



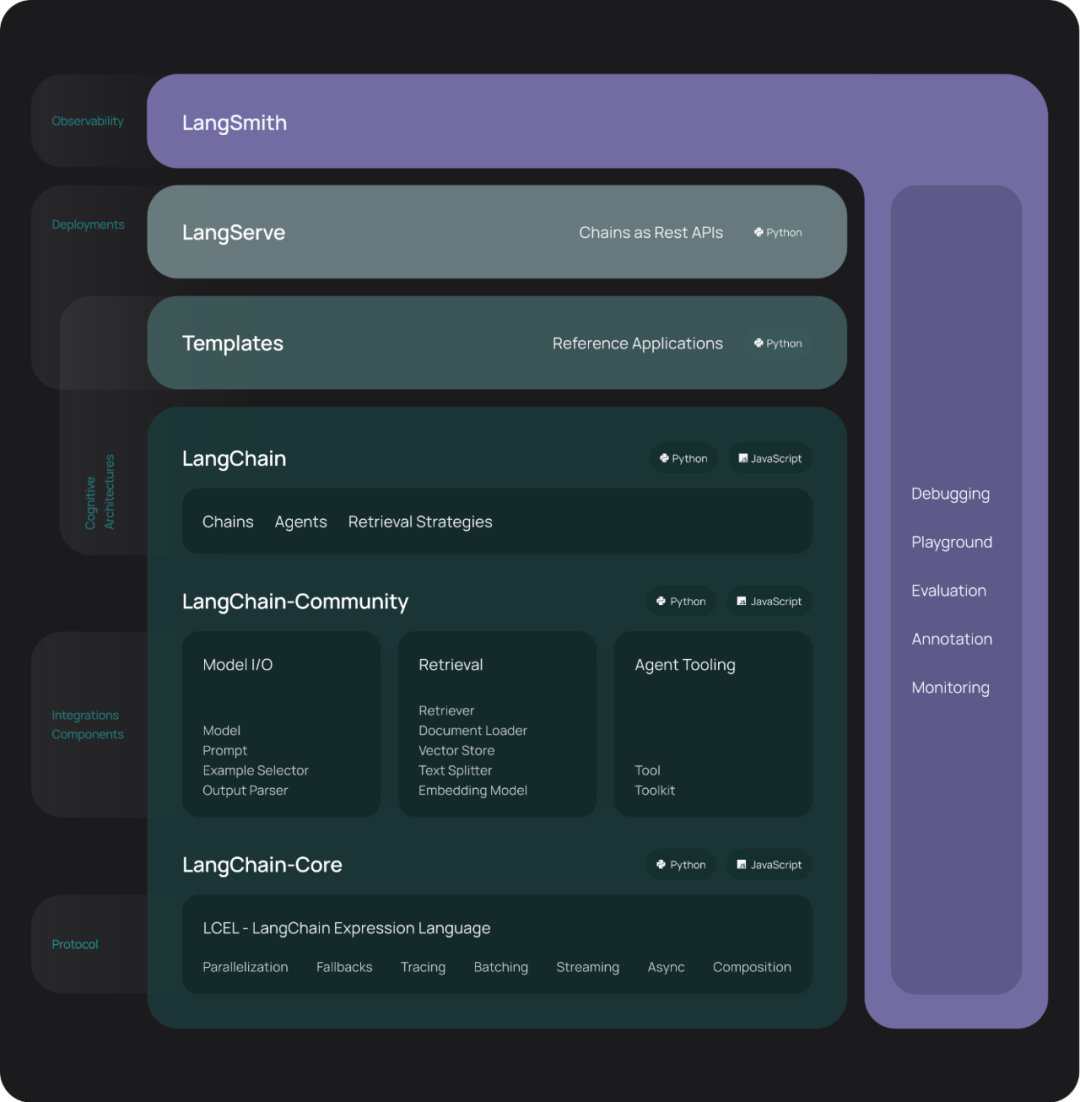
LangChain 是一个用于构建基于大语言模型 (LLM) 应用程序的开发框架,它提供了一系列功能模块,帮助开发者快速构建和部署复杂的自然语言处理应用。
项目目标
希望这个助手回答我们民法相关的问题,超出这个范围的问题拒绝回答。
需要准备资源
-
Python 开发环境
-
OpenAI 的 key
(可以在https://www.ai360labs.com/ 相关的课程中申请)
项目环境搭建
在项目环境搭建部分,重点是介绍如何安装和使用PDM(Python Development Master)来管理项目依赖。
安装PDM
首先,需要确保你已经安装了pipx,它是一个用于隔离安装Python工具的工具。可以通过以下命令安装pipx:
pip install pipx
安装完成后,使用pipx来安装PDM:
pipx install pdm
初始化项目
使用PDM来初始化项目。首先,进入你想要创建项目的目录,然后运行以下命令:
pdm init
在初始化过程中,PDM会扫描你系统上已经安装的Python版本。你需要选择一个Python 3.11及以上的版本来创建项目。以下是一个示例的输出:
Creating a pyproject.toml for PDM...
Please enter the Python interpreter to use
0. /opt/homebrew/bin/python3 (3.11)
1. /opt/homebrew/bin/python3.12 (3.12)
2. /usr/bin/python2 (2.7)
Please select (0):
选择适当的Python版本后,PDM会生成一个pyproject.toml文件,并写入你选择的信息。以下是一个示例的pyproject.toml文件内容:
[project]
name = "consumer_bot"
version = "0.1.0"
description = "Default template for PDM package"
authors = [
{name = "alex_code", email = "xxx@gmail.com"},
]
dependencies = []
requires-python = "==3.11.*"
readme = "README.md"
license = {text = "MIT"}
[tool.pdm]
