



之前一直使用开源的模型进行简单微调,并没有亲自训练过大模型。因此参考了一些github代码和文章,踩一踩训练大模型的坑。
虽说是训练大模型,但也就几百兆的参数量,主打一个流程体验。。。
1、LLM训练代码
参考(直接拉下来用)baby-llama2-chinese的训练方法。
相关文章:limzero:从头训练一个迷你中文版Llama2–一个小项目踏上LLM之旅
首先拉取数据进行数据整理
进行预训练
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --use_env pretrain.py
微调
CUDA_VISIBLE_DEVICES=0 python sft.py
2、模型分析
本人服务器使用的4090,内存24G。使用代码中默认的模型参数内存会爆,因此修改了模型参数。
dim: 512
n_layers: 8
n_heads: 8
此时模型结构为
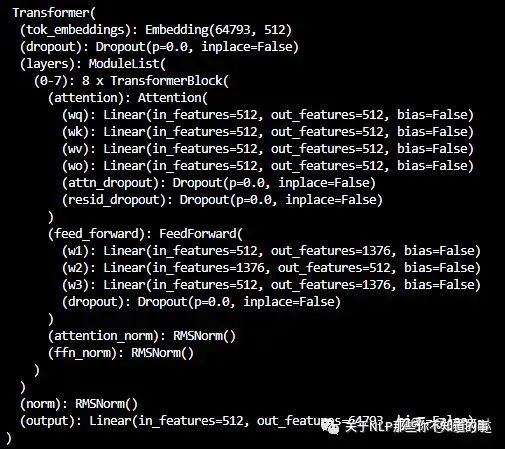
模型结构
模型参数量—预训练GPU内存分析
模型参数量(其中tok_embeddings和output的权重参数相同,只算一个即可)
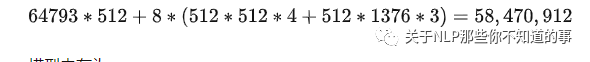
模型内存为
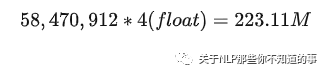
模型训练使用了AdamW优化器,训练总共所需内存为
模型状态
- 模型权重:fp32精度:58,470,912*4 bytes(float) = 223.11M
- 模型权重更新梯度:fp32精度:58,470,912*4 bytes = 223.11M
- AdamW优化器内存(存储两部分的优化器状态:time averaged momentum(动量估计)和variance of the gradients(梯度方差)):58,470,912**4 bytes(float)**2=446.22M
中间激活值:
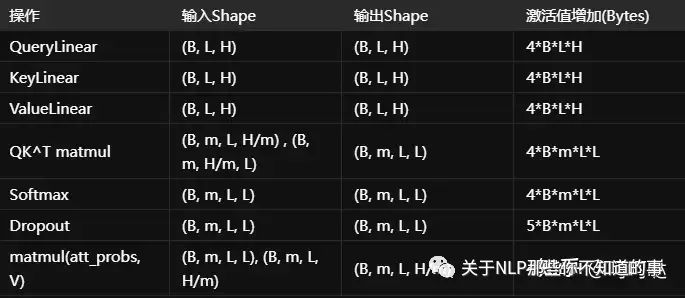
attention激活值
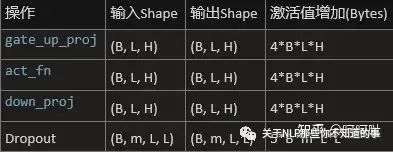
FFn激活值
Batch_size为1时,占用内存大小为
