



在本文中,我将介绍Ollama最近对Llama 3.2 Vision的支持更新,并分享Llama 3.2 Vision的实测结果。同时,我还将介绍一个视觉RAG系统,展示如何将Llama 3.2 Vision与该系统结合,完成基于视觉RAG检索的任务。
先介绍此次更新:
Ollama 现在正式支持 Llama 3.2 视觉模型(Llama 3.2 Vision)。
你看就像这样拖进去就可以识别图片了。
▲ 来源 | Prompt Engineering
你可以看到该模型有11B参数版和90B参数版。选择90B参数版时,文件大小约为55GB。当然还有一些量化的版本。
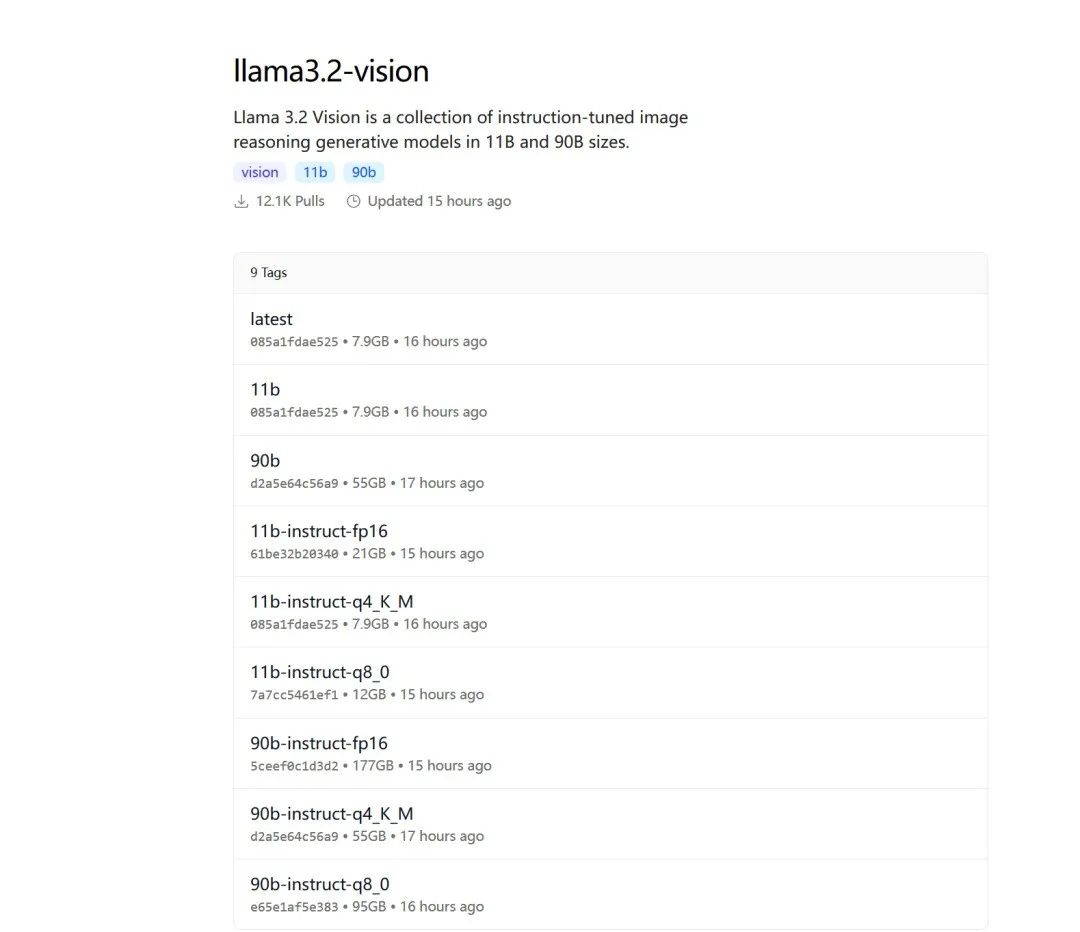
