




样本采集、制备和测序
用乙二胺四乙酸 (EDTA) 管从每位患者身上采集 5 毫升全血样本并立即处理。在 4°C 下以 1600 × g 离心 10 分钟,分离血浆和细胞成分。在 4°C 下以 16 000 × g 进一步离心血浆 10 分钟,以去除任何残留的细胞碎片,然后储存在 −80°C 下。用 QIAamp® 循环核酸试剂盒 (cat. no. 55114) 提取血浆的 cfDNA。
用 Qubit 荧光计 (Thermo Fisher Scientific,美国) 定量提取的 cfDNA 浓度,并使用 Qsep-400 (Bioptic) 检测尺寸分布。使用 MGI 的 VAHTS 通用 DNA 文库制备试剂盒(南京 Vazyme-Tech)输入每个血浆样本的总 cfDNA 进行文库制备。
根据制造商的方案,使用 MGISP-960 高通量自动样品制备系统 (MGI-Tech) 进行 CfDNA 分离和 WGS 文库构建。简而言之,纯化的 cfDNA 经过末端修复、A 尾、连接模块、聚合酶链反应 (PCR) 扩增和单链环化。所有单链环状 DNA 文库均在 MGISEQ-2000 平台 (MGI-Tech) 上进行双端reads( paired-end reads )测序,为每个样本生成约 15 Gb 的全基因组数据 (MGI-Tech)。
准备指令调整数据(**末端基序频率矩阵 A**)
对于每个样本,我们随机选择了 100 万个 reads ( 1 million reads)并将其分成 10 组;因此,每组有 0.1 百万个 reads( 0.1 million reads )。对于每组,我们计算了从测序的 cfDNA reads 的 5’ 端开始的 256 个 4-kmers 的频率,从而产生了一个表示末端基序频率的向量。因此,我们可以获得训练集的末端基序频率矩阵 A(256行*10列的矩阵)。
End-motif sentence语句(记为 e)
为了得到end-motifs语句,我们对向量 a 进行降序排序(从大道小排序)。因此,我们得到了一个排序后的end-motifs列表
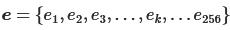
,其中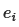 是第 i 个结束语句的名称, 是 的频率。
是第 i 个结束语句的名称, 是 的频率。
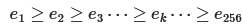
我们将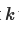 设置为 64(也可以设置为16,32),以获得排名前 64 的end-motifs语句,并将它们用空格连接成一个句子。
设置为 64(也可以设置为16,32),以获得排名前 64 的end-motifs语句,并将它们用空格连接成一个句子。
k=16的例子,