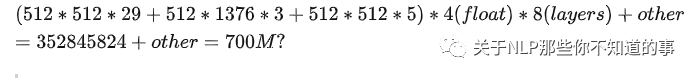
参考Connolly:Self Attention 固定激活值显存分析与优化及PyTorch实现
参考:宋鸣:LLM模型训练的内存消耗
GPU初始化会占用内存800M(任意变量to(‘cuda’),GPU显示内存为变量内存+800M左右,这个不同显卡占用大小并不相同)
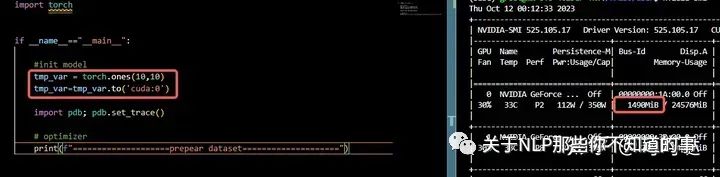
3090服务器上GPU初始化内存占用1400M左右
因此当batch_size为1时,GPU内存消耗如下所示。

实际运行消耗如下图所示(大概符合)
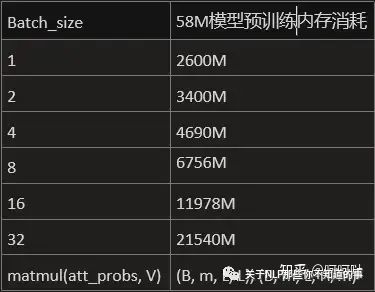
因此对于24G内存的显卡,使用 dim:512,layers:8,heads:8,batchsize:32,是比较合适的选择(batchsize太小效果不好,太大内存不够)。
layers/head_nums数量对内存影响
使用 dim:512,layers:8,heads:8,batchsize:32, 参数,测试layer数目对参数的影响
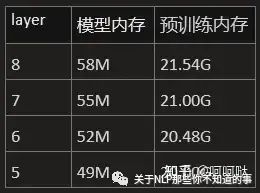
每个layer影响3M的模型内存,影响500M的预训练内存。
head_nums对模型权重基本没有影响。
(因为attention本身权重在整个模型权重所占的比例并不高,大头是tok_embeddings权重*)*
hidden_dims数量对内存影响
使用 layers:8,heads:8,batchsize:32 参数,测试layer数目对参数的影响
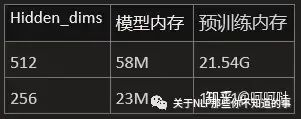
hidden_dims对模型参数量影响极大。对预训练内存也有较大影响。
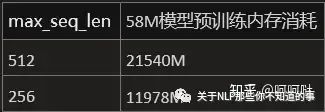
max_seq_len对内存影响
max_seq_len参数不影响模型内存,影响中间激活值内存。
当前的max_seq_len默认为512,若修改为256,则训练内存几乎减半。
注意:模型预训练和微调时加载的数据大小会有差异,比如baby-llama2-chinese的SFTDataset比PretainDataset多了loss_mask参数(可以去除),同样大小的模型,pretain阶段内存刚好够用,但sft阶段内存就不够了。建议先减少训练数据,快速将整个流程跑通,测试参数的合理性。