Llama 3.2 Vision 11B 至少需要 8GB VRAM,而 90B 型号至少需要 64 GB VRAM。
为了安装它,你需要更新一下ollama,这里以docker安装的ollama为例,没更新前拉取这个视觉模型不成功,我们需要删掉容器,再pull更新它。
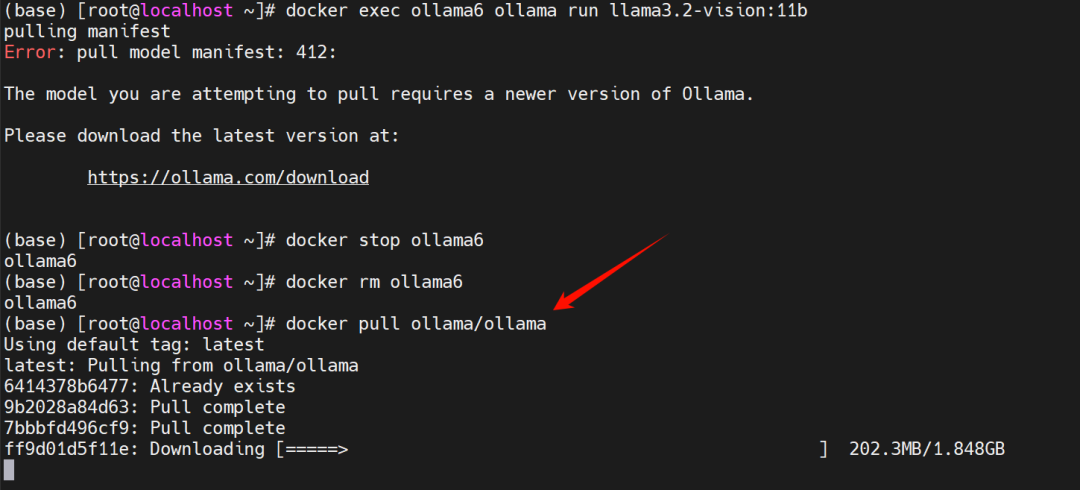
更新完之后我们可以执行拉取操作
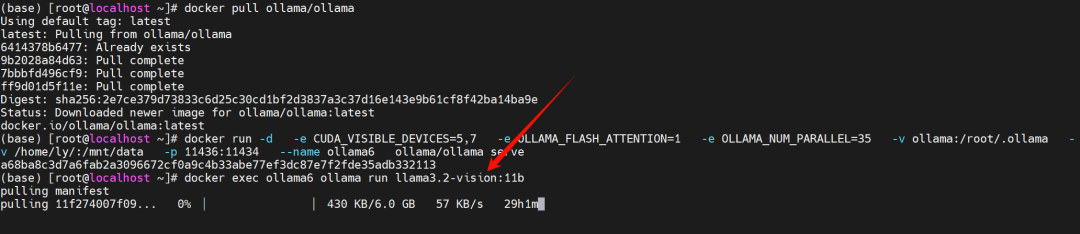
如果你的是Linux版本ollama由于网络问题下载不成功的话,你可以看看这篇文章的末尾。
Ollama 升级!支持一键拉取Huggingface上所有的模型,太方便了!(vLLM、Fastgpt、Dify、多卡推理)2024-10-17
你可以使用ollama python库这样运行它的测试
