




介绍
BGE全称是BAAI General Embedding,即北京智源人工智能研究院通用Embedding模型,它可以将任意文本映射到低维的稠密向量,在文本向量化任务中得到了广泛的应用。可以看到在C-MTEB中文排行榜中,BGE系列模型的综合能力名列前茅,而在MTEB排行榜所有小于500MB的模型列表中,基于相同模型结构的BGE英文版本bge-large-en-v1.5的综合能力也能位列前五。
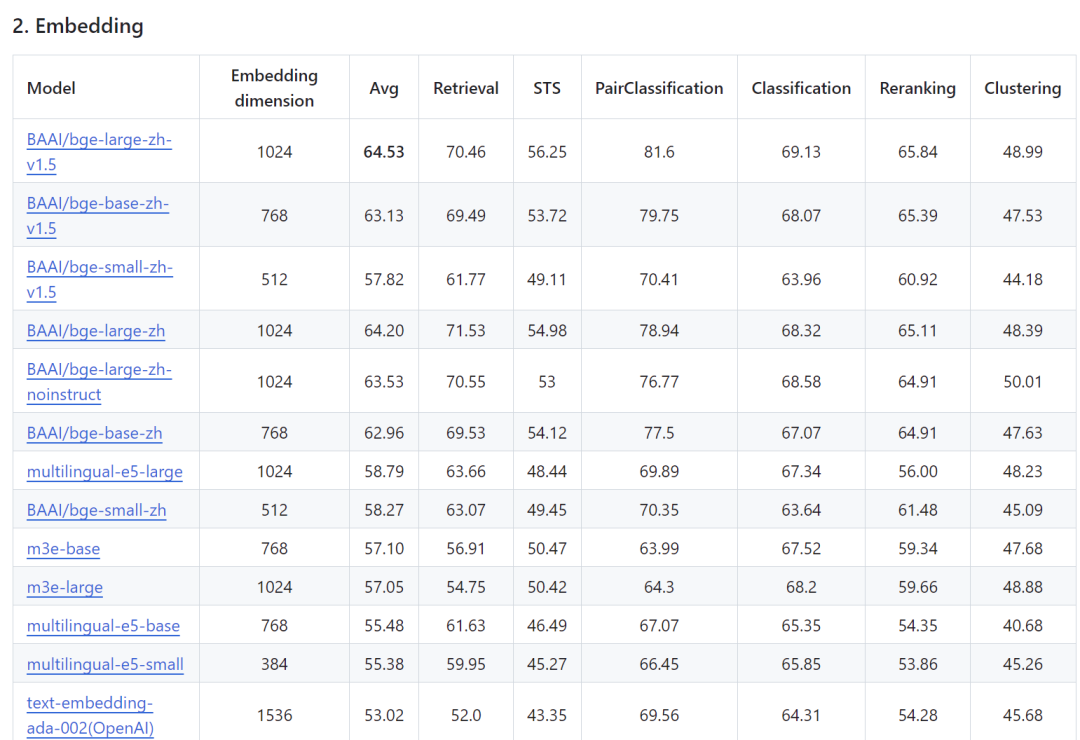
图:BGE模型性能指标
而作为英特尔AIPC架构中专用的AI处理器,NPU相较于CPU拥有更高的算力,并能以更低的能耗来运行深度学习模型。在类似RAG等的复杂任务中,我们往往需要利用Embedding, LLM, Ranker等多个模型协同处理数据,通过将Embedding模型部署在NPU上,可以进一步优化其性能和能耗。OpenVINO™作为目前唯一可以同时在Intel CPU, GPU以及NPU平台上部署AI模型的工具套件,提供了一套通用API接口函数,方便开发者灵活地调度AIPC上的异构资源。本文将分享如何利用 OpenVINO™ 工具套件在NPU上部署BGE Embedding模型。
示例完整代码: https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-rag-langchain
OpenVINO™
模型转换
利用Optimum-intel命令行工具,我们便可以非常快速将BGE embedding模型导出为 OpenVINO™ 的IR格式文件。这里只需要指定模型的Hugging Face ID或是本地路径,以及任务类别为feature-extraction。
optimum-cli export openvino --model bge-large-zh-v1.5 --task feature-extraction bge-small-zh-v1.5
当以上命令执行完毕后,IR格式模型以及对应的tokenizer文件将被保存在bge-large-zh-v1.5目录下:
├── config.json
├── openvino_model.bin
├── openvino_model.xml
├── special_tokens_map.json
├── tokenizer_config.json
├── tokenizer.json
└── vocab.txt
由于 NPU 中的所有数据都将被转到到 fp16 精度进行计算,而 BGE Embedding 模型的原始精度是FP32,因此在FP32转FP16的过程中部分超过FP16表达范围的值会溢出,例如一个极小的负数,BGE Embedding也同样存在这个问题,所以这里我们会将这种类型的 Tensor 利用 OpenVINO™ 的 Transformation
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