耗时估计
确定模型参数后,便可读取数据进行预训练。当前使用了3.8547B个token,数据内存7.7G。
若seq_len=512, batch_size为32,则需要迭代
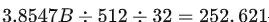 次
次
3.8547�÷512÷32=252,621次
根据每一次迭代的耗时,即可推算出整个预训练耗时。
使用4090单卡预训练1个epoch大概需要600min。
4卡同时训练大概150min≈2.5h
微调模型数据为25091条,每个epoch耗时30min左右。
注意:大语言模型由于训练时间较长,因此建议每个epoch都保存一下权重,且可以通过nohup进行后台挂起,以防止ssh远程时,主机重启导致ssh断开程序中止的问题。
tokenizer模型
tokenizer模型采用了ChatGLM2的分词模型,也可以自己根据词表重新训练。
参考:https://github.com/yanqiangmiffy/how-to-train-tokenizer
GitHub - bojone/bytepiece: 更纯粹、更高压缩率的Tokenizer
BytePiece:更纯粹、更高压缩率的Tokenizer - 科学空间|Scientific Spaces
3、模型训练+微调+评估
预训练
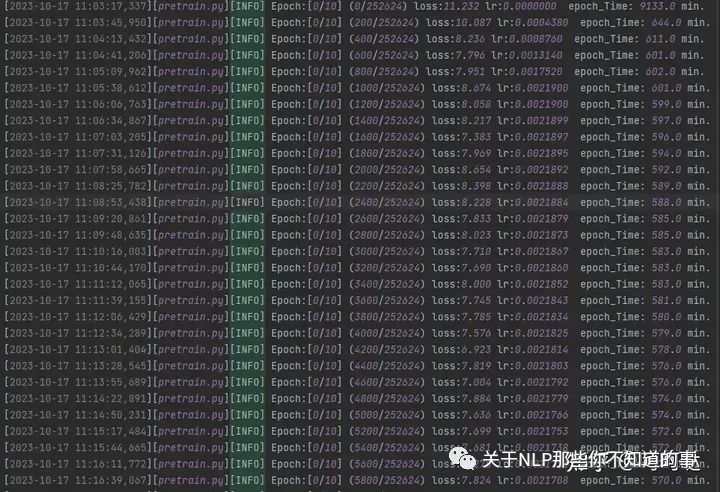
pretrain log
微调模型,评测模型的效果。
当前工程中有eval.py,运行可以针对目标数据集进行推理,将推理结果和数据集答案计算BLEU score,根据得分评估质量。
也可以参考lm-evaluation-harness项目评测模型质量
参考文档:呵呵哒:LLM模型评测代码实践
Loss判断
首先当batch_size=32,gradient_accumulation_steps=1、2、4、8时
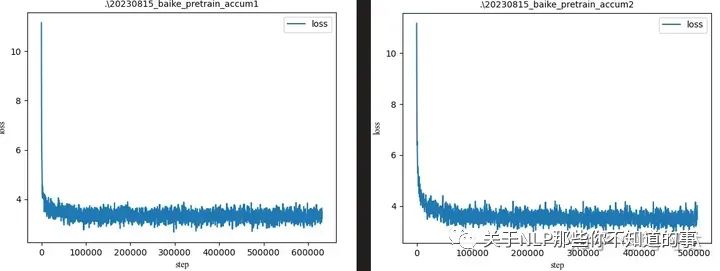
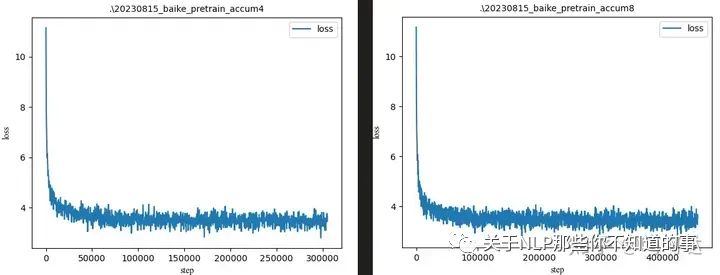