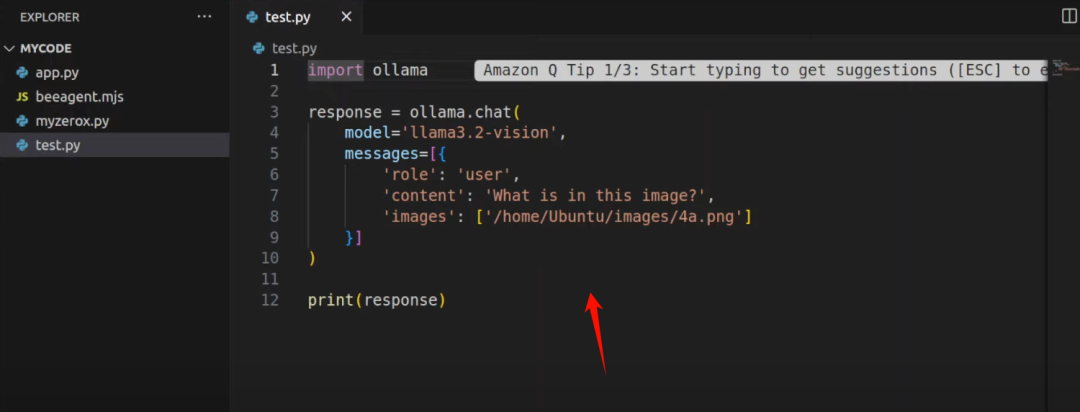
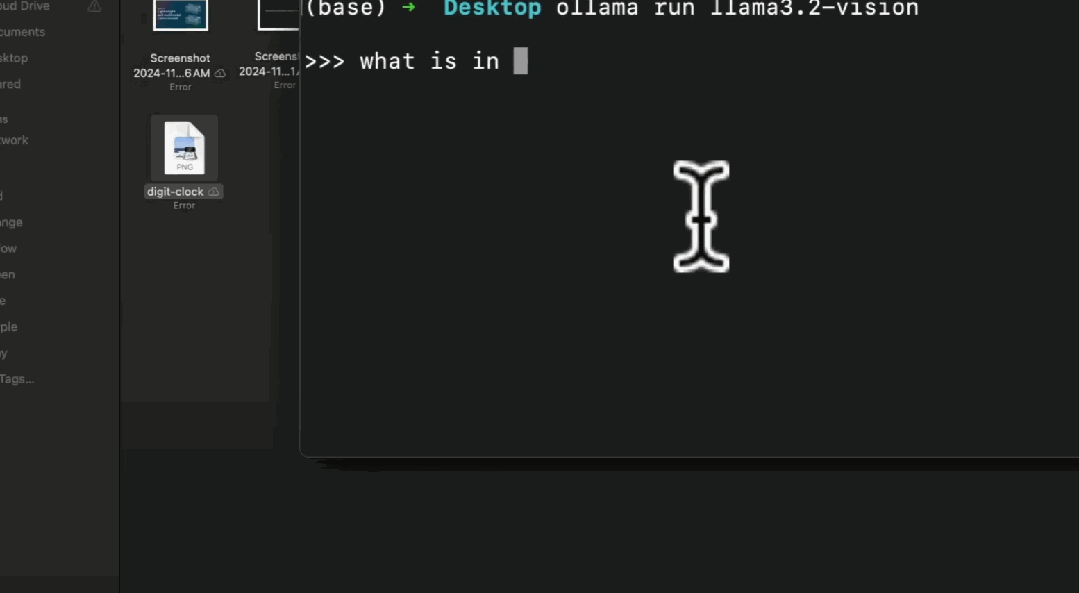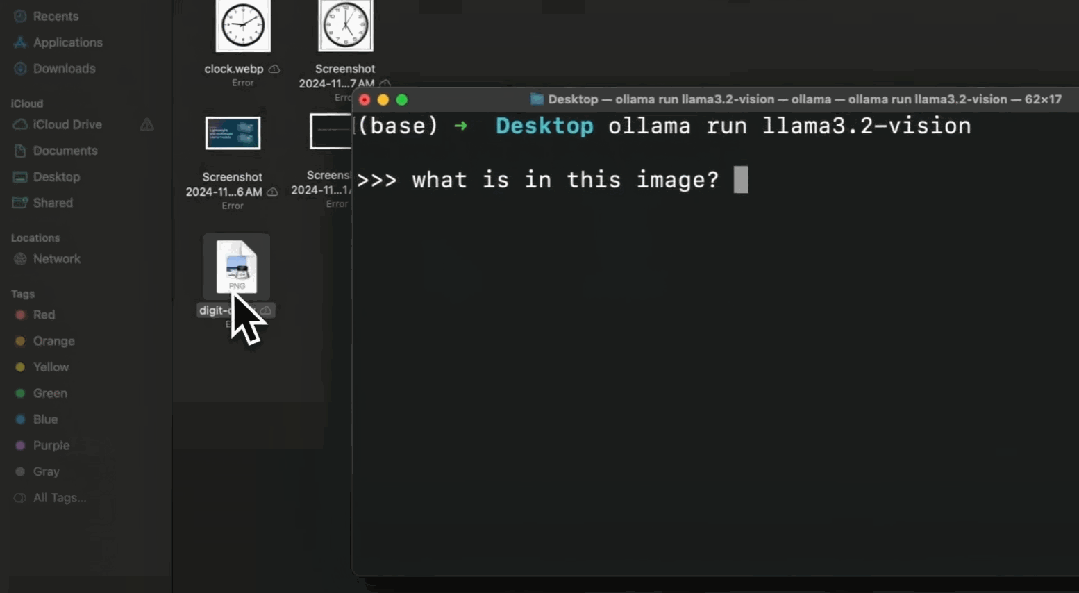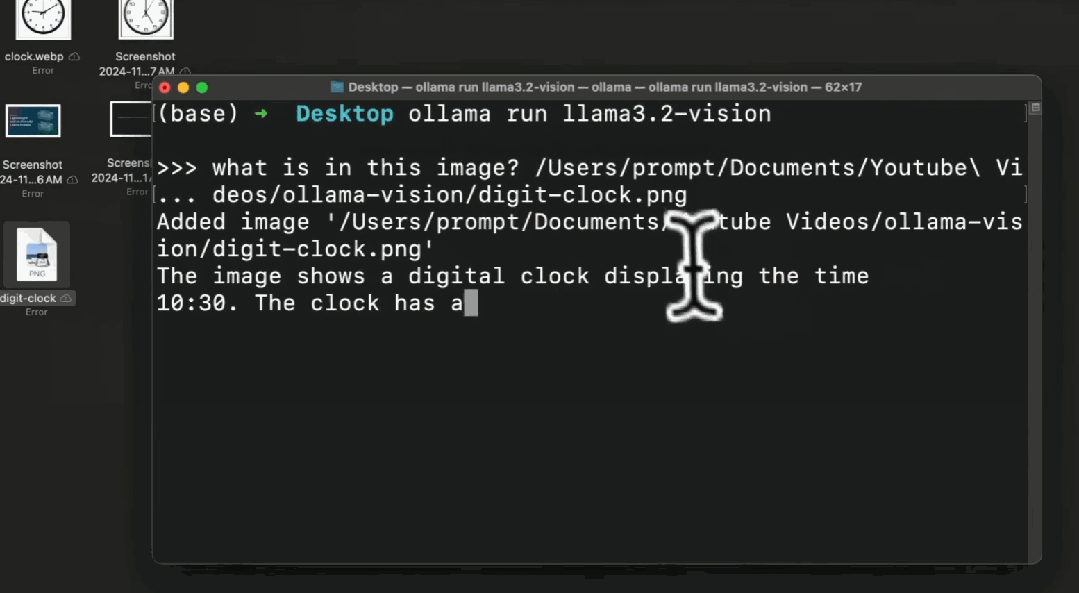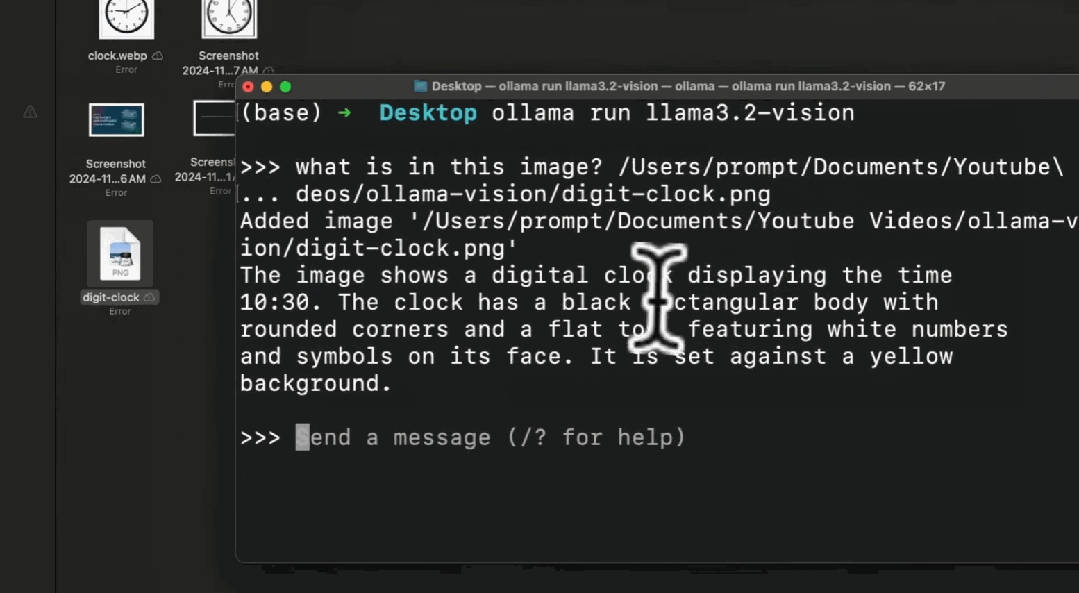
通过本地图像路径向模型提问“这张图片是什么”。

▲ 来源 | Fahd Mirza
模型返回了结果,描述图片中有“日落、袋鼠和一群鸟,太阳位于画面中央,但被云遮挡。” 这正是图片内容。
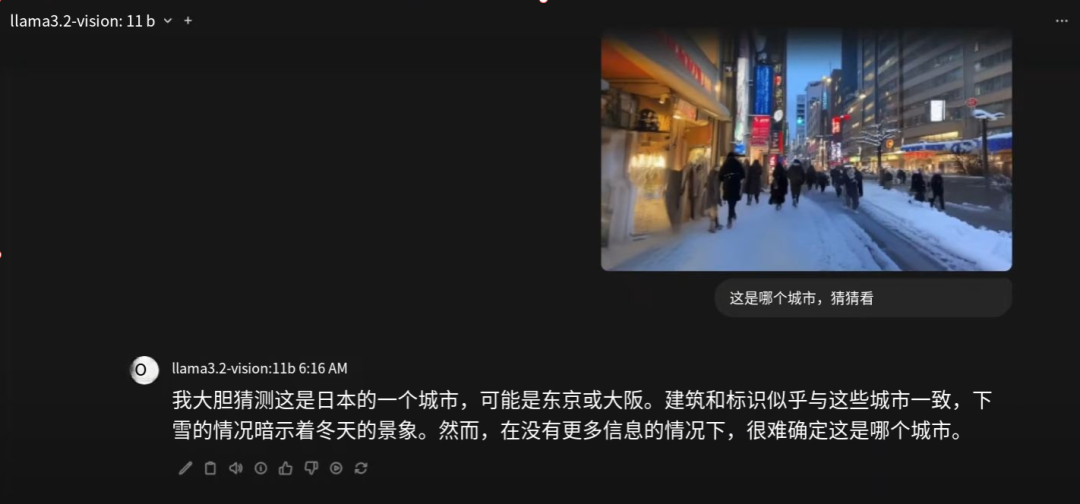
“ 这是什么城市?”,模型会给出答案:“我猜这是日本的城市,可能是东京或大阪。”