k=32的例子,

k=64的例子,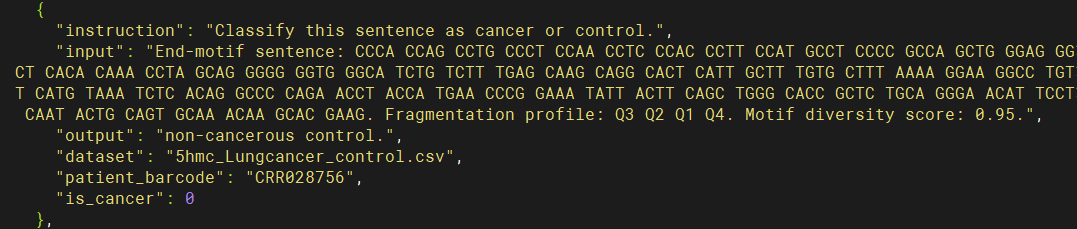
MDS (denoted as s)
它描述了 cfDNA 末端基序频率的分布,其定义为:
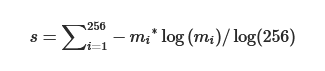
其中 是第 i 个末端基序的频率。
片段化概况句子(表示为 f)
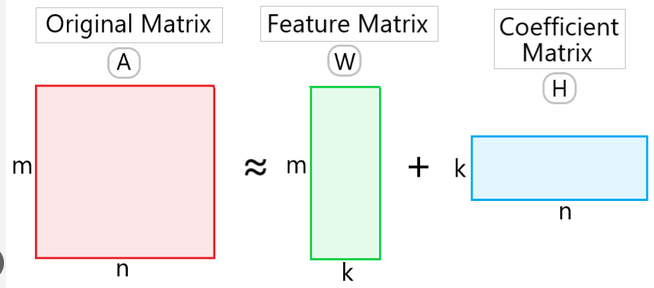
为了获得碎片化概况,我们对从训练集中获得的末端基序频率矩阵 A 执行了 NMF 反卷积(NMF deconvolution)。具体来说,A 被分解为两个非负矩阵 W 和 H,具体如下:
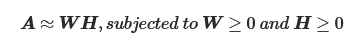
根据周等人 [30] 的研究(30.Zhou Q, Kang G, Jiang P, et al.Epigenetic analysis of cell-free DNA by fragmentomic profiling .Proc Natl AcadSciUSA2022;119:e2209852119.https://doi.org/10.1073/pnas.2209852119.),W 可视为片段化组学特征,H 为碎片化概况。我们使用 NMF R 包中实现的 nmf 算法对 A 进行 NMF 分解。根据共表型系数和稀疏度得分(cophenetic coefficient and sparsity score),将最佳秩rank设置为 4(补充图 2)。(一个256*10矩阵A,经过NMF分解成一个256*4矩阵W和一个4*10矩阵H)
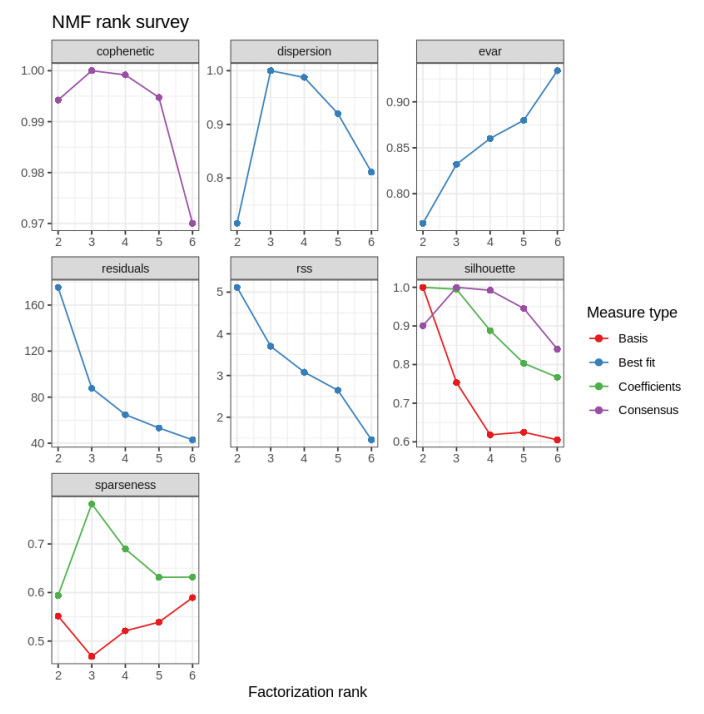
补充图 2
令 H:,i 表示 H 的第 i 列。假设 H:,i = {Q0, Q1, Q2, Q3} 的碎片化概况值且 Q1 ≥ Q0 ≥ Q2 ≥ Q3,则碎片化概况句子可以表示为“碎片化概况:Q1 Q0 Q2 Q3”。
诊断标签(表示为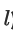 )
)
它是样本的句子描述。例如,“它是癌症”或“它是正常对照”。
最终,每个数据点都有四个属性:末端基序句子(表示为 e)、碎片概况句子(表示为 f)、MDS(表示为 s)和诊断标签(表示为 l)。在训练集中,我们根据图 1B 中指定的模板将 e、f、s 和 l 连接起来作为训练数据点来开发 iLLMAC。在测试集中,我们排除了 l,但只是将 e、f 和 s 连接起来作为输入上下文 c。
在评估阶段,我们为 iLLMAC 提供输入上下文 c,并让它生成预测的诊断标签(表示为 l*)。通过比较 l 和 l*,我们可以衡量其性能。对于患者级别的预测,我们使用预测的癌症标签的分数作为最终的预测分数。例如,假设从特定个体收集 n 个数据点,其中 k 个预测为癌症标签;因此,预测分数(the predicted score)计算为 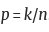 。
。
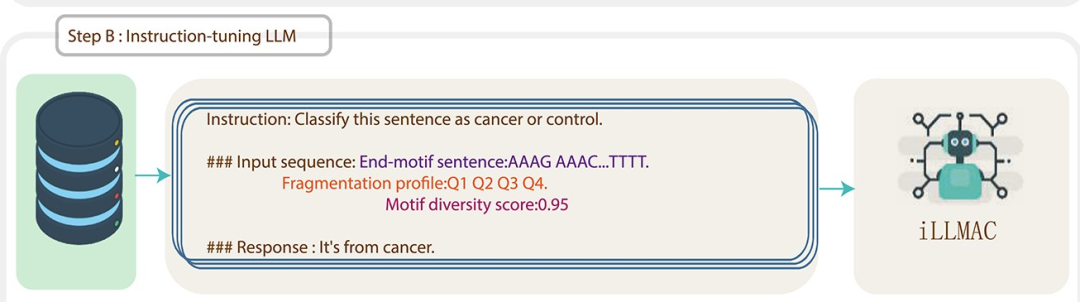
开发指令调整的大型语言模型用于评估癌症
我们对开源的 **LLaMA 模型(LLaMA model)**进行了指令调整,该模型有大约 70 亿个参数。此预训练模型的检查点从 https://huggingface.co/meta-llama/Llama-2-7b-hf 下载。
LLaMA 是自然语言理解的基础模型,它建立在 Transformer 解码器之上。它的工作原理是将一系列单词作为输入,并预测下一个单词以递归生成文本。每个输入单词都嵌入到 4096 维的向量中,随后通过 32 层 Transformer 解码器块进行处理,以学习不同单词之间的上下文关系。我们使用 Adam 优化器、批处理大小为 16、权重衰减为 0.01、初始学习率为 2e-5(一个时期,one epochs),使用我们的演示数据对 LLaMA 进行了指令调整。学习率为 3% 的步骤预热,并按照余弦调度向零下降。
该模型使用 PyTorch(版本 1.7.1)和 transformers(版本 4.21.1)在 NVIDIA DGX A100 上进行训练,该设备配备 8 个 GPU,每个 GPU 具有 40 Gb 内存。输入序列长度设置为 64。