可以看出模型在迭代30000次左右,还没有训练完成1个epoch(120000)时,loss便已经趋于稳定。
对上面预训练的模型进行微调,可得到如下结果
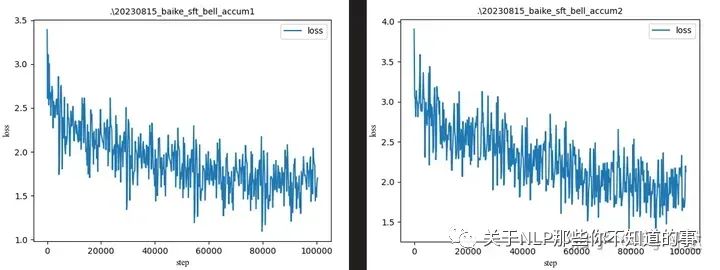
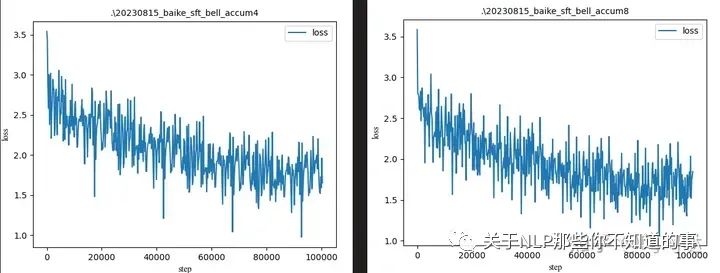
用高质量数据微调后,loss有一定程度下降。
评估指标判断
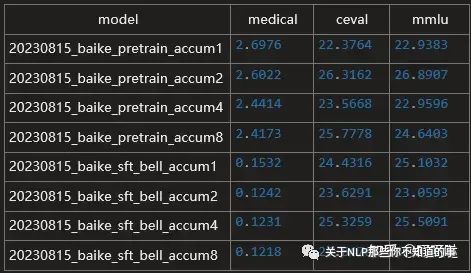
可以看出模型的medical数据评估得分较低。ceval和mmlu虽然都在25左右,但由于这两个测试集是选择题,即使随便蒙平均也有25%的正确率,因此25分左右可认为没有什么回答能力。
估计模型的参数量太低也占据部分原因,考虑采用更大的参数量重新训练。
4、模型参数扩增
由于模型的参数量太低,导致LLM训练无法出现涌现现象,考虑增大参数量。经过测试后,模型参数确定为
max_seq_len: 1024
dim: 1024
n_layers: 24
n_heads: 32
参数量为369,910,784。模型大小为1.38G。
由于参数量增加,在显卡内存不变的情况下,batch_size只能减小,设置为4,此时预训练占用显卡内存20G。(24G内存无法支持更大的batch_size)
参考GPT3和LLaMA的介绍,batch_size通常设置在0.5M~4M。
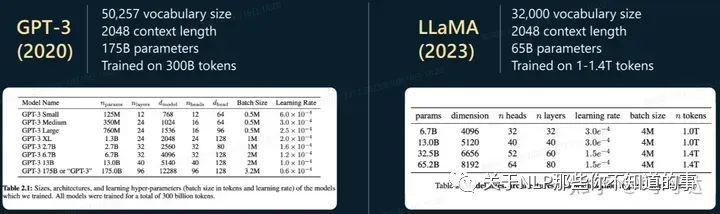
因此gradient_accumulation_steps增大为64,这样总batch_size等同于4x4x64=1024。
四卡同时训练10个epoch,单个epoch耗时在10个小时左右。
质量评估
从loss上看出,最终loss基本稳定在3上下波动。
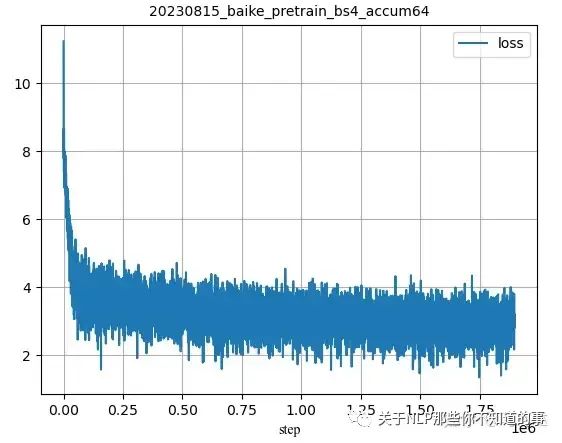
评估结果可以看到评分更低了。。。
Ceval_eval_scores: 21.9298
MMLU_eval_scores: 22.9454
针对每个spoch结果进行测评得

多个epoch的模型相比,基本上没有什么区别,且都效果很差。(/(ㄒoㄒ)/~~)
不过基模型不善于问题也是正常。
针对不同epoch的模型进行微调,可以得到评测结果如下所示

微调结果也不好。
5、flash-attention优化