我们看看其他一些场景的情况:
手写内容识别
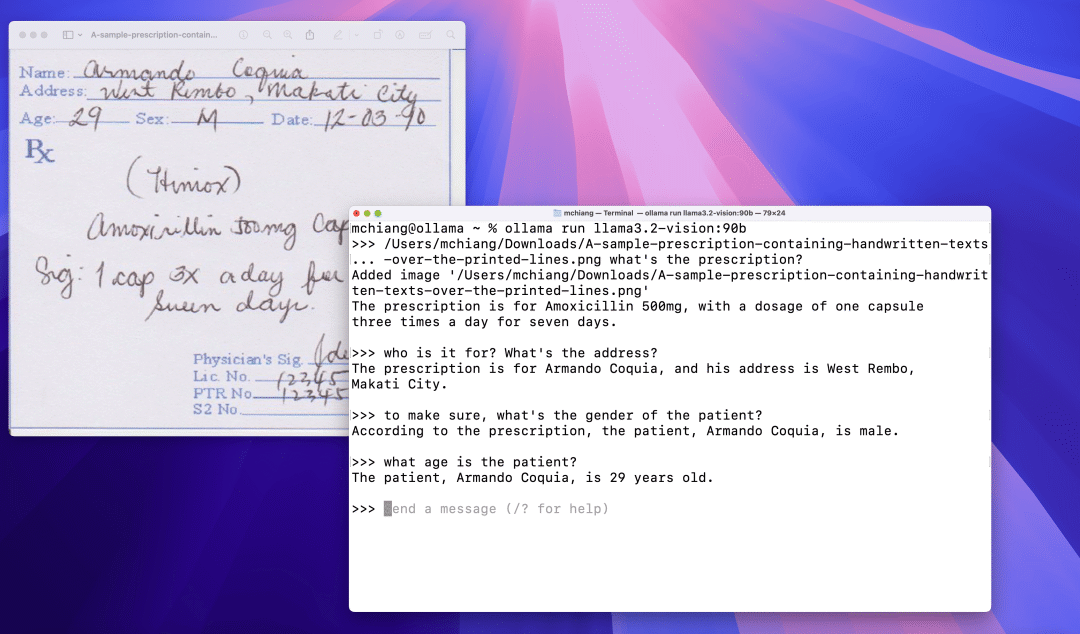
光学字符识别 (OCR)

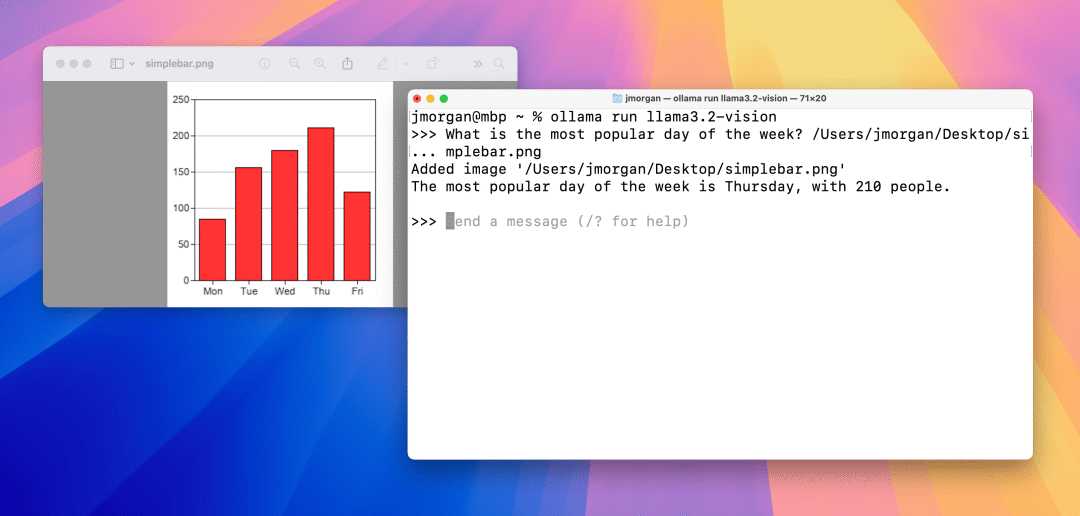
图表和表格
图片问答
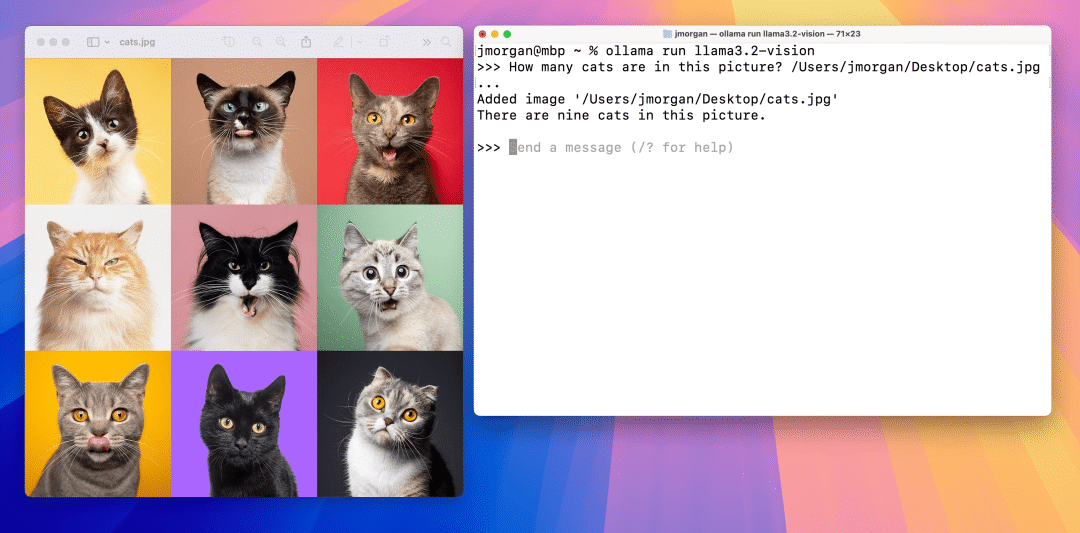
还是不错的。
下面我们进入正题 …
*一个视觉RAG系统 + Llama 3.2 Vision*
LocalGPT-Vision 是一个基于视觉的检索增强生成 (RAG) 系统,它可以让你与文档进行对话,使用Vision语言模型实现端到端的RAG系统。
该项目使用Colqwen 或 ColPali模型进行基于视觉的页面信息检索,检索到的页面将传递到视觉语言模型 (VLM) 以生成响应。