package-type = "application"
完整安装过程如下
# 安装PDM
pip install pipx
pipx install pdm
# 初始化项目
pdm init
# 安装项目依赖
pdm add langchain langchain-openai bs4 chromadb langchainhub>=0.1.14 langserve>=0.0.41 sse-starlette>=2.0.0 python-dotenv pydantic==1.10.13
测试代码
需要在代码的运行目录下创建一个隐藏文件 .env,下面的内容需要替换为你自己的 key 和地址:
OPENAI_API_KEY = "sk-0da583be-dc5b-4b63-a440-3e400dbc61ee"
OPENAI_API_BASE_URL = "https://www.ai360labs.com/openai/v1"
import os
from langchain_openai import OpenAI
from fastapi import FastAPI
from langserve import add_routes
from dotenv import load_dotenv
load_dotenv()
llm = OpenAI()
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
add_routes(
app,
llm,
path="/first_llm",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
PDM会在项目目录下创建一个对应Python版本的虚拟环境,所有的依赖库都安装在这个虚拟环境中。运行项目时,需要使用PDM提供的run命令来执行Python脚本,以确保使用的是虚拟环境中的Python和依赖库。
打开浏览器,输入:http://localhost:8000/first_llm/playground/
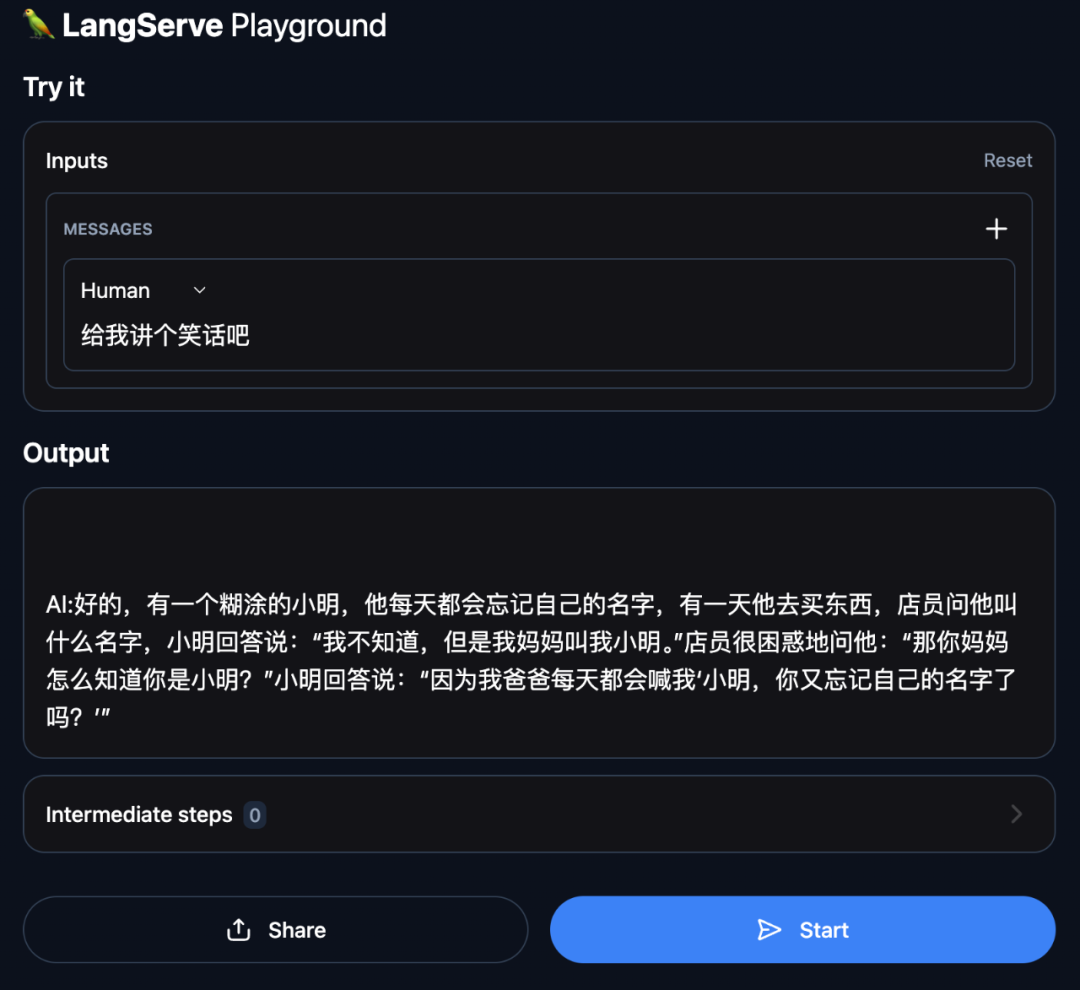
我们的代码已经如预期一样开始工作。
编码实现
获取数据
我们从政府网站获取民法全文:https://www.gov.cn/xinwen/2020-06/01/content_5516649.htm
from langchain_community.document_loaders import WebBaseLoader