脱氧核糖核酸碎片评估,用于早期拦截(Deoxyribonucleic acid evaluation of fragments for early interception)
DELFI 方法由 Cristiano 及其同事 [17] (Cristiano, S., Leal, A., Phallen, J. et al. Genome-wide cell-free DNA fragmentation in patients with cancer. Nature 570, 385–389 (2019). https://doi.org/10.1038/s41586-019-1272-6)提出,用于分析全基因组无细胞 DNA 碎片以检测癌症。我们遵循作者在
https://github.com/Cancer-Genomics/delfi_scripts 上整理的流程。
具体来说,我们使用 bwa (v0.7.17) 进行序列比对,使用 samtools (v0.1.19) 对齐文件进行排序和去重,使用 bedtools (v2.30.0) 生成 bed 文件。使用 R 包(例如 GenomicRanges (v1.50.0)、GenomicAlignments (v1.34.0) 和 tidyverse (v2.0.0))获取 cfDNA 碎片组和拷贝数特征;使用 caret (v6.0–93) 进行数据预处理和构建梯度提升机分类器。
如何使用NMF R包
在R中使用NMF(非负矩阵分解)算法,可以通过安装和使用NMF R包来实现。以下是使用NMF R包进行NMF分解的基本步骤:
安装和加载NMF包
首先,你需要安装NMF包。如果尚未安装,可以使用以下命令进行安装:
install.packages("NMF")
完整示例代码
以下是完整的示例代码:

通过这些步骤,你可以使用NMF R包对数据进行NMF分解,并提取出基向量和系数。
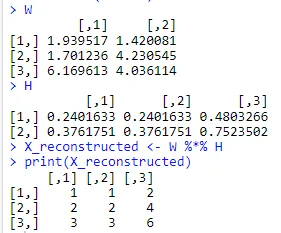
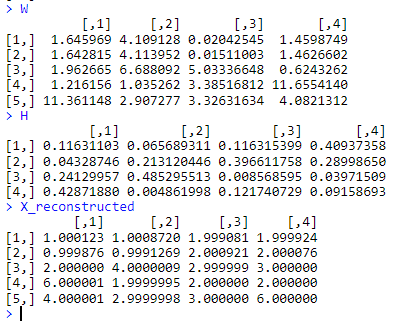
再来看一个54矩阵,经过NMF分解成一个54矩阵和一个4*4矩阵的例子。
X <- matrix(c(1, 1, 2, 2,1, 1, 2, 2, 2, 4, 3, 3, 6, 2, 2, 2, 4, 3, 3, 6), nrow = 5, byrow = TRUE)
# 执行NMF分解
set.seed(0)
result <- nmf(X, rank = 4)
# 查看结果
W <- basis(result)
H <- coef(result)
# 验证结果
X_reconstructed <- W %*% H
print(X_reconstructed)
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