安装这个项目:
首先,你需要克隆代码仓库或拉取最新的更改;然后你需要创建一个新的虚拟环境来使用conda;最后使用pip install -r requirements.txt安装所有需要的包。
为了启动主应用程序,我们将使用python app.py,这会启动我们的Flask服务器,并在该URL上运行。只需在浏览器中访问即可。
这是本地GPT Vision的主界面。如果你进入模型列表,将看到检索模型。我将选择Colqwen ,它是最适合的模型之一。
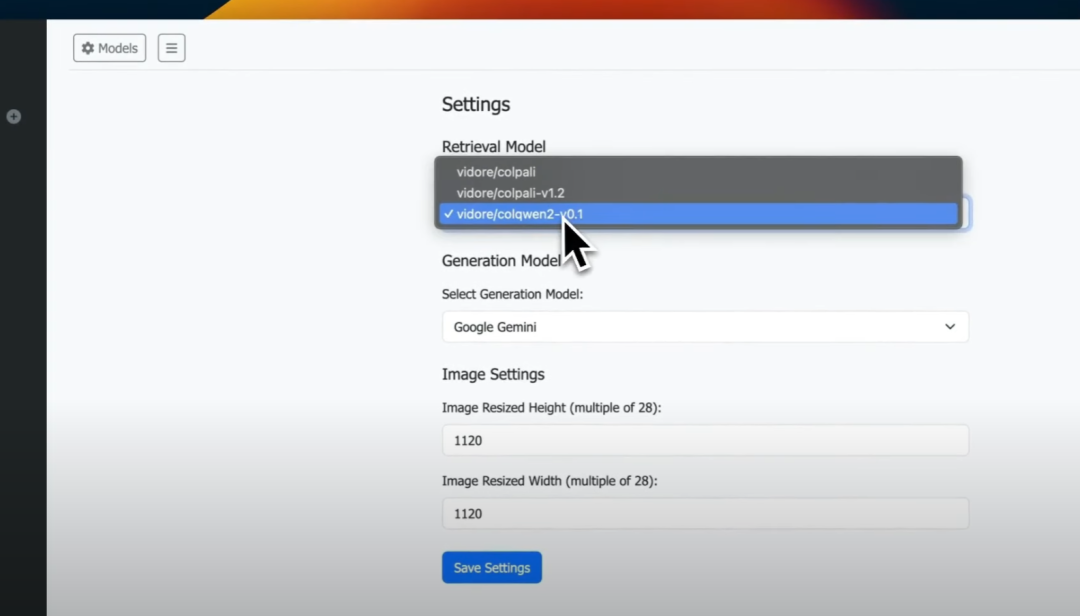
对于生成模型,你有多个选项,我将选择Ollama Llama Vision,
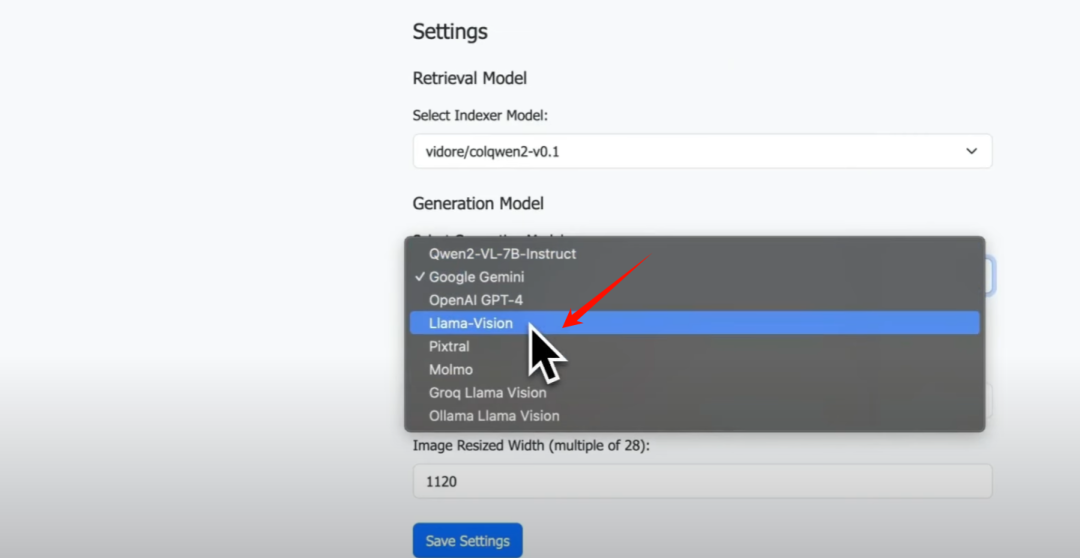
