




“ 本地知识库就相当于大模型的外部资料库。”
很多人应该都听过本地知识库项目,它是当今人工智能领域爆火的项目之一,那么到底什么是本地知识库?它和大模型有什么关系?怎么构建本地知识库?
01、为什么需要本地知识库?
其实本地知识库和大模型本身没有什么直接关系,可以说它们是两个完全独立的技术。
但因为大模型的幻觉问题和大模型的数据更新迟缓,因此才把知识库技术与大模型技术相结合,产生了大模型知识库技术。
什么是知识库?
知识库简单来说就是资料库,比如国家图书馆收录了我国几千年来的历史书籍和资料;每家企业都会有一些内部数据;各个领域都有自己领域内的数据和资料。
而怎么管理这些资料和数据,就是知识库技术,知识库的核心有两点,一是数据的存储,二是数据的检索。
在互联网技术出现之前,知识库都是以档案室或资料室的形式存在;而计算机技术出现之后,特别是大数据技术出现之后,知识库就可以从线下走到了线上。
而大数据技术也为处理大量复杂数据提供了可能。

大模型技术是当前人工智能领域爆火的技术之一,但它有一个致命的缺陷就是,它的训练数据是有时间限制的,比如chatGPT的数据还是两年前的,它对近两年的情况就什么都不知道了。
解决这个问题其实有多种方式,比如用最新的数据对大模型进行重新训练,或者使用微调技术比如lora,用最新的数据进行微调。
但这两种方式一来成本太高,二来门槛太高,对很多小公司是不可接受的。其次就是,哪怕重新训练出来的大模型,在一些垂直领域的问题上经常会出现“幻觉”问题。
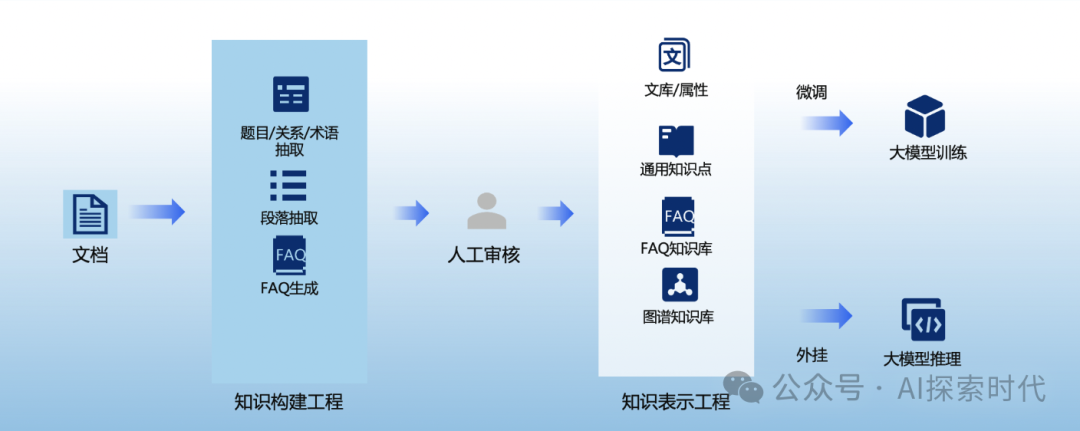
所以,大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









