




1. 前言
在大语言模型的训练过程中,偏好对齐是一项至关重要的任务,它能够更好地帮助语言模型的输出与人类的喜好进行对齐。目前,开源界的许多项目已经实现了基于偏好数据的 Reward Model、 DPO(Direct Preference Optimization)及 DPO 的衍生方法的训练,然而,这些方案普遍存在一个显著的问题——显存浪费。
为什么会出现显存浪费的现象呢?这是由于在偏好训练的一次迭代中,需要至少包含 chosen 和 rejected 两个样本对。这两个样本对的长度往往存在差异,因此在组合这两个样本的时候,必须对短的样本进行补零(Padding),而这些补零的 token,都是被浪费的计算量!我们统计了目前使用范围最广的偏好对齐数据集 UltraFeedback,如果按 batch size=1 进行补零,则有 14.61% 的 token 是无意义的 padding token,而如果想把显存拉满而增大 batch size,则 padding 的 token 数量会显著增加,当 batch size=8 时 padding 占比居然已经超过了 50%!由此可见,偏好训练的过程中有大量的计算资源被浪费了****!
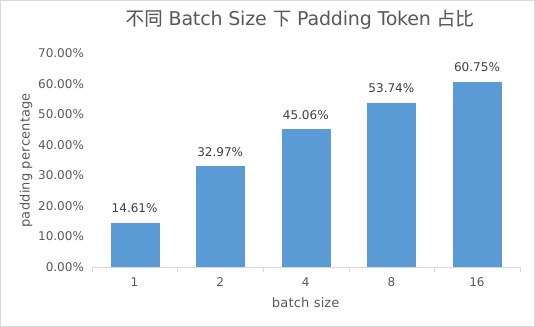
padding token 占比随着 batch size 增大而显著增加
2. 零显存浪费
为了解决这一问题,XTuner 首次开源了零显存浪费的偏好对齐训练方案!
https://github.com/InternLM/xtuner
那么,这是如何做到的呢?这就不得不提到大语言模型中常用的数据拼接(pack)技巧,数据拼接通过将不同的序列拼接为一个一维序列作为模型的输入,从而避免的组 batch 时的 padding,这样的训练方式在预训练与 SFT 中已经广泛使用。但是在偏好数据的训练的过程中使用该方法却存在一个问题,那就是注意力泄露。在 DPO 以及其他偏好训练的过程中,必须要求 chosen 和 rejected 两条样本是互相看不见的,如果只是简单将两条数据拼接,那么拼在后面的样本中的 token 的注意力会“看到”前面样本的 token,破坏了偏好训练的过程。这就要求我们对两条样本的 attention 进行魔改,避免两个样本互相之间能看到对方。
可惜 HuggingFace 的 transformers 中实现的语言模型并没有提供这样的接口!这也就是为什么目前没有开源项目能够支持数据拼接的方式进行偏好对齐训练。不过,XTuner 自有妙招**!**我们通过给模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4958
4958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