然后保存更改。
对于被RAG的对象,我们使用一篇名叫Light RAG论文,这是一种简单快速的检索增强生成方法,结合了知识库和基于密集向量的方式,特别适用于具有某种关系的实体。


开始:
点击上传文档按钮,选择相应的PDF文件,然后点击“开始索引”。
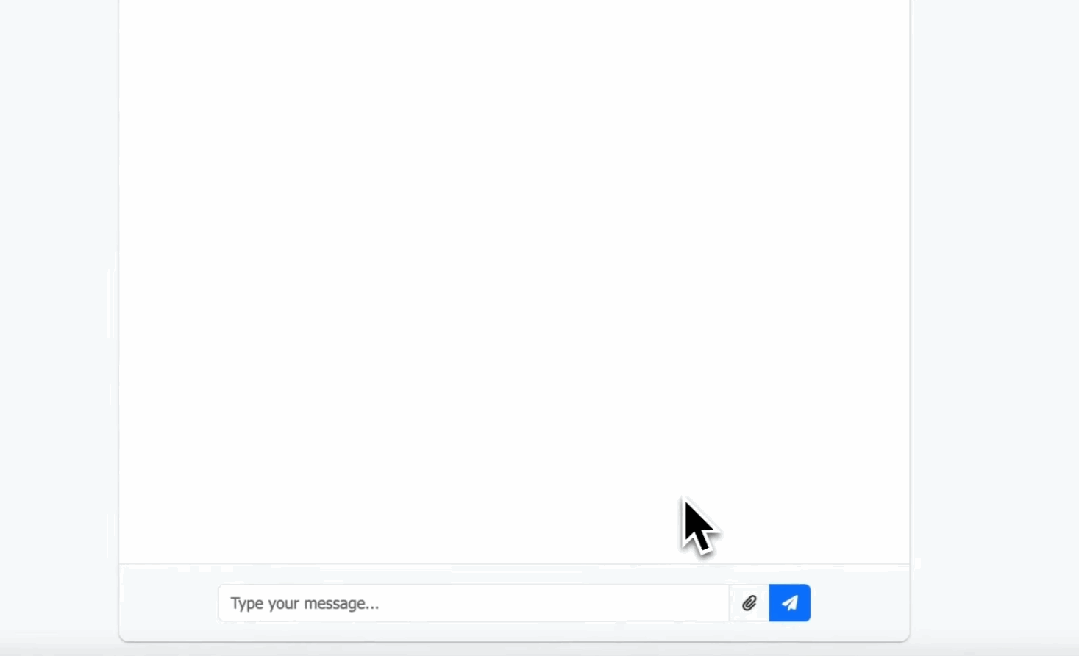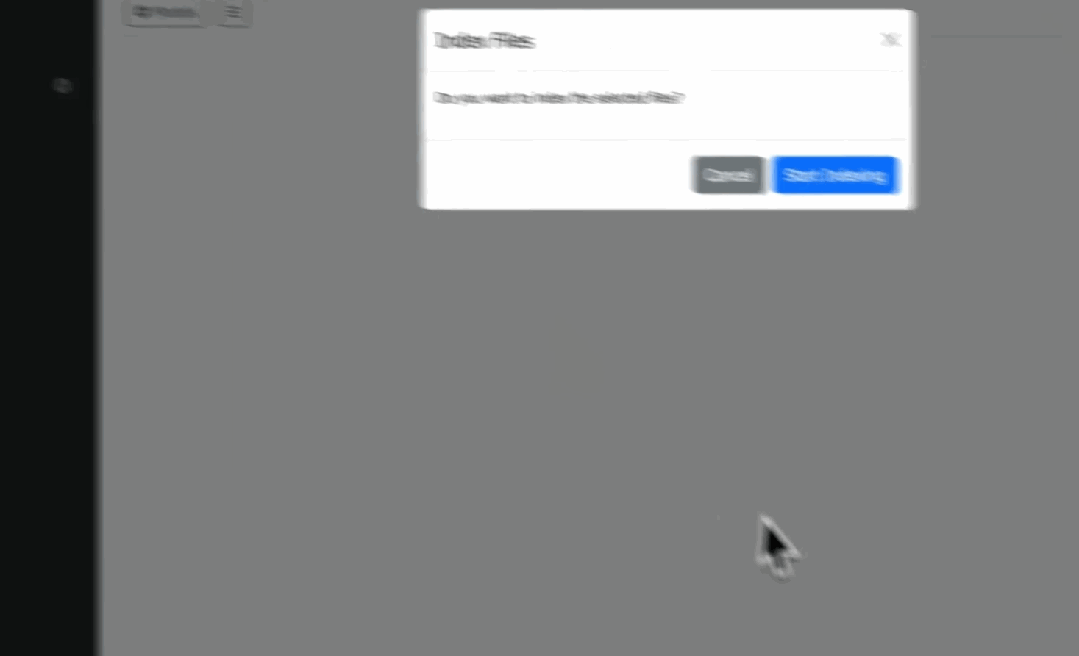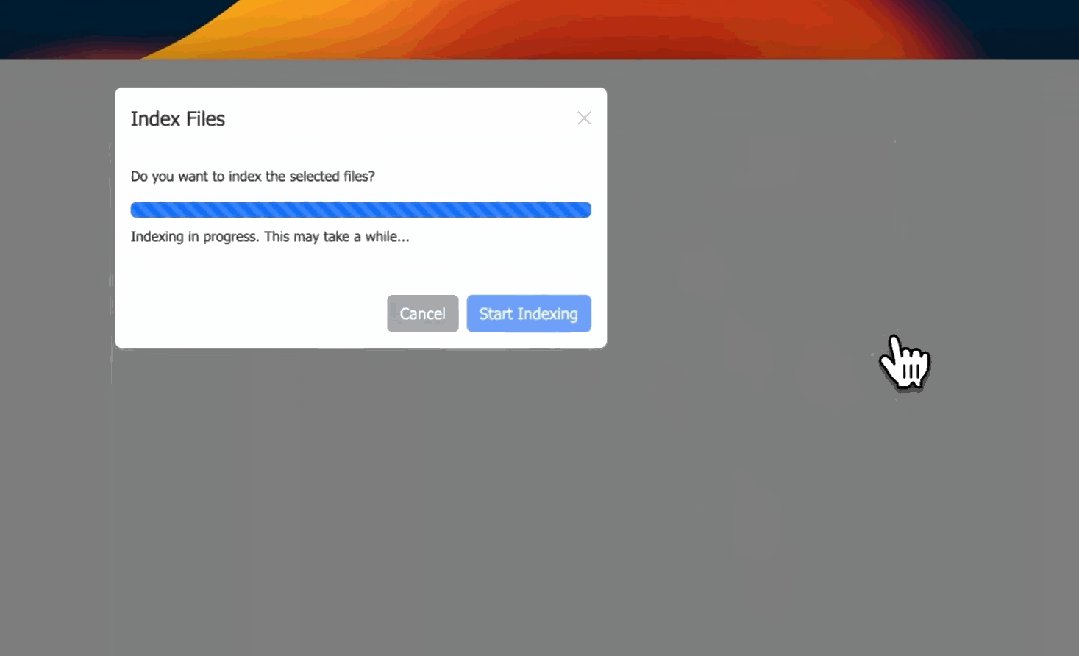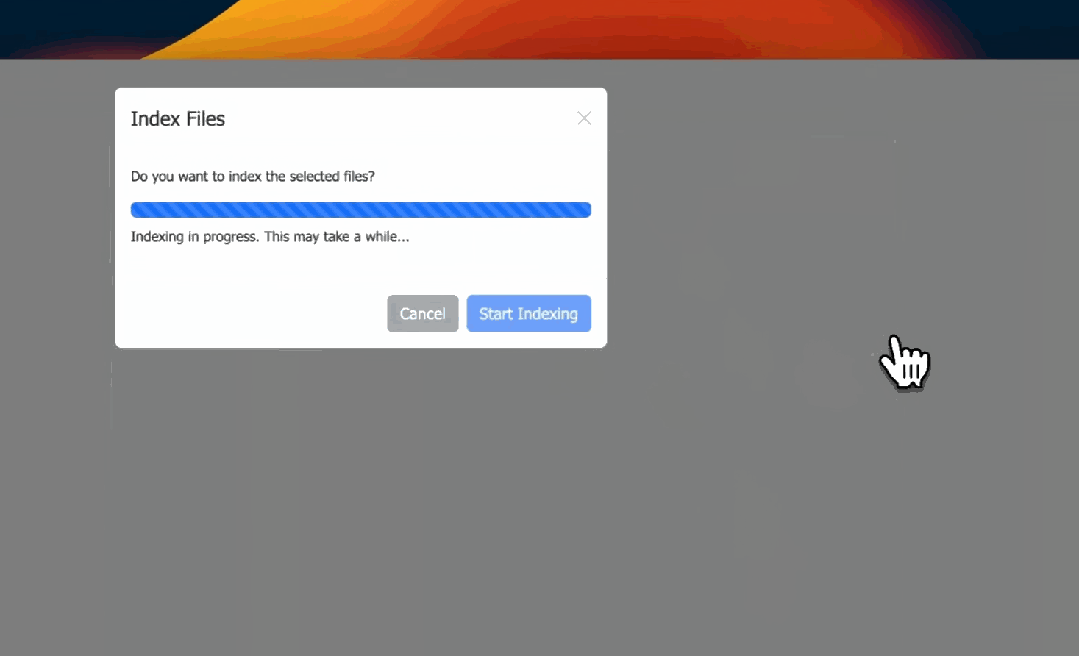
▲ 来源 | Prompt Engineering
此时,后台将使用Colqwen模型为PDF中的每一页创建多维向量表示,转换成图像并计算嵌入,所有这些操作都依赖于强大的poppler库。
