
chunks = text_splitter.split_text(text)
# 创建embeddings
embeddings = OpenAIEmbeddings()
knowledge_base = FAISS.from_texts(chunks, embeddings)
user_question = st.text_input("来向我提问吧:")
if user_question:
docs = knowledge_base.similarity_search(user_question)
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=user_question)
print(cb)
st.write(response)
if __name__ == '__main__':
main()
国内直连接口超时问题
如果有海外服务器可以直接做代理
网上现在比较通用的方案是使用 Cloudflare Workers,比如下面是 Alan随便找到的一段代码:
const TELEGRAPH_URL = 'https://api.openai.com';
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
const url = new URL(request.url);
url.host = TELEGRAPH_URL.replace(/^https?:///, '');
const modifiedRequest = new Request(url.toString(), {
headers: request.headers,
method: request.method,
body: request.body,
redirect: 'follow'
});
const response = await fetch(modifiedRequest);
const modifiedResponse = new Response(response.body, response);
// 添加允许跨域访问的响应头
modifiedResponse.headers.set('Access-Control-Allow-Origin', '*');
return modifiedResponse;
}
但现在xxx.workers.dev在国内也无法访问,所以也是有门槛的,那就是要绑定一个自定义域名。自定义域可在.env文件中添加OPENAI_API_BASE=xxx.xxx.xxx/v1。
-
Unsupported OpenAI-Version header provided: 2022-12-01. (HINT: you can provide any of the following supported versions: 2020-10-01, 2020-11-07. Alternatively, you can simply omit this header to use the default version associated with your account.)
这个问题待探讨,快速解决方法是embeddings = OpenAIEmbeddings(openai_api_version='2020-11-07')
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