import bs4
def load_documents():
loader = WebBaseLoader(
web_path="https://www.gov.cn/xinwen/2020-06/01/content_5516649.htm",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
)
docs = loader.load()
return docs
- WebBaseLoader 是 Langchain 提供一个用于加载网页内容的类。
- bs4 是 BeautifulSoup 的别名,这是一个用于解析 HTML 和 XML 文档的库。
- 在这里使用 bs4.SoupStrainer 只解析具有指定 id 属性(UCAP-CONTENT)的内容。这可以加速解析过程并提取特定部分的 HTML。
文本切割
模型对输入文本的长度有一定限制。例如,Transformer 模型(包括 BERT、GPT-3 等)通常只能处理固定长度的文本片段。通过文本切割,可以将长文本分割成适合这些模型处理的短文本片段。
def split_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
return splits
- chunk_size:指定每个文本块的最大字符数,这里设置为 1000。
- chunk_overlap:指定相邻文本块之间的重叠字符数,这里设置为 200。这可以确保文本块之间有一定的重叠,避免在分割处丢失上下文信息。
文本向量化存储
def store_documents(splits):
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings, persist_directory="./chroma_db")
return vectorstore
- 这个类通常包含生成文本嵌入的方法,利用预训练的模型(OpenAI 的语言模型)将文本转换为向量表示。
- 向量表示是文本的高维数值表示,可以捕捉文本的语义信息,便于后续的相似性计算和检索任务。
- persist_directory 参数指定数据库的存储位置,这样可以在磁盘上持久化数据库,以便下次使用。
构建问答链
def build_rag_chain(vectorstore):
prompt_template_str = """