如果遇到问题,请确保已安装poppler库,因为有些人在使用这个库时遇到过问题。索引完成后,点击“确定”,然后开始与刚才创建的知识库进行交互。
首先,我们用一个简单的提示开始:“这篇论文的标题是什么?”
你可以看到,论文的标题是《Light RAG: Simple and Fast Retrieval Augmented Generation》。
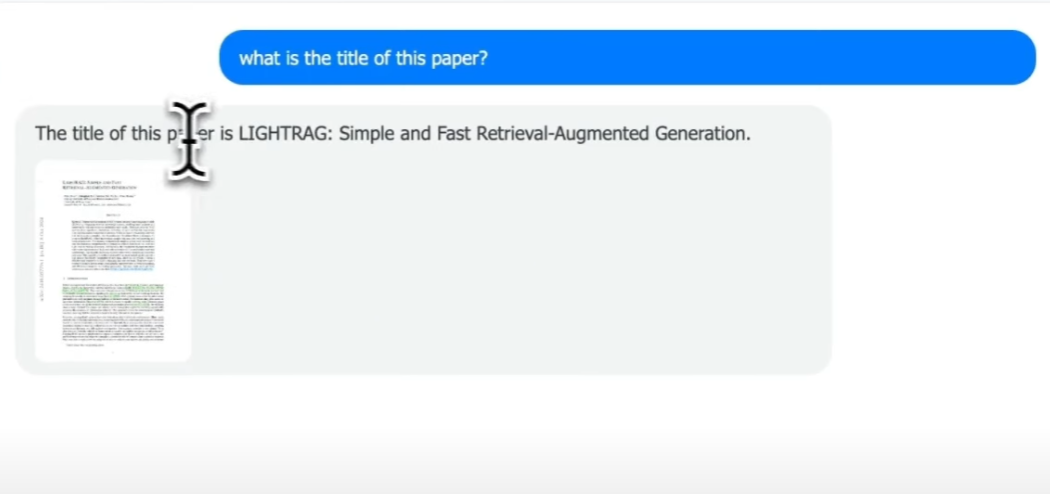
它与标题完全一致。
接下来我们可以看看它是否能够解释该图像的详细信息。
我问:“你能详细解释图1吗?”

图1 作为论文中的一个插图,讨论了索引过程和检索过程,并展示了提议的Light RAG框架的整体架构。该页面还包含了其他信息,特别是数学公式,它们本质上也解释了相同的概念。
原文是这样的

这里是这个视觉RAG系统回答的翻译版本:

生成的响应是:“该图像展示了Light RAG框架的全面概述,该框架旨在增强信息检索系统的性能和效率。”然后它讨论了不同的组件,包括数据索引器和数据检索器。
这些信息似乎来自图像本身或图像所在页面上的文本。描述可以做得更好一些,可能90B版本的模型会做得更好。
我在这里补充它回答后续的截图:

此外,这些视觉开源大模型往往也可以用于一些视频帧的分析的场景。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 4601
4601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