首先统计当前模型训练时每推理一次的平均耗时为0.133s左右。
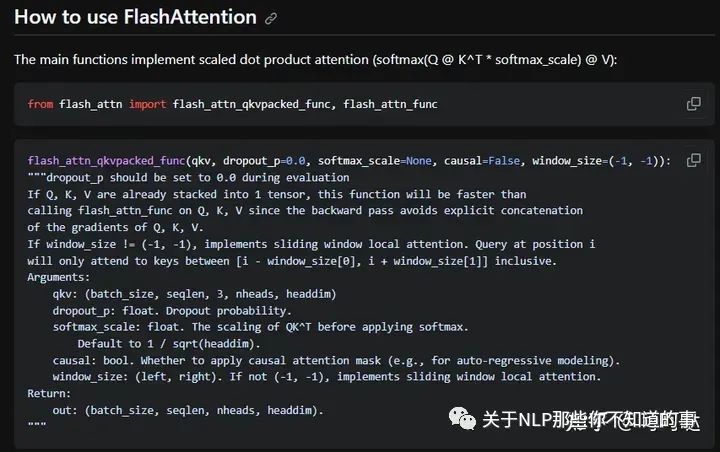
从github链接下载flash-attention代码,并进行安装。
GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attentiongithub.com/Dao-AILab/flash-attention
官方使用教程如下图所示
在要替换的项目代码中查找attention计算部分
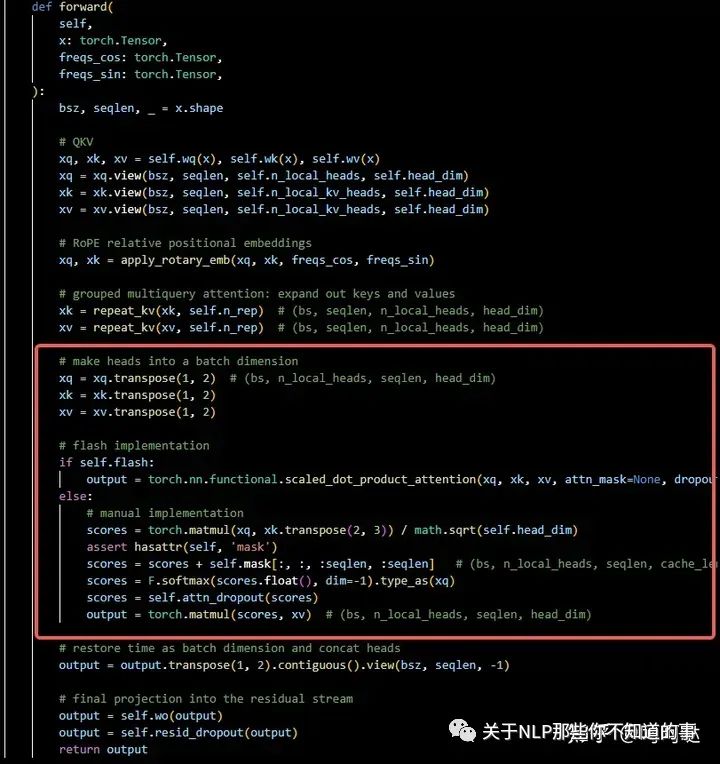
attention计算过程
修改如下(—需要设置causal=True—)
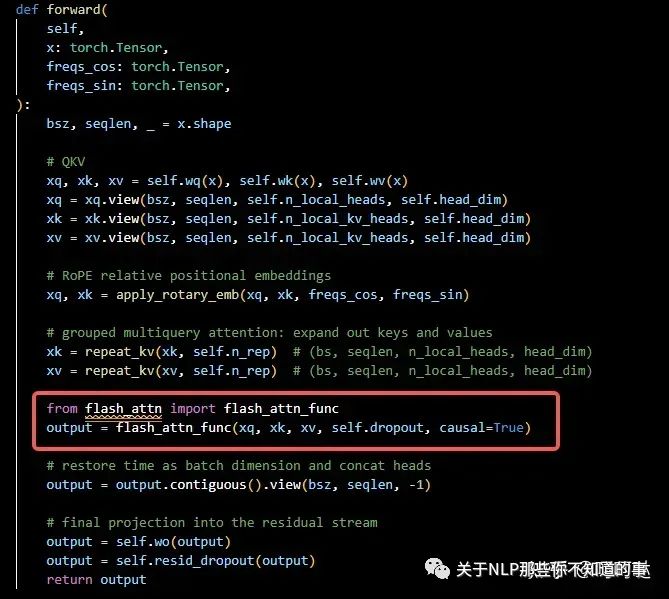
或者
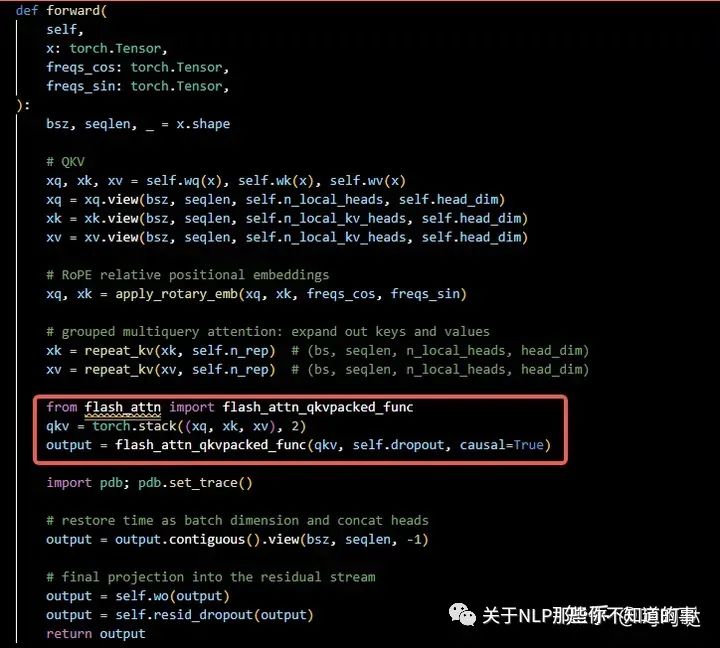
对比计算结果,修改前后的output结果值完全相同,表明修改正确。
几种计算方式的耗时对比如下表所示
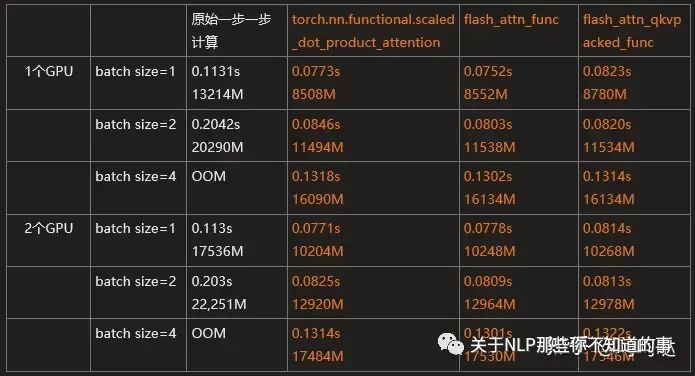
torch.nn.functional.scaled_dot_product_attention()确实比一步一步手动计算要快,且省内存。
但和flash_attn_func()、flash_attn_qkvpacked_func()相比,耗时和内存基本相差无几。。。/(ㄒoㄒ)/~~

考虑到可能是由于batchsize太小,没有明显区别。
因此将模型参数量减少,增大batch size=64/128。
dim: 256
n_layers: 8
n_heads: 8
max_seq_len: 256
torch.nn.functional.scaled_dot_product_attention()和flash_attn_func()耗时也几乎完全相同。
在batch size=1时,几乎没有差别。在batchsize=4时,flash_attn_func大概快了1.5%。
估计是batch size和seq_lens不够大,越大应该越能表现出flash-attention的优势。
6、MQA、GQA优化
一张图简单理解,就是多个heads之间共用KV权重的程度