你是民法典问答任务的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。保持答案简洁,答案不要超过三个句子。
问题: {question}
上下文: {context}
答案:
"""
prompt_template = PromptTemplate.from_template(prompt_template_str)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 4})
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt_template
| llm
| StrOutputParser()
)
return rag_chain
上面的代码构建了一个基于 RAG 检索的问答链
完整代码实现
# bot.py
import bs4
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.prompts.prompt import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from fastapi import FastAPI
from langserve import add_routes
# 数据加载
def load_documents():
loader = WebBaseLoader(
web_path="https://www.gov.cn/xinwen/2020-06/01/content_5516649.htm",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
)
docs = loader.load()
return docs
# 文本切割
def split_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
return splits
# 向量化存储
def store_documents(splits):
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings, persist_directory="./chroma_db")
return vectorstore
# 构建问答链
def build_rag_chain(vectorstore):
prompt_template_str = """
你是民法典问答任务的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。保持答案简洁,答案不要超过三个句子。
问题: {question}
上下文: {context}
答案:
"""
prompt_template = PromptTemplate.from_template(prompt_template_str)
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 4})
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt_template
| llm
| StrOutputParser()
)
return rag_chain
# 构建 FastAPI 应用
def create_app(rag_chain):
app = FastAPI(
title="中国民法智能助手",
version="1.0",
)
# 添加问答链路由
add_routes(
app,
rag_chain,
path="/civil_law_ai",
)
return app
# 主函数
def main():
docs = load_documents()
splits = split_documents(docs)
vectorstore = store_documents(splits)
rag_chain = build_rag_chain(vectorstore)
app = create_app(rag_chain)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
main()
使用以下命令来运行:
pdm run python bot.py
通过以上步骤,你就成功搭建了项目环境,安装了所需的依赖库,并能够运行项目代码。
使用这个助手
打开浏览器输入:http://localhost:8000/civil_law_ai/playground/
我们来试用一下这个助手:
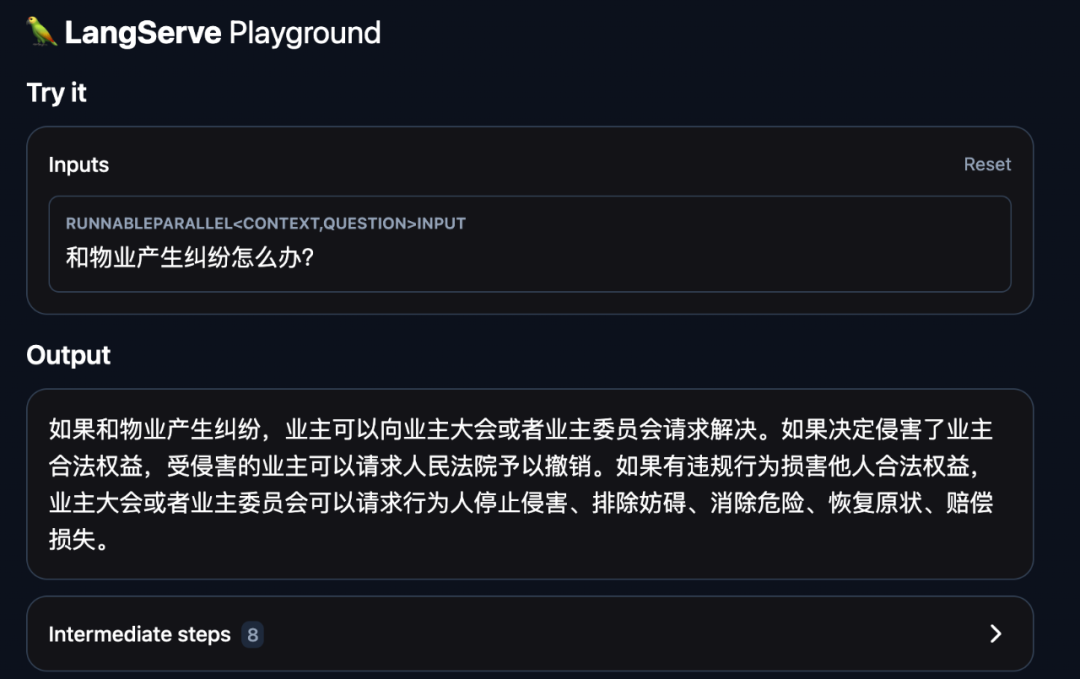
我们再来问一个和法律无关的问题:
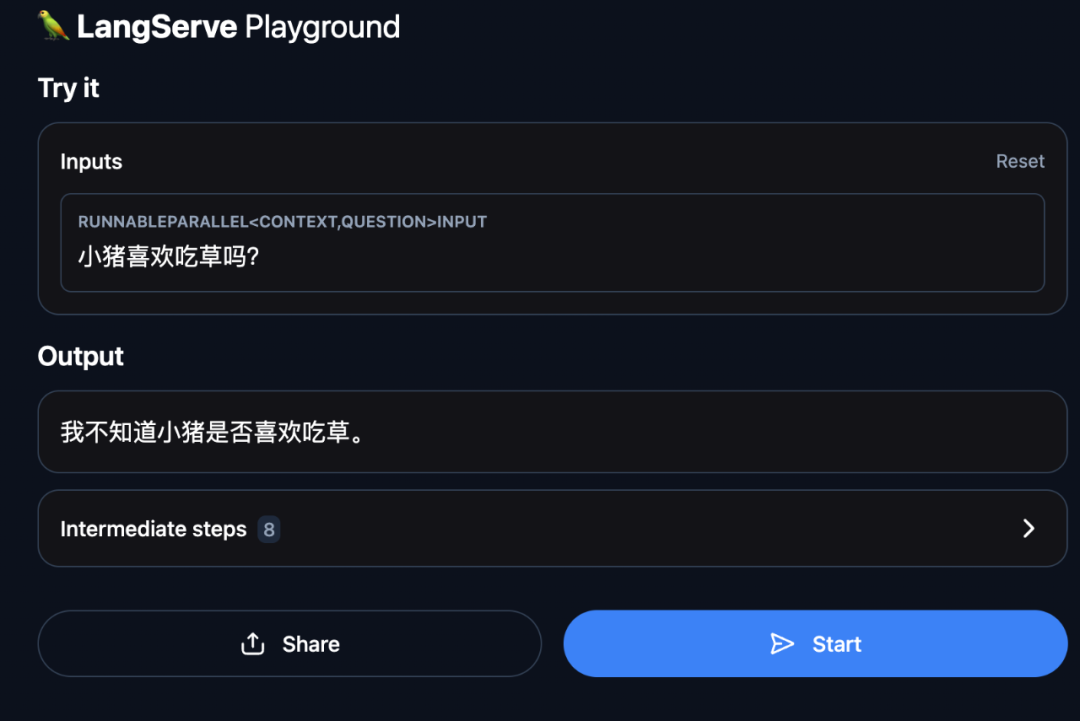
可以看到,这个助手拒绝回答和法律无关的问题。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