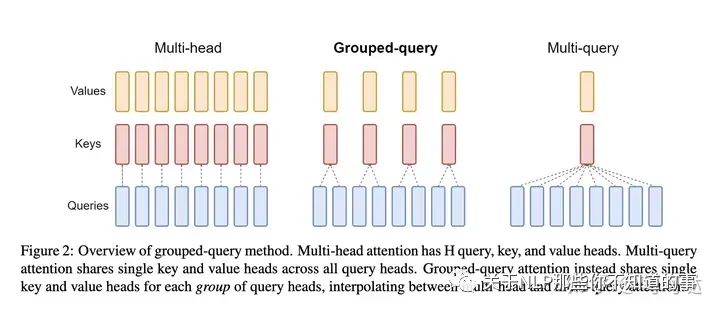
代码中就是在创建kv线性层的时候将输出层的数量设置为对应的head_num*dims

其中模型参数减少 (�ℎ����−���ℎ����)∗����∗2∗������
对于heads=32,layer=24,dims=1024的模型来说,参数量从369,950,720减少至321,191,936,降低了13.2%
耗时从0.128s减少至0.116s,降低了9.37%
很多地方会说使用了MQA和GQA时,kv结果的维度减小,需要repeat_kv到和q一样的维度

其中
self.n_rep = self.n_heads // self.n_kv_heads
其实从结果上看没有必要。测试也能看出结果完全一摸一样(模型参数不变,内存消耗不变,运行时间也影响极小)。
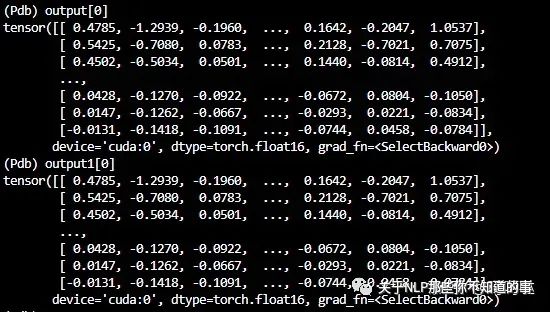
但是如果不加repeat_kv(),训练时会报错。
待补充一个性能对比测试。。。
总结
1、模型参数量足够大。根据GPU显存确定合适的模型参数量(在训练充分的情况下,参数量越大肯定质量越好,batch size可以设置的比较小,通过设置较大的gradient_accumulation_steps,达到类似的效果。 但是gradient_accumulation_steps不能太大,不然loss很容易飞)。
2、数据集数量足够多。 至少要有足够量的数据才能保证模型训练效果(1B的模型至少10B的训练数据吧,训练数据越多越好)
3、数据集质量足够好。 数据质量决定了模型的质量,尤其是微调数据集的质量,一定要比较高。考虑用现成的或者自己洗数据。
4、足够大的batch size。 一般设置为1M以上。
5、只需要训练1个epoch 。LLaMA2和PaLM都只训练了1个epoch,多epoch对模型效果并没有多大作用?!!从loss曲线也可以看出在数据量足够大的时候,1个epoch还没有跑到一半,loss就趋向于稳定了。
参考:tokens危机到来怎么办?新国立最新研究:为什么当前的大语言模型的训练都是1次epoch?多epochs是否会降低大模型性能?
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









